Participants:
LBNL: Katie Dunne, Timon Heim, Peilian Liu, Ben Nachman, Maurice Garcia Sciveres
SLAC: Nicole Hartman, Peter Kim, Martin Kocian, Rob Mina, Francesco Rubbo, Su Dong
ANL: Sergei Chekanov
KEK: Koji Nakamura
Shift Schedule
| Day | Shift | Shifter |
|---|---|---|
| Thursday Sep/29 | 9am – 9pm | Sergei, Su Dong, Timon, Ben, Katie |
| Thursday – Friday | 9pm – 9am | Peilian, Ben (->1am), Timon (->5am), Sergei (4am->) |
| Friday Sep/30 | 9am – 9pm | Su Dong, Nicole, Sergei (->11am) |
| Friday – Saturday | 9pm – 9am | Timon (->5am,10am->), Peilian, Rob (5am->) |
| Saturday Oct/1 | 9am – 9pm | Su Dong, Rob(->10am), Ben (10am->), Timon(10am-2pm) |
| Saturday – Sunday | 9pm – 9am | No shift, LCLS at low energy. Ben and Su Dong switching cold->warm setup |
| Sunday Oct/2 | 9am – 9pm | Ben, Peter, Katie |
| Sunday – Monday | 9pm – 9am | Su Dong, Nicole |
| Monday Oct/3 | 9am – 9pm | Francesco, Peter |
| Monday – Tuesday | 9pm – 9am | Ben, Rob |
| Tuesday | 9am – 9pm | Su Dong, Peter, Rob |
| Wednesday | 10am-10pm | Martin, Su Dong, Timon (remote) |
Event Log
Sep/19-26 prep
Sep/19: Previous dissembled Caladium is reassembled by Test Facility in the ESTB tunnel but parked on the side as beam pipe was reinstalled for a down stream experiment (somewhat of a surprise for us) this week. Caladium mover control electronics is still missing and to be installed next week. We checked the re-connections and found a few errors and missing links which got corrected. Connected the double chip module 94-04-03 as DUT with upgraded DUT CAT6 data cables and tried pixel digital calibration which worked as expected. Reordered the power supplies on the remote power strip to match the original panel in EPICS.
Sep/20: Checking with Carsten about what is really going on this week, it turned out T-542 (sFlash) is taking the entire period Sep/22-Sep/26 so that the originally agreed Sep/26 for us has evaporated and we were never informed of that change.
Sep/23: Checked with sFlash at ESA control room. The intense scene confirmed the fear that they will probably need the entire period, including Monday.
Sep/26: sFlash is continuing with their runs so that we are unlikely to have any chance to run for Monday, considering that Caladium still needs to be brought onto beam line after beam pipe removal. So Monday is expected to mainly doing lab test of the first RTI module to get proper configurations prepared and check other preparation items.
Sep/27
- 8AM MCC meeting mentioned ESA beam delivery problem for sFlash on Monday but eventually took very good beam data. sFlash cleanup.
- 10AM ESA became permitted access.
- Caladium moved onto beamline after removing section of beampipe and mover electronics box reinstalled. Chiller level low, refilled. DUT stage also back on and hold current is nominally driven. Caladium powered up current anomaly traced to Clock-Jtag cables swapped. Missing TLU-NI USB cable located and reconnected. Caladium auto-trigger run and standard DUT (mounted 93-04-03 IBL double chip module back) both operating.
- Noticed IBL double-chip DUT LV PSU setting sagged from 1.5V->1.2V when module current went up to 0.5A. Realized this was due to the current limit of 0.5A appropriate for single chip modules. Raised current limit to 0.8A stablized voltage through threshold tuning exercise.
- FE65_P2 readout arrived from LBNL. Mike Dunning/Juan Cruz laid two DUT ethernet lines for the two readout PCs to connect to the ESA 104 private subnet. Mike granted fixed IP addresses: 172.27.104.52 esadutlbnl1 (riverhorse) and 172.27.104.53 esadutlbnl2 (inkfish), gateway is 172.27.104.1 and mask 255.255.252.0.
- Various cameras setup - see main portal.
Sep/28
Plan for today:
- Priority is to debug FE65_P2 readout integration with telescope (Timon, Ben) and taking telescope whenever needed,
- Install the 2nd RTI SC module into the ESA DUT seat to do in situ threshold tuning (Sergei,SD).
- Threshold tuning for the first RTI SC module at group C lab (SD,Francesco,Rob,Nicole)
- HV remote control/mon with EPICS (Ben,SD with help from Mike)
- possible telescope geometry optimization (SD)
- Presentation [slides] of our plan and beam requirement to MCC (SD) at the 4:15pm accelerator weekly planning meeting next to the accelerator control room at the ground floor of B52. Everyone is welcome.
- Discuss preparation status, run plan and shift assignment at ESA control room at 5pm.
Activities:
- RTISC2B replaced the 93-04-03 as the RCE DUT to get threshold tuning going for it.
- When attempting to move the DUT closer to beamline we finally realized the oddity of the vertical position was due to the DUT stage mounted upside down. Juan corrected the mounting and now position close to be central.
- Sergei installed a script duplicate.sh in the moduleconfig directory on esadutdaq1 so that one clone an existing module's RCE DUT config directory into a new module's starting configuration with underlying sud-directory file name to follow the new module name.
The Research Yard construction people are unhappy about us rushing across the area in speed so that we are currently disallowed to go to ESA from the Research Yard ground floor through Gate 17/SSRL route. Everyone should go to ESA from Gate 30 to the top level counting room then down the stairs to ESA hall. If we have to drive in with equipment, we can give Keith Jobe a notice to arrange the passage via Research Yard.
- Timon exercised first integration of YARR readout infrastructure with EUDAQ: YARR Producer correctly booted up in EUDAQ Run Control. Correctly receiving configure transition and acknowledge completion while actual configuration content and event loop handshake still in progress.
Re-orientated the RTI module by mounting inside the L to give some space for the HV LEMO bend not touching EUDET. The HV socket facing perpendicular to the PCB is not test beam friendly. TImon mounted the FE65_P2 nad looks like RTI and FE65_P2 are reasonably aligned in height and horizontal position to go together. Just some DUT stage fine shifts should bring the DUT to beam.
Segei's threshold tuning for RTISC2B is giving high noise at 500e. Realized we didn't tape the sensor window. Proper blacktake hard to find. Kluged some thicker tape for now. Simple threshold scan didn't get sensible results. To be tried again tomorrow.
Sep/29
Plan of the day:
- ESA search for returning to controlled access is either ~9am or ~11am. First beam by noon ?
- Preparation the RTISC2B + FE65_P2 pair DUT suite for first beam:
- DUT stage fine adjustment to align DUT into beamline and horizontal move of telescope into beam. Visually locate FE65_P2 window wrt RTI.
- Adjust overall EUDET planes to pack closer and narrow the DUT region. Needs an LEMO-L for the RTI HV socket to avoid HV cable bowing out to EUDET.
- Proper black tape for RTI sensor window and recheck threshold tuning with taped window.
- Further auto-trigger integration of YARR with EUDET.
- EUDAQ config file for the DUT suite
- Continued threshold tuning for RTISC4A in the lab to get ready to go in later, and cross check on noise effects seen on RTISC2B.
- First beam activities
- Time-in of FE65_P2 devices if DAQ event handshake fully functional. If no new device interpreter with EUDAQ online mon, offline dumps sufficient to verify ? Hopefully the known lab test delta of 3 clk ticks with FE-I4 will save us from a long chase.
- Beam window size, location and rate adjustment.
Activities:
- 8am MCC meeting clarified that the ESA search is probably going to be 11am-noon, not the originally hoped 9:30am. We declared ready to run right after ESA search. It was brought up that a few weeks ago some ESA user from Japan brought in an irradiated sample without declaring to RP which caused quite some disturbance that even temporarily shutdown the ESA operations. Lia's question on this caused a major overhaul that required us to send updated participant list, and TestFac experiment review form and RP in person interview etc. before getting approval to start at ~2pm.
- 13:00 - ESA search has been completed and the cave is now set to controlled access.
- DUT stage fine adjustments brought DUT aligned with Caladium MIMOSAs, and whole telescope moved horizontally into the beam line.
- RTISC2B appears have gone into very strange state and cannot be calibrated even after removing the rough taping. Brought in RTISC4A to replace it and sensor window properly taped. Threshold calibration runs but the noise rather high at ~400e, with some systematic structure also. Suspected bias voltage and seems to measure 0V on the HV ch-0 used. Switched over to ch-1 can at least drive the voltage up. Maurice concerned that the leakage current seemed a bit high >>few uA for very small starting bias voltage. However, cranking up to -53V (these Micron 300um sensors actually need -80V to deplete) didn't bring much more leakage current to settle at 4uA. Left at this setting to try to run. Sergei managed a standard 3000e tune with nice narrow dispersion. The noise is still high at ~400e. Also checked the various grounds and decided we can leave the HSIO2-PSU ground hook off since the HSIO-FE cable is now proper CAT6 with ground. This didn't make any difference. Decided to just take this tune as running config (RTISC2B__cern__25.cfg) - calib directory stayed with RTISC2B but this is really RTISC4A.
- Tried EUDET ni_autotrig runs but somewhat confused by the behavior: without starting up the TLU producer, the autotrig setup actually runs with event build flowing and histograms in monitoring updating, although trigger/particle counts remain 0. When added the TLU producer, particle counts still go up but no trigger and no event build.
- 18:05: Carsten called and informed us about the delay. The people before us wrapped Al foil around the emergency buttons which of course upset a lot of people. They stopped ESTA operation until it is resolved, which should be in the next hour.
- Beam finally arrived ! We don't seem to get any trigger. Decided to ask for access to look at the trigger and change RTI sensor HV control at the same time. One problem with trigger quickly found: the Caladium Date Reducer box data link to TLU was misplaced on the Data Reducer box side to the port right next to the 6 MIMOSA data cables, but it really should be plugged into the channel at the far end. Fixing this resolved the TLU producer anomaly above.
- The remote control to the HV in the NIM crate (the orange one in the middle) now works via the KB 9130 power supply. There is a panel in the epics for T-542 for controlling the low voltage. The granularity is pretty good - by setting 0.08 V (=80 V in HV), we get 0.086 measured (and displayed on the monitor). The only problem is that the current is in A so we can't monitor it (need to change to uA). Should ask Mike tomorrow during the day for help with the quick fix.
- After we moved HV control and set voltage -53
- Upon restart with beam, we still don't get the beam triggers, although auto trigger runs with TLU now works correctly.
- 21:19: Accelerator shift change, beam energy changed and was off for 20min, back now. Will take access to investigate trigger problem.
- ESA access again to examine the beam trigger. Traced the trigger cable from the DUT rack to the patch panel area and placed a yellow tag on it. It is connected to the row of BNC plugs saying "To B061-01-06" socket J5. Brought scope to the DUT rack and placed a BNC T on the trigger cable to check it on the scope by moving over the rack top camera. Upon restart with beam, we saw from the camera that there are blips of pulses at ~5 Hz as expected and negative polarity as expected from NIM but the pulse height is much lower than the -1V NIM. We though the trigger signal might be available at the counting house but the "beam spill" plug had nothing on it. Toggling the trigger panel channel #10 SiTrack- Caladium Enable on/off one can see the 5 Hz blip goes on/off together with it which suggests the trigger is still hooked up to the right channel but too low an amplitude for the TLU box. Couldn't make much progress without Mike.
- Decided to quit for the night and reconvene tomorrow when Mike Dunning is around.
- New calibration is RTISC2B/config/RTISC2B__cern__93.cfg for 89V shift volts. The main features of this calibration: Threshold distribution has mean 2988e, with sigma 68e. The noise is 288 e.
Sep 30
- Some description and tutorials how to take the calibration scans is https://atlaswww.hep.anl.gov/asc/wikidoc/doku.php?id=itk:testbeam. All figures correspond to the previous scan on Sep 29 ( RTISC2B/config/RTISC2B__cern__93.cfg)
- 5.00AM: New ANALOG and THRESHOLD scans. It was found that, without calibration, we see large number of low-efficient analog channels. About 70% of channels have 40 counts (50 expected). This drastic difference compared to Sep 29, right after installation of this module, when about 1% of channels showed 40 counts (mostly for first 2 rows). The noise level from the threshold scan increased by a factor 2. Low voltage increased to 2.32A (from 2.08A)
- 5.15AM: New calibration for the RTI module is RTISC2B/config/RTISC2B__cern__158.cfg. After the calibration, it was noticed a large number of bad modules, large noise 400e, and the analog scan has more loses on the left edge.
- Preliminary conclusion: Similar to the red module installed on Sep 28, the green module shown signs of the degraded performance for the analog part: lower efficiency and a larger noise after 6h inside the test beam setup. This cannot be related to the beam, since there was no beam for the red module on Sep 28. This also not related to the light, since the sensor of the green module was covered.
- New calibration RTISC2B/config/RTISC2B__cern__225.cfg
- 08:36: Doug and Juan sent by Carsten are helping us with the Trigger. We found where it is patched from crate B060-14 signal J10 (as it is #10 in the tirgger panel). The issues of the small signal seems to be caused by a loose cable.
- 8:58: beam on and we get triggers. Now looking into the actual data. Initial beam ~2 particles per pulse.
- 09:02: beam off for energy change, roughly 20 min
- 09:29: beam back with higher intensity (~10 per pulse) using it to align the telescope. Needed to move whole telescope by a few mm in X and Y to center MIMOSAs to beam. Initial beam size (dX,dY) ~ (6mm,4mm). Asked Tonee to enlarge it but it appeared to be not simple. First attempt enlarged vertical size only at high X side and made it trapezoidal. Decided to pursue basic DUT test first and come back to this later.
- 80lb dry ice for the 2nd period is delivered to ESA.
- FE65_P2 took first data with Run 497 (not yet timed-in hits) by enlarging DUTMASK to 5 to include the first device, but without DUT device details so that online mon cannot yet process data.
- RTI with EUDET run used the configuration SLAC_1dut_FEI4B_RTISC4A.conf. Synched beam hits appeared right way but sparser than expected. Tried again later got higher rate.
- 2:00: Brought the cooler for the dry ice from lab C and brought it into ESTB. Matt is sick at the moment, so see Marco for help with lab things (for example, the blue gloves can go back to the table in the lab when we are done with them and he can put them back where they belong). During the access, we setup the monitoring of the voltage and current from the HV power supply that is now remotely controlled. The voltage seems roughly correct, but the current is too small to measure at the moment (below the pedestal). These values are called Caladium HV-Imon or HV-Vmon in KL3404 in the Caladium Beckhoff epics panel. Imon seems to have a pedestal of 5mV while AVO measured 1.5mV.
- Finally managed to fully integrate YARR into EUDAQ with the converter so we can see the DUT in the online monitoring. Now, working on timing in the FE65P2.
- 5:00: Carsten stopped by to check on us. There are only two operators this weekend, so we should be patient with them. Some things we learned from this conversation:
- If we need to show monitoring plots to MCC, might be easiest to just walk over there.
- We can see the accelerator optics in the BSY (=Beam switchyard) on the ESTB epics panel.
- SL10 (slit 10) is at 2mm and if closed, we can reduce the rate.
- C24 (collimator) this can make the spot smaller (cuts into the edges)
Requested to MCC to enlarge beam spot and up the particle rate to get ready for FE65_P2 time-in. Made only little impression and ended up with a fan shaped spot. First did RTI+EUDET runs to try to center beam spot on the RTI sensor using the DUT stage fine adjustments. Looks like DUT Y is really Y, but DUT X was -x. The runs typically got stuck after 1500 - 2500 events due to RCE DUT readout hang and run would end there. The list of runs with EUDET+RTI:
Run Comment 534 Start position 535 fineX +5mm, fineY -2mm, then in the middle if the run fineY +2mm 536 fineX -2mm, fineY +7mm 537 fineY +2mm (bi-modal Y distribution. Sharper peak is the real spot) 538 fineY +2mm - While having shift change, dropped the IBL irradiated sensors LUB1,LUB2 to the freezer inside ESA.
- 21:50: ACR called and said that apower supply of the A-band tripped, they are trying to send us as much as possible, but we basically only see noise. They called someone in who should arive in around ~20min.
- 23:05: Tech is on site, ACR is guessing 1h to fix if fixable.
- 23:30: Fixed! Beam back! ACR played around and cranked up the rate, we are now getting around 200 per pulse.
- 00:22: Have tested every possible latency setting assuming the trigger arrives after the particle without success. Now seeing if it might be possible that the trigger comes from the future.
- 00:56: Finally seeing particles in FE65-P2!! Confirmed trigger is from the future, to be precise particles come ~245 bc after
 trigger. Now taking some data.
trigger. Now taking some data. - Putting trigger signal on Scope ESA:SC03 channel 4, orange seems to be particles as they fit the timing described above
- Run 596 probably first Okish run with FE65p2, TLU tag might be off.
- Getting 800e per pulse, rate in FE65p2 seems low, moving 2mm up to 23mm for 597
- 2mm more so 25mm for 599
- Run 600 at 30mm
- 603 22mm
- Now module is constantly noisy ....
- Sometimes noisy, sometimes not, no clue if i'm moving it in the right direction
- Asking ACR to reduce number of electrons, slowly working our way to ~10
- Run 615 adjusted to ~10e per pulse, letting it run for a while.
- At this point we are flying blind again, I would need to know if this data can actually be decoded and if we are in the beam.
- Starting 616, to take a closer look at 615.
- We are calling it a night, I need to reconstruct this data to understand what is going on. More importantly I have serious concerns that the data format might not work with reconstruction and I need to know that in time. Will go to sleep and take a look with Ben tomorrow. The module will stick around and YARR data taking (except the noise issue) is very stable, so should be able to run in parallel to the irrad studies.
- 02:26 : stopping and letting ACR know.
Oct/1
- 8am MCC meeting met incoming LCLS primary user with ePix (500um silicon for X-rays) who are also battling with radiation damage and showed interests in what we are doing.
- Did a threshold scan (Run 178) on the RTI module and found threshold still narrowed distributed around 3000e but noise got substantially worse at ~500e,
- Turned off RTI bias from the remote control console, but the LV read back still says 6mV, Caladium ADC Vmon=15mV, Imon=5mV which are effectively pedestals. Noise up to 1100e when unbiased.
- Reestablished RTI bias for -80V with BK setV=0.080, readback 0.085 and ADC Vmon 0.088-0.093. Threshold scan Run 179: threshold still narrowly groups around 3000e, noise still ~500e, but he right edge bad pixels cleaned up. Bizarre looking noise RMS vs channel map with systematic alternating column pattern and multiple clusters of values within even the same column from 300e – 900e depending on pixel location.
- 11:00: Used an access to remove Koji's FE65P2 module for shipping. Now will run YARR parasitically for the remainder of the beam time. Next move is to do a scan over the RTI module before switching to the cold box.
- Started the beam spot systematic scan over the RTI module by moving the DUT stage. Beam was ~20 particles per crossing. DUT LVL1 peak ta at 4 - moved the original value ~8. Run list see table below.
- 3 FE65_P2 surveyed by RP and shipped to Koji.
| Run | Position | Comment |
|---|---|---|
| 630 | Start position | spot (x=100-200, y=45-80) |
| 631 | y+3 mm | No YARR |
| 632 | y+2 mm | No YARR |
| 633 | same | Retake with YARR (now in all subsequent runs). Delta y (rows) = 0-100 |
| 634 | y-2 mm | Delta Y = 50-150 |
| 635 | y-4 mm | Delta y = 120-220 |
| 636 | y-4 mm | Delta y = 220-300, Delta x = 45-80. Stopped beam for RP to survey Koji's modules |
| 637 | y-2 mm | only got 1000 events before the RCE gave up (wasn't quite to 2000 from 636 because it was stopped manually) |
| 638 | same as 637 | X position is -67 mm |
| 640 | x-4 mm | Huge noise burst! See the timing distribution in ./bin/run640.root |
| 641 | y+4 mm | no noise burst |
| 642 | y+4 mm | noise burst |
| 643 | same as 642 | noise burst |
| 644 | y+2 mm | |
| 645 | y+2 mm | |
| 646 | x-2 mm | |
| 647 | x-2 mm | X position is -75 mm |
- The almost predictable hang of RCE DUT readout was consistently happening after every 1500-3000 events, that needed HSIO reboot to recover. Later run with old irradiated IBL LUB2 at even much higher particle rate of ~150 were running OK for 10K events. The RTI module data had corruption ?
- We also saw sudden big burst of noise hits causing temporary peak in LVL1 time distribution which gradually averaged out.
- Call for access to switch to cold box setup. Made new cut out cable slot on cooling box (but under a screw) to allow easy cable exit without running into the MIMOSA plane. Mounted LUB2 as vertically and perpendicular to beam as DUT. Remeasured component vertical position inside box and marked the module center on box. Tried to lower the box into beam but fine Y mover maxed out at the bottom. Lowered the sliding bracket of DUT stage done by ~15mm to keep it in range.
- We dismantled the TLU trigger scope monitoring and put the original cable back to TLU.
- One remaining FE65_P2 is mounted on the back plate of the last EUDET plane down stream. DAQ computer also moved to the back end. LV=5V. Xlinx dongle plugged into the left of the two USB slots of the computer. The YARR readout card connection has a bit of snag as the last mm of the conenction could not go in one one side as it hits the mounting hole shroud so that the HDMI connection is slightly tilted and not all the way in on one side,
- We notice at some point during the access that the horizontal position of the whole telescope was several cm towards to +x wall according the ceiling alignment laser, but we don't understand how it could have been there.
- Calibration failed initially when LV was set to 1.5V. It was then realized the for these irradiated old FE-I4A the correct LV is 1.2V. HV is now on remote control.
- 8:25pm restarted beam. Indeed confirmed the whole telescope was way off in X and had to move a long way back to beam. DUT also needed to move up by ~1cm to center to beam.
- HV of -800V was giving LUB2 decent hit efficiency already. The last run with collimator opened to 150 particles/crossing was recorded as Run 648 with config SLAC_1dut_rad_FEI4A. L1V1 timing peak between 5-6. The beam spot shape flip between EUDET and DUT clearly says the DUT x is EUDET -x.
- 9pm: beam stopped to switch to low E primary. DUT HV off. Our shift ends here.
- Cold box block is <-50C.
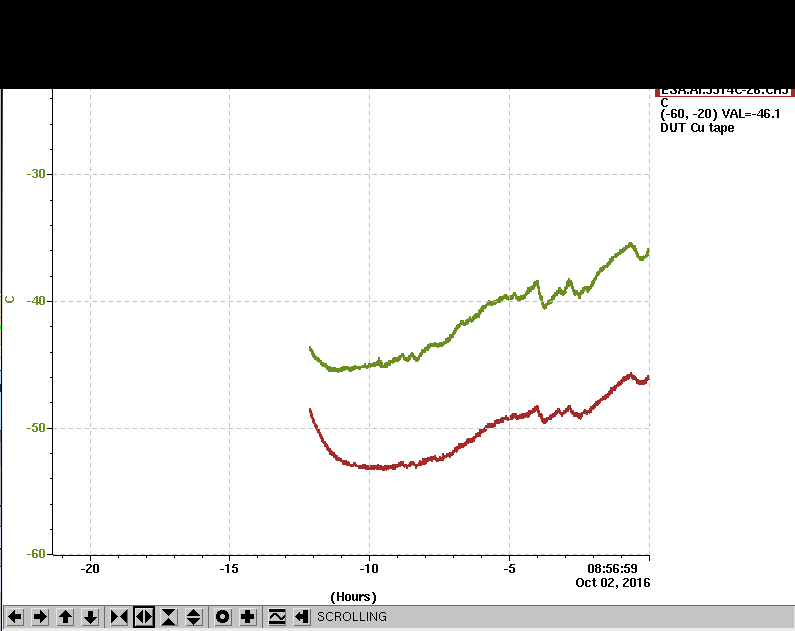
Oct/2
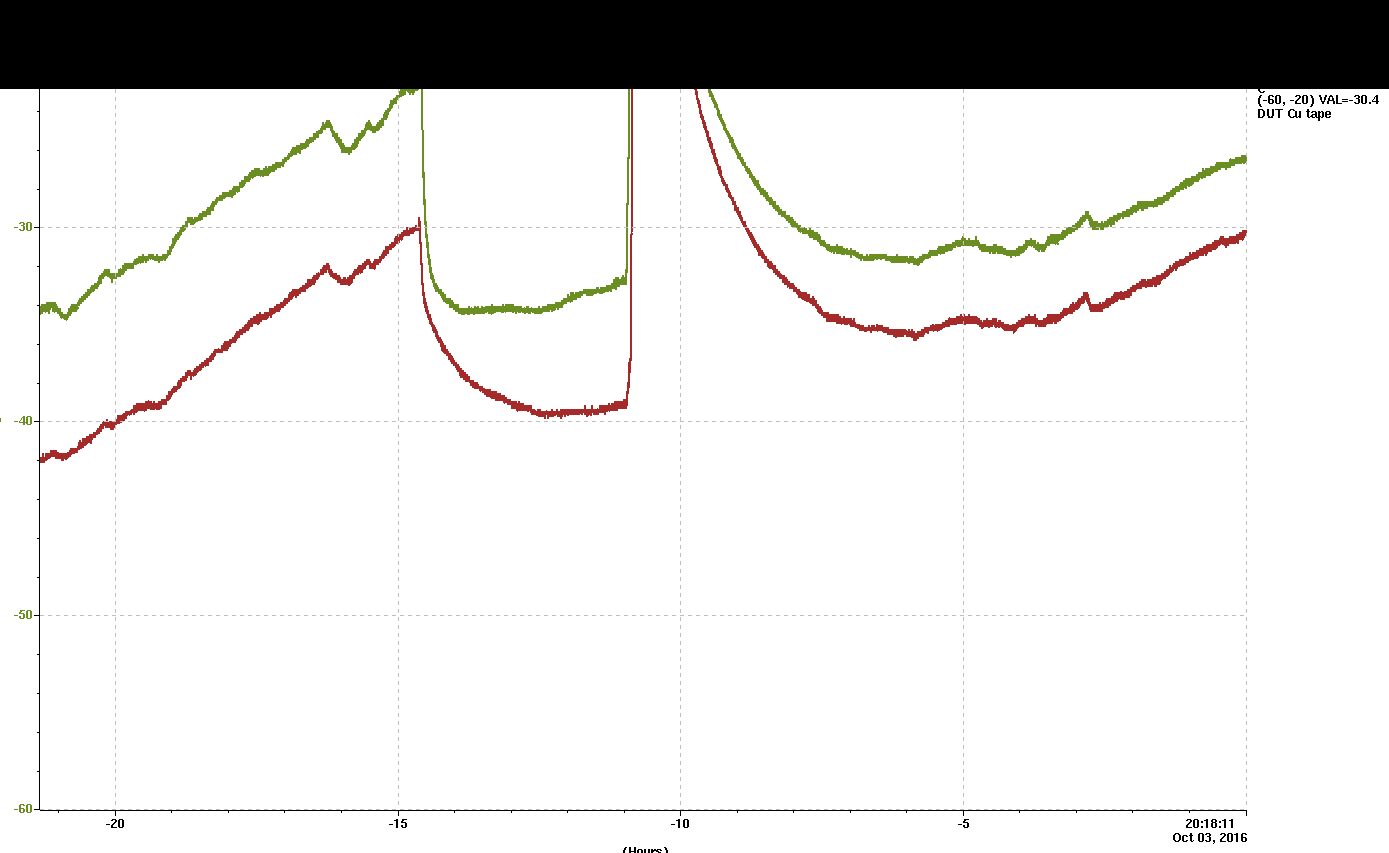
- Temperature still -40 (air), -50 (block)! Here is a picture of the strip at 9:00 am.
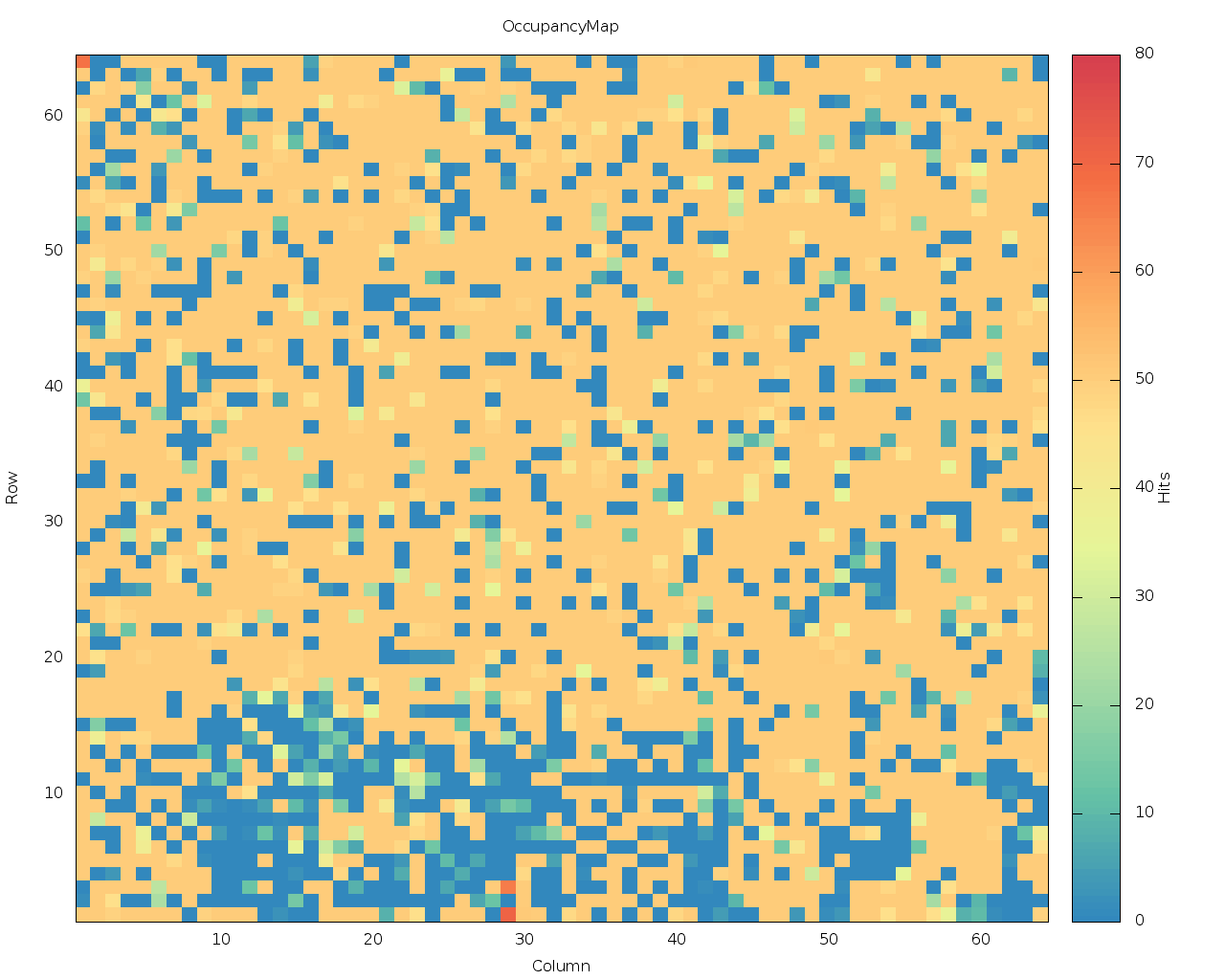
- 09:30 FE65-P2: An analog scan looked pretty bad at first:
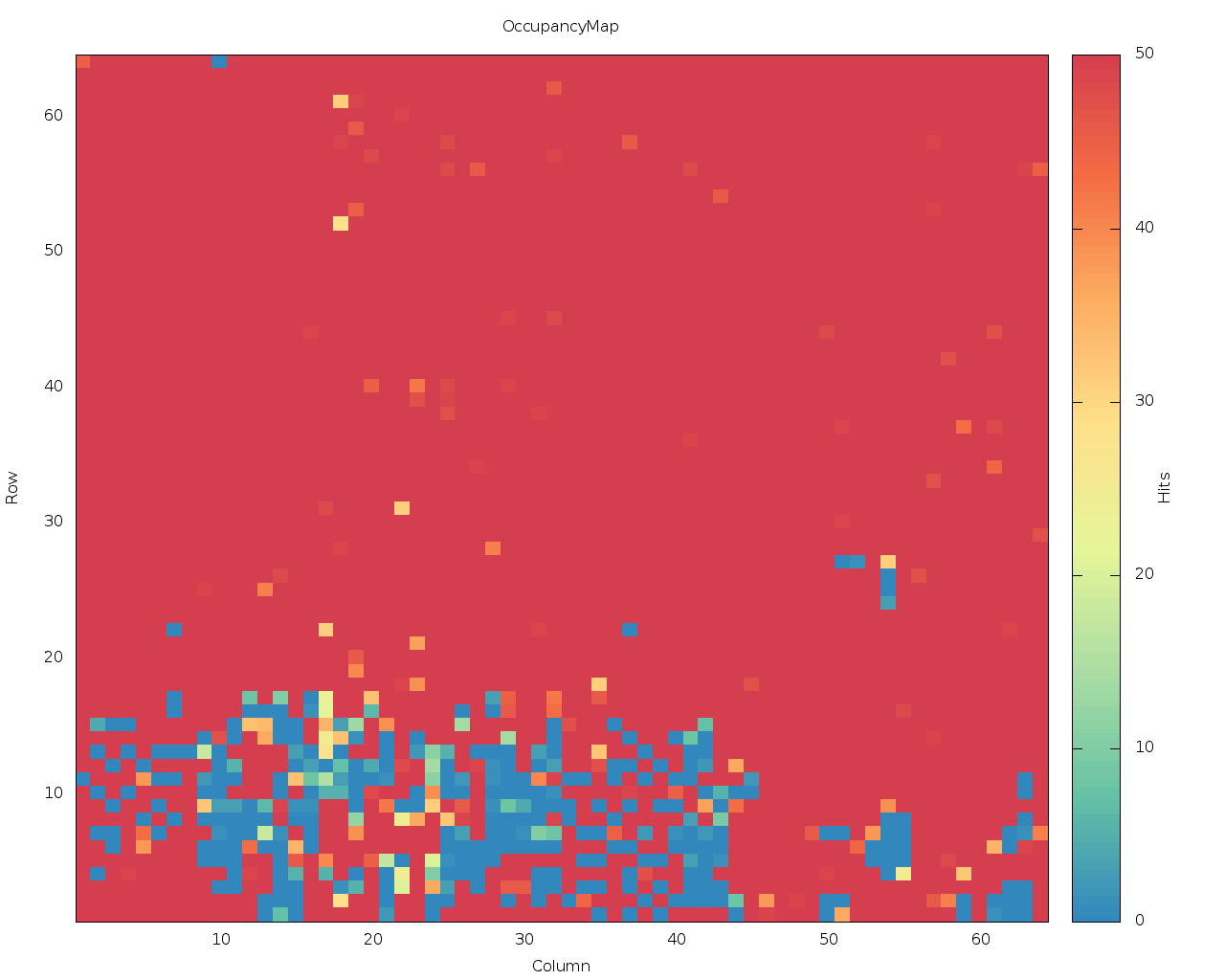
- 09:30 FE65-P2: ran tune_globalthreshold and tune_pixel threshold and got okay results from an analog scan:
- When running YARR we get an error for each scan: ERROR # virtual void Fe65p2DataProcessor :: process() : Received data for channel 1 but storage not initialized!
- 09:42 We have beam, are current calibrating LUB2 using config_rad_np_0_271
- 10:10 started run 649 with config SLAC_LUB2_with_FE65P2 and YARR producer; currently blasting us with 400 hits per plane TA = -35C TP = -43C; events wouldn't build so restarted RCE/Mimosa, etc.
- 11:03 stopped run
- 11:34 Run 650 TA = -31C TP = -43C Moved DUT back up 4mm to sit in area that avoids dead pixels. After running for about 1600 hits this was actually a worse position so repositioned back -4mm
- Apix is not showing as many hits as all other mimosa planes, even those behind the DUT. We tried using the previous config from yesterday, didn't improve things. For the July testbeam the LV was set to 1.5V with 0.33 and for this run we had 1.2V.
- 12:37 Considered RCE couldn't handle the high particle rate so we asked MCC to lower to ~20 electrons. Did not improve things. Requested an access so we could increase the LV to 1.4, top off the dry ice, and check to make sure we were still in the beam.
- 13:13 Run 656 The first run the telescope had about 300 hits per event while DUT had 4.5. After the access the telescope sees 21.5 and the DUT sees 1.9. The mimosa has different pixel size (2) so accounting for that the number of particles the telescope sees is 10 per pulse and the DUT (with cluster size 1) sees 1.9, so this ration is in the same order of magnitude. Pixel ToT distribution is lower than yesterday's
- 13:40 Tried retuning LUB2, did not improve ratio of hits per event of Mimosa/DUT - still about 11/3
- 15:00 Retuned Run 658 -> TOT still doesn't look great
- Configs:
- 349 thresholdscan 1000v
- 350 thresholdscan 600v
- 351 thresholdscan 400v
- 16:35 Access to monitor leakage current, turns out the HV current was at compliance. It was tripped at 400V, so all runs today were without HV operating. Changed the current limit and set up a camera to monitor HV and leakage current
16:50 started run 662 at 400V. Planning to run 10 minutes at a time in 200V increments
Run Comment 662 400V 20uA 663 600V 34 uA 667 800V 51uA 668 1000V 70uA - Runs 662-668 were very noisy RCE needs to be restarted almost everytime we start a new run
Tried running read_rawData script on some FE65-P2 data from earlier (run 649) that we scp'd to shieldtoad but program hangs
17:45 Retuning 1500e@800v -48C config: 392
Run Comment 669 800V 47uA - very low hits per event again. Looks like the tuning is masking lots of pixels because the noise has gone down.
Weird behavior could also be because the temperature is too low?682-698 High rate area scan with ~80 hits/event perpendicular beam. HV=800V, ~200uA, rising with gas temperatures from -35C to -28C. Config=SLAC_1dut_rad_FEI4A (calib=335, Thr=1500e 8000e@10TOT). Stepping through windows of 7x3mm. See Twiki spread sheet for run details. 701-716 Low hit rate (~3 particles/event) efficiency scan for left column and more top regions. HV=800, current 250-380uA gas temperature -28C to -25C, with same configuration as above. 710-714 HV bias scan from 1.1KV down to 0.6V. Gas temperature -34C stable after dry ice top off. - The data taken with config-392 showed big unexpected holes. We examined the enable masks in that calibration and found that majority of the pixels are disabled and only some island of pixels are enabled. The block temperature is <-50C ! which is too difficult for calibration to work. When dug out the July perpendicular run config SLAC_1dut_rad_FE14A to run with that (only some pixels on the edges disabled), most pixel back to life again while the left and bottom of the DUT got some more noise hits which is expected from the too cold temperature.
- Requested access to warm up somewhat and take the opportunity to drop a 1.3" wide wood chip into the DUT box between the dry ice partition plate and DUT base block to prevent direct contact and let DUT to follow more the gas temperature and hopefully not following only gently the dry ice.
- Upon restart we got bogged down by DUT readout errors which was rather resilient to reboot HSIO. Went for access and lowered the LV 1.4V->1.3V which solved the problem nicely. So the lessons is that 1.4V is only workable at very low temperatures and was the cause of the many DUT readout errors. We know 1.2V worked nicely at room temperature so that one should not need to run above 1.3V. Retro (SD): This might be a red-herring. The more likely culprit was probably the LV powerup supply oscillation. Hold out LV plug until supply up and settled before pluggin-in might be might be the actual action that helped.
- Decided to go after a DUT scan at high rate to map out bad pixels first. Requested MCC to (fully) open slit10 to 10mm which gave ~80 pixel hits/event for the scan, during Run 682-698 with ~2000 each stepped over 7x3mm windows. A beam line magnet tripped briefly which took a way the beam for 15min. As temperature rising through these runs, the noise pixel gradually fading out.
- 2:00am recentered beam spot on the left hand vertical strip to take low particle rate fine quality efficiency data. Asked MCC to close down slit10 and looks like at 0.5mm one cannot see APIX LVL1 timing peak any more so we settled for slit10=1mm. The PIXEL hit rate for good MIMOSA planes is ~10 but when no beam this still reads ~3 which is the effective pedestal. Checking the APIX cluster LVL1 time peak size and overall DAQ plane count histogram one can derive the cluster rate/event = ~2000/650 ~ 3 which is almost perfect. Given the noise pixels around at at least the same rate, it doesn't make sense to go any lower. Offline reconstruction has to find a way to work with at least this rate.
- Low hit rate efficiency data collection on the left column start with run 701 at the bottom for 10K events per run and marching up 4mm each run.
- 4:15am Finished a full vertical stripe of low hit rate data. Decided to try varying bias. Gas temperature already at -25C and and leakage current 340uA. Making a quick HV step up, it was found that although the current was still <600uA at 1.0 KV initially, but it is not stable and continued to creep up even when we were not running. Decided to hold off bias scan until we top off the dry ice next time.
- Added two more low rate run on the top half towards the center.
- Leakage current up to >500uA. Requested access to top up dry ice. It was half empty and our top up didn't pack the full chamber to avoid going too cold.
- Upon restart, we got a lot of DUT readout errors choked the DAQ again. Had to ask for another access. This time only tried one simple thing: power down LV and unplug LV cable at PSU then power up PSU and wait until the ringing output settle before plug in the LV cable to PSU. This was sufficient to clear the problem. Many previous incidents are probably due to the same power up problem that simply did not bring up FE-I4 properly. This points to the importance to follow this LV power up ritual and check readout with a calibration in the pit before exit the access.
- The sensor leakage current dropped very quickly back to <100uA after dry ice top off. We decided to try again for the HV bias scan and this time leakage current did not run away even at 1.1KV. So we started the bias scan at 1.1KV in region (X=20-50,Y=220-280) from Run 710.
- 9:00 am: end of the perpendicular runs.
- 10:00 went in for an access to tilt the sensor. Some reference photos taken by Ben and SuDong. The thermocouple that was taped to the base metal is now somewhat loosely attached, hence the two thermocouple (one in the air; one on the metal) temperature readings are closer than before. Also added more ice.
- 10:40 am: Temp. measurement down to -24C and -27C. Started a new run and asked for the beam, but MCC tells us that due to MD there will be no beam until 3 PM. Somehow this information was not related to us until now. Sigh.
- 3:00 PM: MD is over, but it will take another 30 minutes before beam.
- 4:30 PM: Well, MD (apparently scheduled last Wed.) continues. Until 7 PM. In the meantime, they will give us beam whenever they can, though may not be continuous. Still useful for setting up the tilted sensor run configuration.
- 4:45 PM: Finally some pulses in the trigger! HV set to 800V; the current reading started at 260 uA and crept up to 294 uA in 5 minutes, then stabilized. Temp. readings are -31C and -35C. The current is down to 275 uA after another 10 minutes.
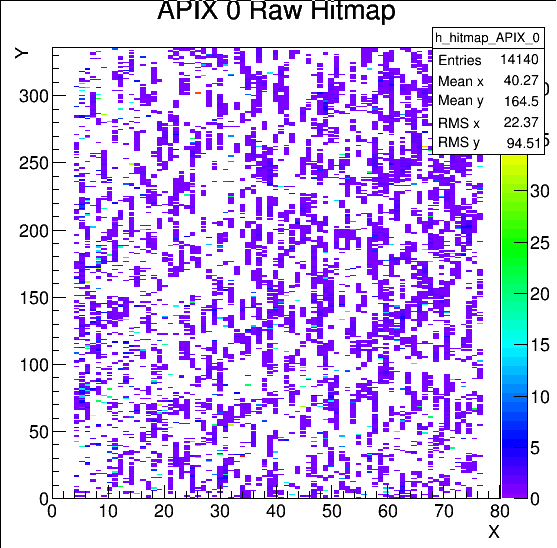
- Run 718 shows cluster hit streaks in the entire APIX hit map, so DUT appears to be in the central target area. We will keep the location as is for now. Config file = SLAC_LUB2_FE65P2 (335.cfg). Taking 2 runs of 12000 events each at 800V (Run 718, 720), 600V (Run 721, 722).
|
|
|---|
- In Run 723 we noticed that the beam pulse profile appeared to have a doubled feature. Also see the monitoring histograms in Run723. Called MCC. The double feature will come/go through the night. He at least said sorry.
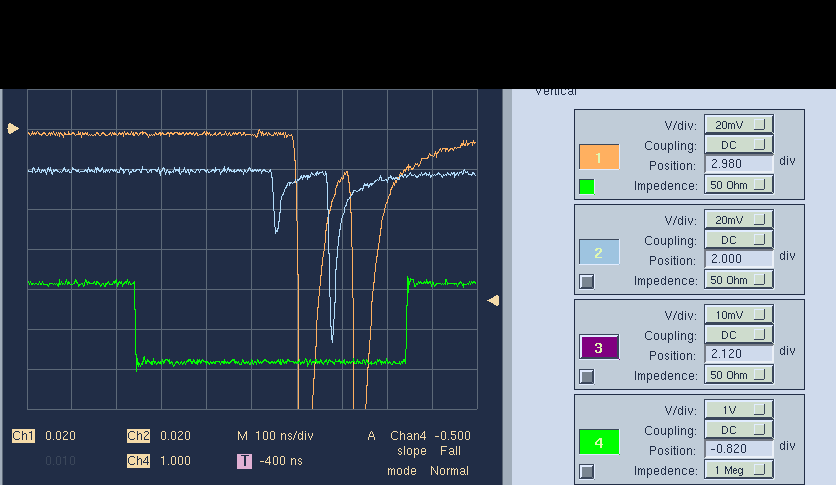 |  |
|---|---|
| Known LCLS development for XC119 to have 2nd pulse 122ns later | Single pulse normally at =5. 5*25ns ~ 125ns. |
- Access to add more ice.
- 9:00 PM: Running now at 800 V with a 145 uA leakage current. Tried again to reduce the rate by moving S10 to 0.5 mm, but saw no particles on the DUT! Now to 2mm to verify that the DUT still exists. Don't want to upset the operators, will wait for shift change to go back to 1mm.
- 00:26: asked to increase slits from 1 to 2 mm. Particle count before was ~10 (but double peak, so ~5) and after is ~30 (still double peak, so ~15). We got this from looking at the cluster multiplicity in the 3rd telescope plane (basically no noise).
- 1:10: asked for the S10 slits to be moved out the whole way (100 mm) so that we can quickly scan the sensor.
- 2:35: LCLS beam down for a user (they didn't tell us...had to ask when we noticed no beam). They say they will 'give up in 30 min' and revert back if they can't get the configuration they want. Powered off the HV in order to preserve the temperature.
- 3:55: Asked to go back to the 2mm S10 spacing to take some final data with LUB2.
- 4:25: Call from ACR - lost beam because LCLS users want 30 Hz. No comment on when it would be back.
- 4:35: Asked for an access to swap LUB1 and LUB2 (might as well while we have no beam).
- Just swapped LUB1 and LUB2, LUB2 back in freezer. Ran digital and analog scans during access and looked okay out of the box using LUB2 config. The threshold was not so great, but that could just be the threshold. Will use the proper one now. Adam (MCC) said that LCLS user is back to 120 Hz, so we could have beam again soon (Adam is by himself tonight !!!)
- Temperature very warm (~-10), tried turning on HV but tripped the power supply. Turned off HV and now waiting for temperature to cool back to where it was before.
- 7:00: Went in for an access to add more ice (now out of ice) because the rate of temperature decrease is too slow (done at 9 am!)
- Access to examine HV and found the Bertan (orange) HV it tripping consistently at <300uA so we gave up that HV supply and switched to the green dumb HV supply.
- Threshold scan failed after 3rd mask stage, coupled to the abnormally low LV current (30mA). Went for access and found that threshold calibration only works with bias off and only after running the threshold calibration the LV current shows some normal value of ~300mA.
- Leakage current uncomfortably high at ~500uA while still only at 600V. The -25C temperature is just not sufficient for running. We took some scoop of dry ice out of the chamber and sprayed into the DUT box which did the trick to get temperature down right away. The leakage current is down to <100uA.
- Ramping up HV slowly while the Lv current is normal after a threshold scan is the only way to get both HV and LV up. When HV reaches ~770V, current suddenly goes crazy even when HV current is <100uA which trips off both HV and LV. So settled to HV=700V as the only way to run.
- Switch to configuration SLAC_LUB1_only (which points to LUB2 335 calibration).
- We can now run and seeing nice streak data but EPICS Caladium displays of temperature etc all dead. Panels for Caladium mover are all flashing error. Mike is out today and Doug came over to help. We rest the IOC but that didn't seem to do much. I recalled the similar incident before needed cycle Beckhoffs 26 power which we did that seemed to have brought things back but many setting appeared strange so that some guessed values were inserted and eventually got it to do something. We then found that driving fine stage Y up had sagging problem again which fortunately is just a matter of going to the fine Y motor advanced settings to enable the hold current and keep enable.
- Beam is ~150 particles/event. This was probably due to primary beam energy 11.49 GeV much closer to our secondary 11 GeV.
- Run 744 is a beam spot playing run with large number of events on a left vertical strip. We cannot go left any further Yfine stage reached bottom limit. After some fiddling we verified we are sitting just inside the tall vertical edge of the beam spot which is the tallest part in Y so that we have the widest streak street in the horizontal direction when viewing the APIX hit map (DUT is rotated).
- Run 745 started from right hand APIX edge map to scan for uniformity. We were moving Xfine stage during the run when reach target for a vertical strip. We stopped in the middle of the DUT when beam stopped.
|
|
|
|---|---|---|
| Run 745 accumulated 3 moves | Run 748 | Run 748 |
Run 746 continued, but we realized that the beam is back to single pulse ! and didn't last for long. We notice the histogram updates were slow and even implied a lower particle rate but looks like that was due to the online monitoring went into some jammed mode and not to respond to any clicking. Had to kill it and restart everything. Run 748 is good (4 mm away from hard stop).
- Beam goes on/off as MCC is playing between single and double pulses.
- We are ready for the low rate run. Asked MCC to turn down the rate. They dialled slit 10 to 0.5mm which initially just dropped everything but eventually managed to stay with that. The rate reads 20 pixels per event on Mimosa (single pulse mode) and APIX looks like 3-4 streaks per event, which looks just about right for us.
- Started low rate data from Run 750 on the left end (x=10-30) while beam is back to double pulse mode with varying relative strengths between the two pulses and sometimes is single pulse mode. Also there are occasional pauses as well. Gas temperature -38C, lleak=305uA. Run ended with 12K events.
|  |
|---|
- Started Run 751, -36C, Ileak=340uA. Moved Yfine up by 4mm but moved more like 8mm. This run covers X=(42 - 62). 12K events. The histogram save for this didn't work. I rushed starting next run before this was complete ?
- Started Run 752, -34C, Ileak=380uA. Move Yfine back -4mm to recover the last strip X=(30 - 50). 12K events.
- 17:20 MCC called asking to taking beam to full 120Hz to primary expt briefly. Ended run 752 with ~5K events. Missing saving histogram.
- 17:26 They returned faster than I thought. Run 753 continue with same setup as last run. End with 7.5K events.
- 17:52 Run 754: Yfine +4mm back to X=42-62 strip again. Ended wtih 9K events.
- 18:26 Run 755: Yfine +4mm to the final strip X>60. Ileak=480uA. Tgas=-31C.
- Access to swap in LUB2 since it looks like the LUB2 runs missed beam spot. Took out the wood chip to get block in contact to dry ice partition and sprayed some dry ice from chamber to DUT chamber. Moved HV control back to Bertan remote control. DUT box Xfine shifted x+28mm to compensate for the removed wood chip. Whole Caladium dropped 2mm to allow beam seeing full DUT height.
- Operator told me no more beam after 9pm. LCLS going to low E. There might be chance for intermitant beam tomorrow afternoon.
- 20:50 Gas temperature is dropping very slowly and only reached -26C. Can get HV to 600V but ran out of time to locate beam spot and they are changing beam energy already at 8:55pm. Looks like this is it for the cold run. Out of beam and out of dry ice.
- No beam until at least tomorrow afternoon.
- Access to dismount the cooling box and putting LUB2 back to the freezer in ESA. DUT rotational stage back on with RTISC4A mounted for possible more beam session. LV=2.0V and fully powered current=0.3A. HV=-80V (reading -86V) and bias current = 1.6mV = 0.16uA. Created a new module type RTISC4A using Seigei's script duplicate.sh to copy from fei4bexample. Threshold calibration from the clone shows large noise and large threshold dispersion. A quick attempt of tuning with fasttune-3000e-10Tot16ke-noisemask.pl got stuck with `subsription disconnected'. Leave this to Martin.
Oct/4
- 8am MCC meeting got a tentative agreement to potentially let us in sporadically during MD in the afternoon (1-7pm) but no guarantee.
- The apparent low efficiency of the RTI module from early data taking is explained by the fact the 225 calibration used at the time disabled very large fraction of the pixels.
- Martin calibrated RTISC2B in the lab perfectly fine with 140e noise, but setting up on the DUT platform also saw large noise. Changing LV supply and HV supply to Keithley, connecting ground wire etc all had positive or negative variations but inconclusive. The biggest effect was actually tuning off the Yfine stage holding current which we kept off and reached a setup that gave noise at 200e and narrow threshold spread at tuning (but broadened some later). RTISC2B was installed on the DUT stage [but we thought that was RTISC4A at the time so that cali directory and run config files were mislabeled as 4A]. This calibration (555) is now the RTISC4A default config. Several row at the bottom and top and edge columns have some problems but most pixel away from the edges are looking fine, with just a few problematic central pixels. Another curious effect is for noise scans, one most of times have two large blocks of rows showing bad noise on every pixel in the block for a probability of ~few x10**-5. Updated HSIO2 firmware didn't change much, but after updating the HSIO2 software, this problem was no longer reproducible.The top block always start from row 256. Since this is a low frequency effect, the setup is good enough for efficiency tests.
- In preparation for the beam run with all components, Timon updated YARR to readout 10 clock ticks to cover the double pulse events.
- While trying to test an auto-trig configuration with Caladium+RTI+FE65P2 together, the YARR server esadutlbnl1 seemed to have stuck and not responding to pings. Had to go down the pit to power cycle. Moved its power line to the first channel of the remote controlled poser strip. However, it looks like this may not help much as the PC still needs to hit a manual botton at front to start. It is back up in any case but we lost the one open window connecting to it. Also noticed from the open side panel of esadutlbnl1 that a fan on the top left corner is not spinning.
- 5pm: BEAM coming. Particle rate very low due to 15.3 GeV primary with 0.5mm slit10. Opened to 1mm. Quickly moved DUT to be in the beam spot. ~2 particles per crossing on DUT.
- Timon reprogramming YARR FPGA.
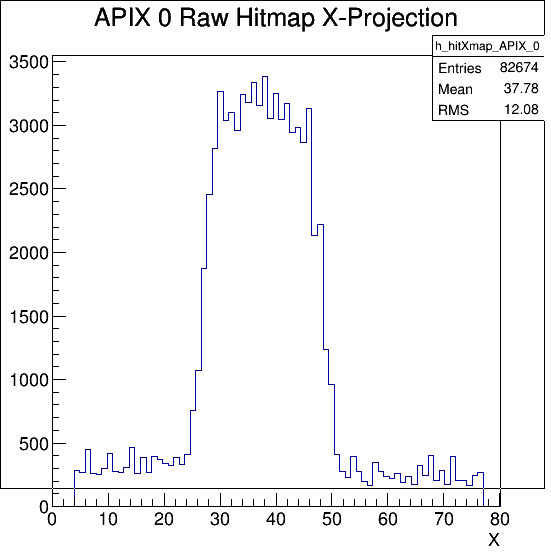
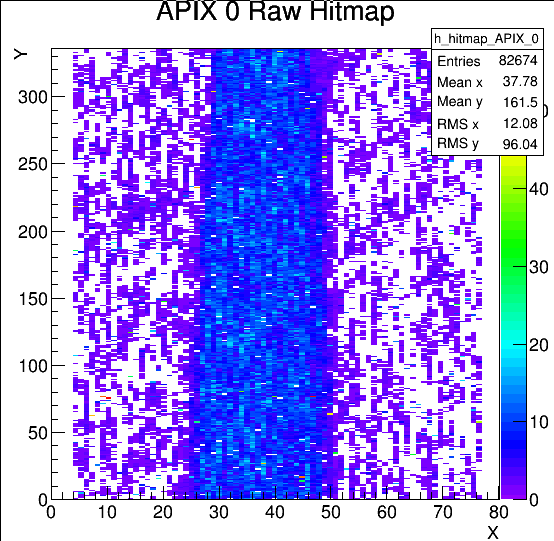
- 17:25 Started Run 763 Caladium + RTISC2B. ~2 particles/event. Telescope beam spot in the lower X half with tallest edge in the middle of MIMOSA. RTI DUT hit region X=45-70, Y=180-280. Ended at 17.59 after 10K events. Really nice clean DUT data with the new config cleaned up noise.
- Restarted Run control to brining in FE65P2 producer and moved telescope by -2mm in X to make the MIMOSA beam spot centered in X which is also the center of FE65P2. Last MIMOSA plane has a slightly low Y spot from the center which may be just fine for FE65P2. Telescope (an FE65P2 with it) will be kept here while we scan around DUT regions.
- 18:10 Run 764 with centered EUDET+FE65P2. DUT Xfine cancelled telescope X move to stay at the same local area as Run 764. MCC took away beam for 10min for primary user. Ended Run 18:21 for 2K events.
- 18:25 started Run 765 with DUT Xfine moved -7mm to center X=15-45. Beam taken away for 10min again for primary user after 10min. Ended run for 2K events.
- 18:48 Run 766, primary energy 15.3->13.5 GeV with 30% higher rate. Ended at 18:58 with 3.1K events for short beam off.
19:03 Run 767, Xfine -3.5mm so that we are at X=0-30 now. Ended at 17:45 with 11K events.
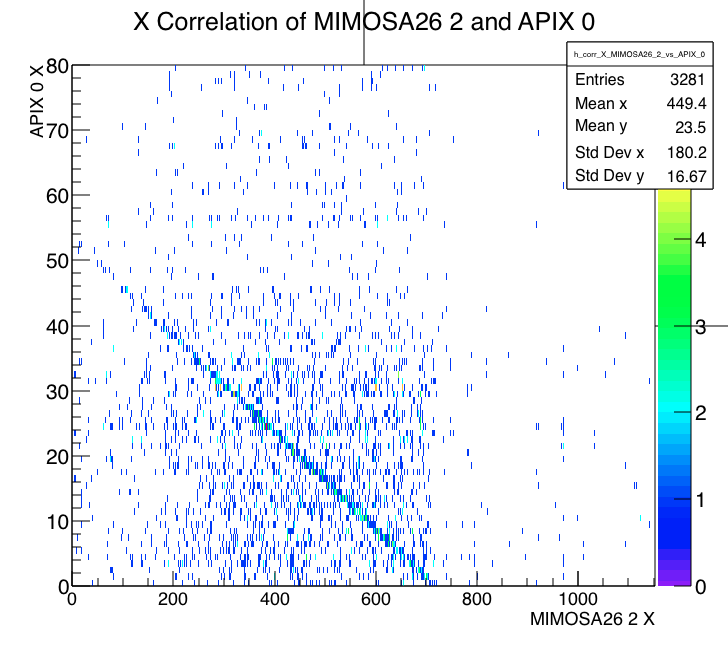
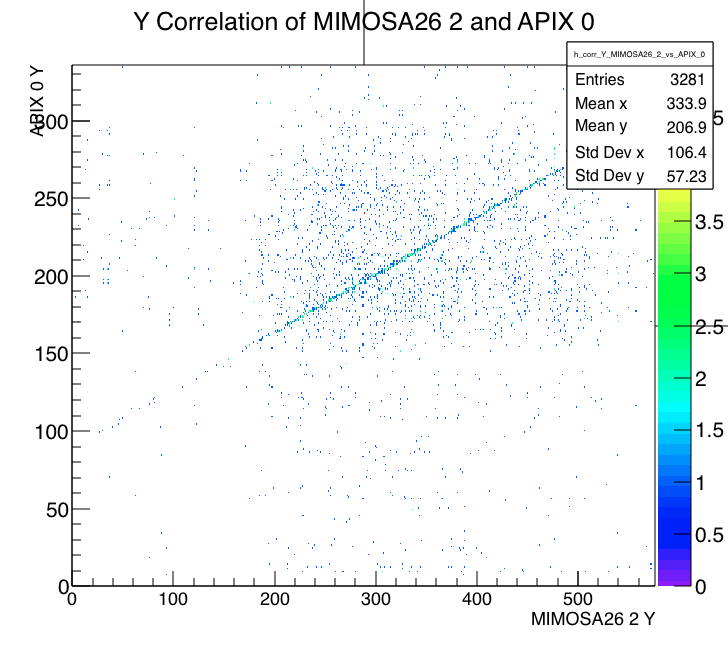
Run 767 RTISC2B (APIX 0) hit x correlation with MIMOSA plane 2 Run 767 RTISC2B hit y correlation with MIMOSA plane 2 - FE65P2 data empty. Dropped its producer to let Timon investigate in parallel.
- 20:05 After a few false start, got SLAC_1dut_FEI4B_RTISC4A setup up without FE65P2, but beam temporarily off. Down for at least 15-20min. DUT Yfine down by3mm to aim for top left corner.
- Asked for access to check FE65P2 HV,LV and module. All seemed to be up. Just pinched the partially blocked FE65P2 module connector which was slightly loose. Timon believes dataflow was OK with module standlaone operation and just without hits. maybe a calibration fixed it. Everything rounded in to the SLAC_1dut_FEI4B_RTISC4A_YARRParasitic configuration [note we mislabeled the config as for RTISC4A but it is really RTISC2B running].
- 21:05 Beam back. Start Run 775. FE65P2 hits now seen ! Only have 10min left. Ended run for ~2K events. Go for high rate for the last 10min.
- Moved Yfine up by 8mm to hit lower part of RTI.
- 21:30 Run 776 opened slit10 to 4mm with particle rate up to ~16/event. We are moving DUT stage during run without stopping for a quick spray of hits everywhere for local cluster analyses only.
21:50 Ended Run 776 with 5K events.
Run start events RTI DUT beam spot DUT clus/evt Notes 763 17:25 10K X=45-70; Y=180-280 1.7 RTISC2B only, MIMOSA beam spot on left half 764 18:10 2K X=45-70; Y=180-280 1.7 FE65P2 joined, but empty. Telescope moved to center beam spot. 765 18:25 2K X=15-45; Y=180-280 1.7 DUT Xfine -7mm 766 18:48 3K X=15-45; Y=180-280 3.1 Primary beam energy 15.3->13.5 767 19:03 11K X= 0-30; Y=180-280 3.3 DUT Xfine -3.5mm 775 21:05 2K X= 0-30; Y=230-330 3.3 FE65P2 hits back after scan. Yfine -~3mm to aim for top left corner 776 21:30 5K Moved all over 16 DUT stage moved RTI module during run. 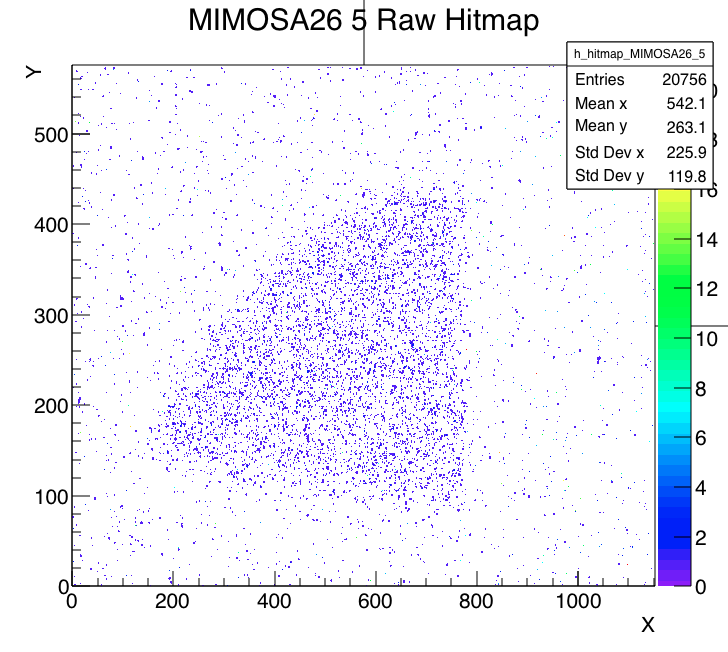
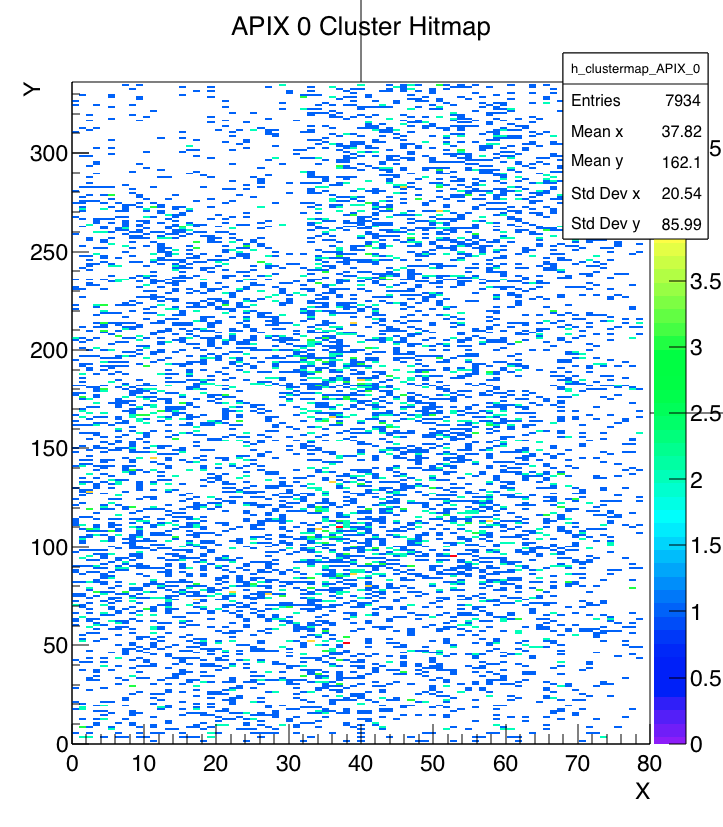
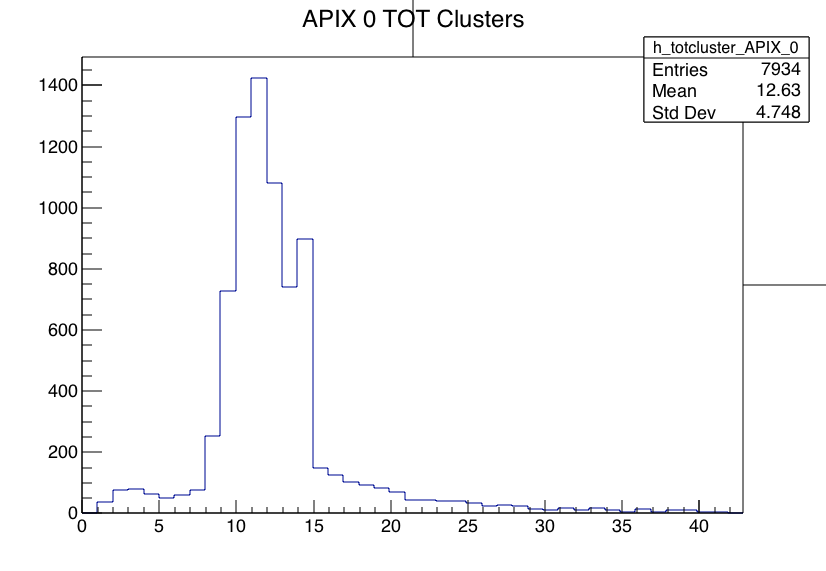
Run 776 hit spray at high rate while DUT stage was moved many times during the run without stop to cover wide range of regions, especially those not in the previous runs. The beam spot location at last MIMOSA plane (5) is essentially unchanged for all the runs today and should also be centered to FE65P2 mounted just behind it. Note the remarkable cleanness of the RTI APIX with essentially no noise hits. 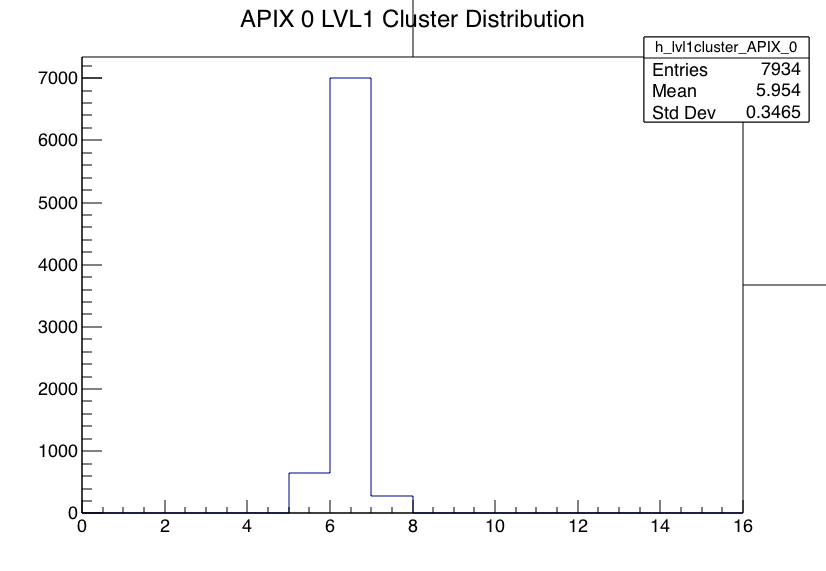
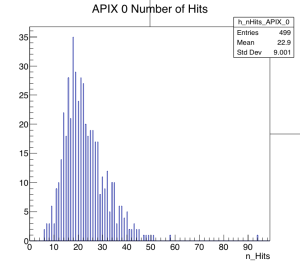
- This is the end of data taking for this test beam session.
Oct/12
The original event log for Oct/4 mislabelled the running RTI module as RTISC4A and even using the calibration directory and Run control config files names as RTISC4A but the actual module was RTISC2B. The notes in the Oct/4 event log were retroactively corrected.