 This page is under construction
This page is under construction
Power outage time-line.
[Tentative proposal] This power outage will affect substations #7 (next to bldg 50) and #8 (located on the 4th floor of bldg 50). All of bldg 50 will be without normal power. The facilities (F&O) group plan to do their maintenance during the 4-day period starting 26 Dec 2019. However, the outage will start earlier due to lack of staff during the holiday shutdown. Minimally, it is expected that all H.A. (High Availability) and experiment-critical equipment will be powered throughout the 16+ days of the holiday shutdown. This page captures what Fermi will need to maintain a minimal data processing effort running during the outage.
Note that the ability to perform general science analysis at SLAC by the LAT collaboration will be seriously hindered by this outage due to the fact that much of the batch farm will be unavailable.
| Date | Time | Equipment * | Action |
|---|---|---|---|
| Fri 20 Dec 2019 | TBA | switch to generator power (this could happen earlier) This will require a several-hour outage | |
| Mon 6 Jan 2020 | return to normal power. This will require a several-hour outage |
Outage preparation task list
Define needed xrootd resources (Wilko Kroeger)
Confirm sufficient xrootd space to handle 16+ day HPSS outage (Wilko Kroeger)
- Define needed Level 0 and half-pipe resources (Steve Tether)
- Define needed Level 1 resources (Tom Stephens)
- Update service → VM → hypervisor host mapping (Brian Van Klaveren)
- Suggest/Move non-HA VMs to HA (Brian Van Klaveren)
- Define needed ASP resources (Jim Chiang)
- Define needed resources for critical Fermi Science pipelines (various)
- Gravitational wave analysis (Nicola Omodei)
- Flare Advocates (Gulli Johannesson, Stefano Ciprini)
- Burst Analysis (Dan Kocevski)
THE FOLLOWING DATA IS IN PROCESS OF BEING UPDATED FOR DEC 2019 OUTAGE
LISOC Operations Functions
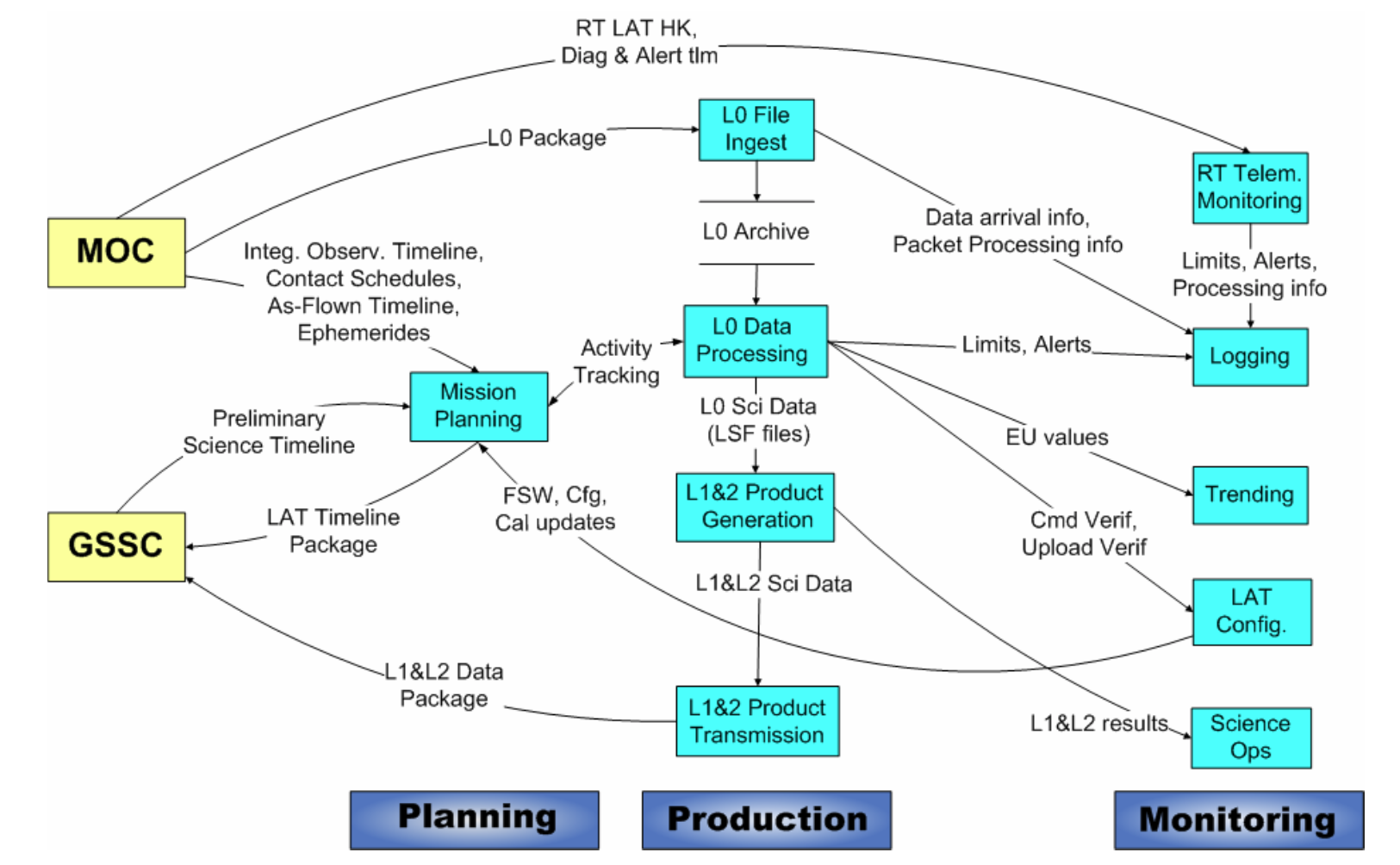
Table of LISOC Tasks and Services
| Function/Service | Sub-Functions | Needed Servers | Needed Databases | Needed File Systems | Other Needs | Needed During Shutdown? | Available During Shutdown? |
|---|---|---|---|---|---|---|---|
| Mission Planning, LAT Configurations | FastCopy | fermilnx01 and | TCDB | AFS | Fermi LAT Portal: Timeline Webview; Confluence, JIRA, Mission Planning s/w, FastCopy Monitoring Sharepoint (reference for PROCs and Narrative Procedures for commanding in case of anomalies) | yes | |
| Real Time Telemetry Monitoring | fermilnx01 and fermilnx02 | spread Fermi LAT Portal: Real Time Telemetry, Telemetry Monitor | during anomalies | ||||
| Logging | fermilnx01 and fermilnx02 | TCDB | Fermi LAT Portal: Log Watcher | yes | |||
| Trending | TCDB | Fermi LAT Portal: Telemetry Trending | yes | ||||
| L0 File Ingest and Archive | FastCopy | L0 Archive | yes | ||||
| Data Gap Checking and Reporting | FastCopy | fermilnx01 and fermilnx02 | L0 Archive | yes, continuously | |||
| L1 processing | pipeline | SLAC Farm | Data Catalog | Fermi LAT Portal: Pipeline, Data Processing | yes | ||
| L1 Data Quality Monitoring | Fermi LAT Portal, Telemetry Trending | ||||||
| L1 delivery | FastCopy | fermilnx01 and fermilnx02 | Data Catalog | yes | |||
| L2 processing (ASP) and Delivery | FastCopy | fermilnx01 and fermilnx02 | Data Catalog | Fermi LAT Portal: Pipeline, Data Processing | daily, weekly |
The following table of servers must remain powered up and operational for Fermi Level 1 and critical Science Pipelines to function.
Fermi has requested that all VMs be relocated (at least temporarily) to the two H.A. hypervisor machines, thus some of the tasks listed below are no longer relevant.
- Confirm current H.A. rack occupants. spreadsheet from Christian Pama
Old (2017) spreadsheet here - Confirm the VM-master for a given VM. Use the 'node' command, e.g., $ node -whereis fermilnx-v12 (obsolete)
- Confirm the tomcat <-> service associations. Table here.
- Confirm the tomcat-VM associations in this table. Use the 'node' command, e.g., $ node -whereis glast-tomcat01
NOTE: Fermi has four VMware hypervisors, each of which contain some number of VMs running Fermi services. Two of these hypervisor machines are in the H.A. racks (fermi-vmclust03/04), while the others (fermi-vmclust01/02) are not. At this writing there are no user-level tools to allow one to discover which VMs are running on which hypervisor machines.
| Category† | server | VM/service | function |
|---|---|---|---|
| XC | fermi-gpfs01 fermi-gpfs02 fermi-gpfs05 fermi-gpfs06 fermi-gpfs07 fermi-gpfs08 | xrootd server and storage | |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v02 | xrootd redirector |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v12 | xrootd redirector |
| XC | fermi-gpfs03 fermi-gpfs04 | GPFS | Fermi NFS/GPFS storage |
| XC | fermi-cnfs01 fermi-cnfs02 | GPFS/NFS bridge | Fermi NFS storage access |
| HA | staas-gpfs50 staas-gpfs51 | Critical ISOC NFS storage | |
| HA | fermilnx01 | LAT config, fastcopy and real-time telemetry | |
| HA | fermilnx02 | LAT config, fastcopy and real-time telemetry | |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v03 | archiver |
| HA | fermi-oracle03 | oracle primary | |
| XC | fermi-oracle04 | oracle secondary | |
| HA | mysql05 mysql06 | mysql-node03 | calibration, etc. DB |
| XC | 400 cores | (50 "hequ" equivalents) batch hosts for LISOC queues={express,short,medium,long,glastdataq} users={glast,lsstsim,lsstprod,glastmc,glastraw} | |
| XC | 200 cores | (25 "hequ" equivalents) batch hosts for Science Pipelines | |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v07/tomcat01 | Commons, Group manager |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v16/tomcat06 | rm2 |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v05/tomcat08 | dataCatalog |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v17/tomcat09 | Pipeline-II |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v15/pipeline-mail01 | Pipeline-II email server |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v18/tomcat10 | FCWebView, ISOCLogging, MPWebView TelemetryMonitor, TelemetryTableWebUI |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v10/tomcat11 | DataProcessing |
| XC/HA | fermi-vmclust01/02/03/04 | fermilnx-v11/tomcat12 | TelemetryTrending |
| NC | (non-Fermi server) | astore-new (HPSS) | FastCopy data archive **We have arranged a temporary quota increase of 1 TB on /nfs/farm/g/glast/u23, which has allowed this item to become "NC"** |
| HA | (non-Fermi server) | trscron | tokenized cron |
| HA | (non-Fermi server) | lnxcron | cron |
| XC | (non-Fermi server) | (farm manager, etc.) | LSF management |
| HA | yfs01/NN (non-Fermi) | basically all of AFS | |
| HA | (non-Fermi server) | JIRA | issue tracking (HA as of 10/20/2017) |
† Equipment categories
Category | Machine status |
|---|---|
| NC | non-critical for entire 16-day shutdown period |
| XC | experiment critical but not in H.A. rack, only a few, short outages acceptable |
| HA | high-availability (continuous operation) |
Total non-HA machines to receive emergency power:
| Machine Type | Total |
|---|---|
| GPFS servers | 8 |
| NFS/GPFS bridge | 2 |
| VMware hypervisors | 2 |
| batch nodes ("hequ" equivalents) | 75 |
| Oracle servers | 1 |
| TOTAL | 88 |
Note that HPSS is NOT required by Fermi.
The services for L1:
oracle
- pipeline
- data catalog
- group manager
mysql
- calibrations
tomcats
- pipeline
- data catalog
- data processing
isoc servers
xroot
The following servers are needed to allow processing of new data (older data on fermi-xrd or HPSS will not be available):
- fermi-gpfs01/02, fermi-gpfs05/06 and fermi-gpfs07/08
These are the servers that make up the fermi xrootd gpfs space. Each pair servers a part of the total gpfs space.- fermi-gpfs05 runs the xrootd server for the gpfs space
- fermilnx-v02 (redirector)
- fermilnx-v12 (redirector)
nfs
- Pretty much everything that's currently on staas-gpfs50/51
- Parts of the non-HA Fermi NFS file system
LSF
- 50 hosts should let us keep up (inlcuding ASP)
Here's what ISOC tasks need:
FASTCopy chain
--------------
staas-gpfs50/51
fermilnx01
fermilnx02
trscron
fermilnx-v03 (Archiver)
Whatever the pipeline server runs on.
xroot servers
astore-new system (HPSS)
Web servers
-----------
tomcat01 Commons
tomcat06 rm2
tomcat09 Pipeline-II
tomcat10 FCWebView, ISOCLogging, MPWebView
TelemetryMonitor, TelemetryTableWebUI
tomcat11 DataProcessing
tomcat12 TelemetryTrending
Science Pipelines
Gravitational Wave analysis (Nicola)
- Runs once per GW event reported from Global GW detectors
- Large variability in CPU requirement due to varying size of GW localization in sky
- Estimate 300 core-hours per day per GW event
→This would be 4 hequ hosts for about 10 hours per GW event
Flare Advocate analysis
- Batch jobs submitted to follow up on flare alert
Burst Analysis
- Batch job(s) submitted to follow up on gamma-ray burst detection
- Six jobs/burst, medium queue, rhel6
- Recent 7-day week had 11 triggers, so >1/day
→Six hequ batch nodes should cover this need
FAVA (Fermi All-Sky Variability Analysis)
- Runs weekly
- Could postpone routine FAVA analysis until after the outage
High availability racks
For general information about the High-availability racks, Shirley provided this pointer to the latest list:
"Service Now, Knowledge Base, search for "High Availability" , following link for current servers"
And here is the current statement about high-availability functionality:
Current Services in HA Racks •CATER application •Confluence application •Data center management tool •Drupal web •Email lists •Email transport infrastructure •ERP application •Exchange email •EXO application •Facilities monitoring •Fermi application •IT Ticketing system •Network infrastructure •Site Security infrastructure •Unix authentication infrastructure •Unix AFS infrastructure •Unix mailboxes •Unix monitoring •VPN •Windows authentication infrastructure •Windows file servers and SAN •Windows monitoring •Windows web
Supporting documentation
Email from Steve Tether with some storage-related information:
Wilko's statement regarding space currently available in xrootd:
Nicola's estimate of batch power needed for GW follow up pipeline:
Stefano's comment on Flare Advocates:
Sara's response to Flare advocate script question:
Teddy adds: "The FA scripts tend to be run each day at most."
Dan's statement on various Pipelines (including FAVA):
Brian's proposal to move all VMs to H.A.:
Juliyana's report on VMs in H.A.:
Excerpt from Christian Pama's spreadsheet on H.A. rack contents:
Current tomcat server VMs:
Other VM's:
Gotchas from the Dec 2017 outage
- We did not specify the "medium" LSF queue in our requirements, but ended up needing it
- There was a delay in getting all 50 hequ's operating (some were/are on H.A., but others are not)
- The xrootd redirector had a problem and needed a restart