Author: Unknown User (mattlangston)
Version Numbers Now Supported
Version numbers have been added to the pipeline XML schema using the familiar and standard GLAST triplet versioning scheme (for example v4r2p8). There are now three optional attributes available for the top-level <pipeline> element: "version", "revision" and "patch". See the example below.
Introduction
This document describes the XML file format for configuring processing pipelines that run in the GINO Pipeline. The outline of this document is as follows. First, detailed step-by-step instructions are provided that describe how to write a pipeline configuration by hand. Next, an example configuration file is shown based on the recon-EM2-v1r0 pipeline. Finally, all of the constant values that appear in various places in a configuration file are described in a set of tables.
The intended audience for this file format are users who write pipeline configurations by hand and chose to upload them using the GINO Web Application.
Uploading a Configuration File
This is a screenshot of the GINO Web Application. Notice that you can upload pipeline configurations to production, development and test GINO servers. When you upload a pipeline, it replaces (overwrites) a pipeline in the server with the same name if it exists. This is a convenient way to edit your pipelines. However, you will not be allowed to upload a pipeline configuration once the GINO server has started processing runs.
First, select the server you want to upload your XML configuration file to. The currently selected server is shown in the left navbar next to the main GINO menu. To change the server, click the "Change Server" button:

You will see a screen listing the available GINO servers. Select the one you want and click "Change Server". Your new selection will be show in the left navbar next to the main GINO menu.

Although the XML format for pipeline configurations is straightforward, it is easiest to start with a pre-existing XML file. From the "Configure Pipelines" page it is easy to browse and download XML configuration files for all of GLAST's pipelines. Click "View" next to the pipeline to view the XML configuration file in your browser. Click "Download" to download the XML configuration file in text format for easy editing in your favorite editor.

You must be logged in to upload an XML configuration file. If you are not logged in, you will see "Login" in the left hand navbar. If you are already logged in, you will see "Logout" followed by your user name. You will only see the "Click here to upload a new configuration file" link on the "Configure a Pipeline" page if you are logged in. Click the link (indicated in the screenshot below), to be taken to the page that allows you to browse your local hard drive for a pipeline XML configuration file to upload.

Fromt here, follow these steps to upload your own pipeline XML configuration file:
- Click "Browse...". A file dialog box will open.
- Select your pipeline XML configuration file from your local hard drive. In the screenshot below, select the file in the file dialog box, then click "Open" which will fill the "File to upload" text box with the path to your pipeline XML configuraiton file.
- Click "Upload Configuration File"
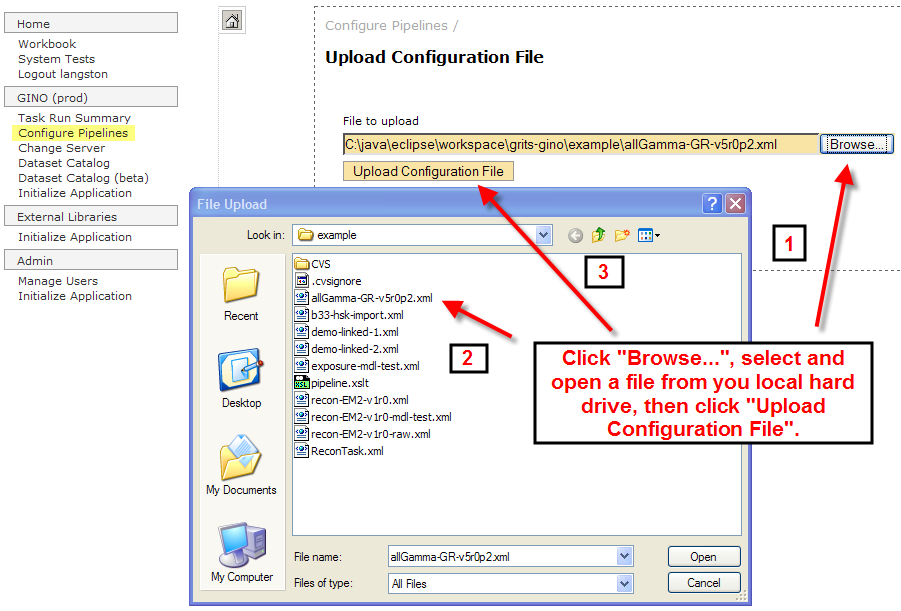
If your upload worked (meaning your XML was well formed and it followed the XSD schema listed below), you will be taken back to the "Configure a Pipeline" screen where your pipeline will now appear in the table alongside the other pipelines for the currently selected server. If your upload didn't work you will see an error message in your browser that is probably incomprehensible. Find me and I will help you determine what the problem is.
How to Define a Pipeline
A GINO Pipeline is defined in an XML file whose format is described by a W3C XML Schema available at http://glast-ground.slac.stanford.edu/pipeline.xsd. This schema will mainly be useful if you use an XML editor that supports W3C XML Schema, which these days includes nearly all modern XML editors.
We recommend using XMLBuddy to edit pipeline XML configuraiton files, and provide XMLBuddy installation instructions. XMLBuddy is free and runs on both Windows and Linux. We recommend it since it uses the XSD Schema from http://glast-ground.slac.stanford.edu/pipeline.xsd to make sure your XML is not only well formed (i.e. does not contain syntax errors), but is also strictly valid according to the XSD Schema. Normal text editors (for example, emacs) can't do this.
Here are the steps you should take to create a configuration file to define a pipeline. The order is important.
- The top-level root element in the configuration file is a pipeline. Define the name, version number (optional; default = 0), revision number (optional; default = 0), patch number (optional; default = 0) and type attributes, and the dataset-base-path and run-log-path elements. The version number, revision number and patch number form the standard GLAST triplet versioning scheme (for example v4r2p8). Since the version numbers are optional, the defult value is v0r0p0. The type attribute must be from a finite set of values which are listed below. The dataset-base-path is simply a convenient prefix for the files you define in step 4.
- Define the list of executables your pipeline will run. This section simply gives a friendly name and a version string (which is used for documentation purposes only) to the long absolute file paths that executables typically have. You refer to these executables by their friendly names in the processing-step elements defined below in step 6.
- Define the batch job configurations your pipeline needs. This section simply gives a friendly name to a batch queue, batch group, a working directory and the directory where the log file will go. You refer to these batch job configurations by their friendly names in the processing-step elements defined below in step 6. The queue and group attributes must be from a finite set of values which are listed below.
- Define the list of files your pipeline is concerned with using file elements. This section simply gives friendly names to long file paths and defines some meta-information about the files. You refer to these files by their friendly names in the processing-step elements defined below in step 6. The type and file-type attributes must be from a finite set of values which are listed below. The file paths are directories that are relative to dataset-base-path defined in step 1.
- Define the list of input files from other pipelines that you want to use as input to your pipeline using foreign-input-file elements. This section simply gives friendly names to files produced by other pipelines (hence the name "foreign"). You refer to these files by their friendly names in the processing-step elements defined below in step 6. The pipeline attribute specifies the name of the pipeline that produced the file you want to use as input. The file attribute specifies the name given to the file in the "foreign" pipeline (this is the names used in step 4).
- Finally, define the processing steps of your pipeline. Each processing-step in this section refers to the executable defined in step 2 (via the executable attribute), the batch job configuration defined in step 3 (via the batch-job-configuration attribute), and the list of input files and output files (which you defined in steps 4 and 5) in the list of input-file and output-file elements. You can refer to both the file elements defined in step 4, or the foreign-input-file elements defined in step 5.
Example Configuration File
Here is an example pipeline configuration file for the recon-EM2-v1r0 pipeline.
<?xml version="1.0" encoding="UTF-8"?>
<pipeline
xmlns="http://glast-ground.slac.stanford.edu/pipeline"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://glast-ground.slac.stanford.edu/pipeline http://glast-ground.slac.stanford.edu/pipeline.xsd"
version="4" revision="2" patch="8">
<name>recon-EM2-v1r0</name>
<type>Reconstruction</type>
<dataset-base-path>/nfs/farm/g/glast/u12/EM2/rootData/$(RUN_NAME)</dataset-base-path>
<run-log-path>/temp/</run-log-path>
<executable name="reconWrapper" version="v1r0">
/nfs/slac/g/svac/common/pipeline/EM2/svacPipeline/recon/v1r0/reconWrapper.pl
</executable>
<executable name="RunRALaunchWrapper" version="v1r0">
/nfs/slac/g/svac/common/pipeline/EM2/svacPipeline/recon/v1r0/RunRALaunchWrapper.pl
</executable>
<executable name="genRTRLaunchWrapper" version="v1r0">
/nfs/slac/g/svac/common/pipeline/EM2/svacPipeline/recon/v1r0/genRTRLaunchWrapper.pl
</executable>
<executable name="urlWrapper" version="v1r0">
/nfs/slac/g/svac/common/pipeline/EM2/svacPipeline/lib/urlWrapper.pl
</executable>
<batch-job-configuration name="long-job" queue="long">
<working-directory>/nfs/farm/g/glast/u12/EM2/log/$(RUN_NAME)</working-directory>
<log-file-path>/nfs/farm/g/glast/u12/EM2/rootData/$(RUN_NAME)/calib-v1r0/grRoot</log-file-path>
</batch-job-configuration>
<batch-job-configuration name="short-job" queue="short">
<working-directory>/nfs/farm/g/glast/u12/EM2/log/$(RUN_NAME)</working-directory>
<log-file-path>/nfs/farm/g/glast/u12/EM2/rootData/$(RUN_NAME)/calib-v1r0/grRoot</log-file-path>
</batch-job-configuration>
<file name="digi" type="DIGI" file-type="root">grRoot</file>
<file name="jobOptions" type="text" file-type="jobOpt">calib-v1r0/grRoot</file>
<file name="merit" type="merit" file-type="root">calib-v1r0/grRoot</file>
<file name="recon" type="RECON" file-type="root">calib-v1r0/grRoot</file>
<file name="script" type="script" file-type="csh">calib-v1r0/grRoot</file>
<foreign-input-file name="exposure" pipeline="exposure-mdl-test" file="exposure"/>
<processing-step name="recon" executable="reconWrapper" batch-job-configuration="long-job">
<input-file name="digi"/>
<output-file name="jobOptions"/>
<output-file name="merit"/>
<output-file name="recon"/>
<output-file name="script"/>
</processing-step>
<processing-step name="LaunchSVAC" executable="RunRALaunchWrapper" batch-job-configuration="short-job">
<input-file name="digi"/>
<input-file name="recon"/>
</processing-step>
<processing-step name="LaunchReport" executable="genRTRLaunchWrapper" batch-job-configuration="short-job">
<input-file name="digi"/>
<input-file name="recon"/>
</processing-step>
<processing-step name="reconRootFile" executable="urlWrapper" batch-job-configuration="short-job">
<input-file name="recon"/>
</processing-step>
<processing-step name="meritRootFile" executable="urlWrapper" batch-job-configuration="short-job">
<input-file name="merit"/>
<input-file name="exposure"/>
</processing-step>
</pipeline>
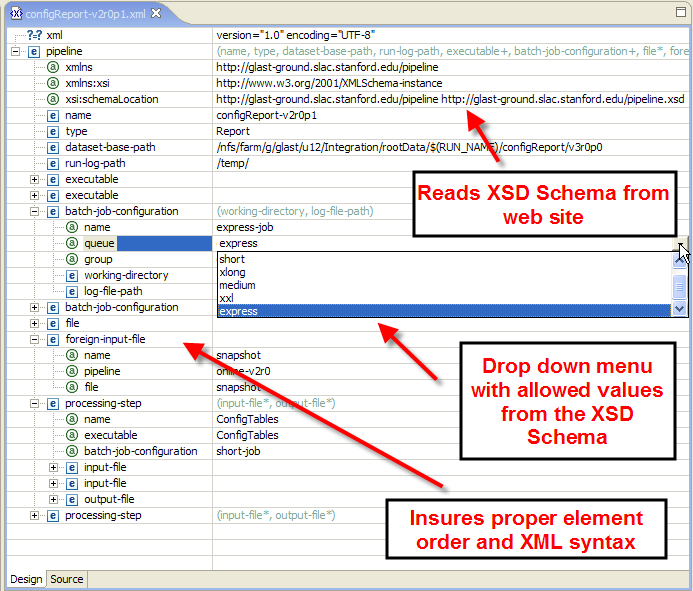
Here is a screenshot of editing a pipeline XML configuration file using XMLBuddy. Notice some of the niceties it provides, like populating drop-down lists with allowed field values.
Values for Elements used in Configuration File
Possible Values for Pipeline Type |
|---|
SimReconDigi |
test |
Analysis |
Reconstruction |
Digitization |
Report |
SystemTest |
Simulation |
Reprocessing |
Conversion |
Possible Values for batch queue |
|---|
long |
short |
xlong |
medium |
xxl |
express |
Possible Values for batch group |
|---|
none |
glastgrp |
glastdata |
Possible Values for a file's type |
|---|
MC |
Analysis |
text |
LDF |
DIGI |
RAW |
rcReport |
merit |
svac |
histogram |
script |
log |
ntuple |
tree |
RECON |
Possible Values for a file's file-type |
|---|
jobOpt |
root |
txt |
fits |
pl |
csh |
tgz |
xml |
sh |
tar |
gz |
tar.gz |
ps |
htm |
tex |
W3C XML Schema for Configuration File
Here is the W3C XML Schema for pipeline configuration files.
<?xml version="1.0" encoding="UTF-8"?> <xs:schema targetNamespace="http://glast-ground.slac.stanford.edu/pipeline" xmlns="http://glast-ground.slac.stanford.edu/pipeline" xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" version="1.0"> <xs:element name="pipeline"> <xs:complexType> <xs:sequence> <xs:element name="name" type="TaskNameType"/> <xs:element name="type" type="TaskType"/> <xs:element name="dataset-base-path" type="BasePathType"/> <xs:element name="run-log-path" type="RunLogPathType"/> <xs:element ref="executable" maxOccurs="unbounded"/> <xs:element ref="batch-job-configuration" maxOccurs="unbounded"/> <xs:element ref="file" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="foreign-input-file" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="processing-step" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="version" type="xs:integer" use="optional" default="0"/> <xs:attribute name="revision" type="xs:integer" use="optional" default="0"/> <xs:attribute name="patch" type="xs:integer" use="optional" default="0"/> </xs:complexType> </xs:element> <xs:simpleType name="TaskNameType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="30"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="TaskType"> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="SimReconDigi"/> <xs:enumeration value="test"/> <xs:enumeration value="Analysis"/> <xs:enumeration value="Reconstruction"/> <xs:enumeration value="Digitization"/> <xs:enumeration value="Report"/> <xs:enumeration value="SystemTest"/> <xs:enumeration value="Simulation"/> <xs:enumeration value="Reprocessing"/> <xs:enumeration value="Conversion"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="BasePathType"> <xs:restriction base="xs:string"> <xs:minLength value="0"/> <xs:maxLength value="200"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="RunLogPathType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="200"/> </xs:restriction> </xs:simpleType> <!-- Application --> <xs:element name="executable" nillable="false"> <xs:complexType> <xs:simpleContent> <xs:extension base="ExecutablePathType"> <xs:attribute name="name" type="ExecutableNameType" use="required"/> <xs:attribute name="version" type="ExecutableVersionType" use="required"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <xs:simpleType name="ExecutablePathType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="200"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="ExecutableNameType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="20"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="ExecutableVersionType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="20"/> </xs:restriction> </xs:simpleType> <!-- JobConfiguration--> <xs:element name="batch-job-configuration"> <xs:complexType> <xs:sequence> <xs:element name="working-directory" type="WorkingDirectoryType"/> <xs:element name="log-file-path" type="LogFilePathType"/> </xs:sequence> <xs:attribute name="name" type="xs:string" use="required"/> <xs:attribute name="queue" type="BatchQueue" use="required"/> <xs:attribute name="group" type="BatchGroup" use="required"/> </xs:complexType> </xs:element> <xs:simpleType name="WorkingDirectoryType"> <xs:restriction base="xs:string"> <xs:minLength value="0"/> <xs:maxLength value="200"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="LogFilePathType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="200"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="BatchQueue"> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="long"/> <xs:enumeration value="short"/> <xs:enumeration value="xlong"/> <xs:enumeration value="medium"/> <xs:enumeration value="xxl"/> <xs:enumeration value="express"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="BatchGroup"> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="none"/> <xs:enumeration value="glastgrp"/> <xs:enumeration value="glastdata"/> </xs:restriction> </xs:simpleType> <!-- Dataset --> <xs:element name="file"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attribute name="name" type="DatasetNameType" use="required"/> <xs:attribute name="type" type="DatasetType" use="required"/> <xs:attribute name="file-type" type="DatasetFileType" use="required"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <xs:element name="foreign-input-file"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attribute name="name" type="DatasetNameType" use="required"/> <xs:attribute name="pipeline" type="TaskNameType" use="required"/> <xs:attribute name="file" type="DatasetNameType" use="required"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <xs:simpleType name="DatasetNameType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="30"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="DatasetType"> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="MC"/> <xs:enumeration value="Analysis"/> <xs:enumeration value="text"/> <xs:enumeration value="LDF"/> <xs:enumeration value="DIGI"/> <xs:enumeration value="RAW"/> <xs:enumeration value="rcReport"/> <xs:enumeration value="merit"/> <xs:enumeration value="svac"/> <xs:enumeration value="histogram"/> <xs:enumeration value="script"/> <xs:enumeration value="log"/> <xs:enumeration value="ntuple"/> <xs:enumeration value="tree"/> <xs:enumeration value="RECON"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="DatasetFileType"> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="jobOpt"/> <xs:enumeration value="root"/> <xs:enumeration value="txt"/> <xs:enumeration value="fits"/> <xs:enumeration value="pl"/> <xs:enumeration value="csh"/> <xs:enumeration value="tgz"/> <xs:enumeration value="xml"/> <xs:enumeration value="sh"/> <xs:enumeration value="tar"/> <xs:enumeration value="gz"/> <xs:enumeration value="tar.gz"/> <xs:enumeration value="pdf"/> <xs:enumeration value="ps"/> <xs:enumeration value="html"/> <xs:enumeration value="tex"/> </xs:restriction> </xs:simpleType> <xs:element name="processing-step"> <xs:complexType> <xs:sequence> <xs:element name="input-file" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:attribute name="name" type="xs:string" use="required"/> </xs:complexType> </xs:element> <xs:element name="output-file" minOccurs="0" maxOccurs="unbounded"> <xs:complexType> <xs:attribute name="name" type="xs:string" use="required"/> </xs:complexType> </xs:element> </xs:sequence> <xs:attribute name="name" type="xs:string" use="required"/> <xs:attribute name="executable" type="xs:string" use="required"/> <xs:attribute name="batch-job-configuration" type="xs:string" use="required"/> </xs:complexType> </xs:element> </xs:schema>
1 Comment
Unknown User (blee)
The example pipeline config file is actually invalid; both "batch-job-configuration" elements are missing the required "group" attribute.