Investigating transfer learning, what can we do with a fully trained ImgNet model?
The idea is to take a fully trained model, like a ImgNet winner, and re-use it for your own task. You could throw away the final logits and retrain for your classification task, or retrain a few of the top layers.
- Preparing the data, vggnet takes color images, [0-255] values, small xtcav is grayscale, [0-255].
- vggnet subtracts the mean per channel
- Codewords are 4096, but look quite spare, not so much variation from lasing/no lasing classes
- Still - looks like it discerns, mean for class 0 and class 1 are 16 apart, vs like .3 or 1 for random subsets
Dataset
The reduced xtcav, took runs 69, 70 and 71, but for run 70 and 71, conditioned on acq.enPeaksLabel >=1 to make sure some lasing was measured. About 20,000 no-lasing samples from run 69, and 40,000 lasing samples.
Preprocess
vggnet works with 224 x 224 x 3 color images. simplest way to pre-process, replicate our intensities across all three channels

ideas
- why don't we take the original 16 bit ADU images and colorize them, to send the image on the left through? Then we could encode our 16 bit ADU intensity in 24 bits without losing information, and each channel would be in [0-255], would this help?
vggnet does not mean center the images, but it subtracts the per channel mean for each or R,G,B, that is it subtracts 123.68, 116.779, 103.939 repsecively from the channels. We compute this over our small xtcav dataset and get 8.46 for each.
codewords
vggnet, http://cs231n.stanford.edu/slides/winter1516_lecture7.pdf, around slide 72, after 5 convnet layers, with relu's and max pooling, produces 7 x 7 x 512 (25,088 numbers).
Then three fully connected layers, the first two are 4096, the last, the logits, 1000 for the imagenet classes. The terminology 'codeword' refers to the final fc layer (which had relu activation producing the output) before doing classificaiton with the 'logits' (ref: http://cs231n.stanford.edu/slides/winter1516_lecture9.pdf around slide 12).
If we plot 4000 of the nolasing, then 4000 of the lasing, you get the following:
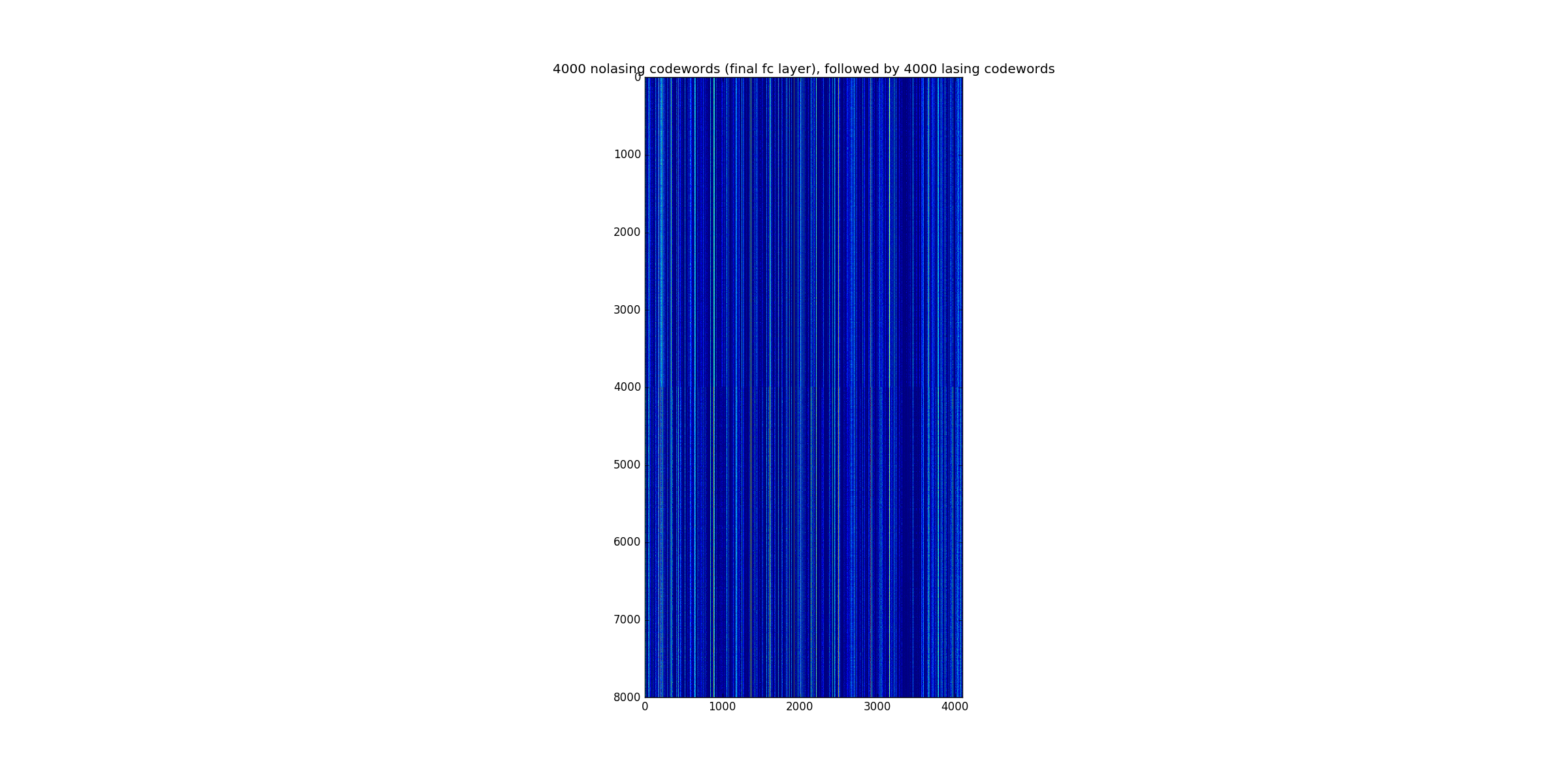
Things to note
- little variation
- dead neurons
- still - definite difference at 4000, appears like enough to discriminate
A linear classifier seems to get 99.5% using these codewords.
Finding the Reference
We are not interested in a good classifier though, our metric is if we can find the right reference for a lasing shot, by using eclidean distance in the codeword space.
Below we take a lasing image, and find the no lasing image with the closest codeword. I looked through about 5 of these, I think they all looked similar. There is a lot of variation among lasing shots, so these images are relatively similar, but definitely not lined up horizontally.
![]()
Things to note
- We could use data augmentation, to get a better match, that is for each no lasing shot, slide it around horiziontally and maybe a little vertically if need be - one of these would definitely be a better match in this case.
Crazy Ideas
- You really want a codeword embedding that puts the fingers in a few separate features are orthogonal to the lasing, maybe there is a way to guide the learning to make this so?
- I see how sparse our representation is, and I think we need PSImageNet - photon science image net - what if we took all the detector images we had, large, small, timetool, cspad, with a 1000 labels of what they are, trained a classifier - that would be a model that could do a lot for transfer learning?