Blog
search
attachments
weblink
advanced
tooltip
Overview
Content Tools
Recent cybersecurity testing of SLAC systems and the impact on Experiment Control Systems
SLAC is undergoing a DOE cybersecurity assessment throughout this year. SLAC IT carried out some preparations for this assessment beginning in March of this year. These preparations included hiring a security testing company, Shorebreak Security, to conduct various cybersecurity-related tests of the SLAC IT systems.
These tests included attempts to gain access to computing devices connected to the SLAC intranet, first from the public Internet, then from starting within the SLAC office network. Our system security and robustness is generally focused around the network being completely closed off except for a small number of explicitly identified ports and systems. Network configuration is complex and the test enabled us to identify areas where the intended configuration and understanding did not match the reality,
The Control System (Software) Working Group (CSWG) engaged with SLAC Cybersecurity to identify especially sensitive networks which would be off-limits during these and future tests, as well as networks which would require special handling in any security testing. Special handling may include coordination with Operations.
Greg White helped to ensure the SLAC Cybersecurity and relevant control system experts met to coordinate and raised awareness of these activities. McCullough, Mark became an excellent point of contact from SLAC Cybersecurity, patiently working with us to balance preparation for the DOE assessment and preventing excessive disruption. Future improvements in communication are planned to further enable all key parties to be aware of planned activities, provide notice of emerging threats as well as a feedback loop to discuss proposed architectures and activities.
ECS had experienced control system disruptions in the past due to port scanning. This disruption resulted in outages as some network-connected components could not handle the unexpected traffic gracefully. Effects can include COTS devices becoming non-communicative until power-cycled, but there are also more dramatic possibilities which may affect physical systems, causing equipment and human hazards.
To address these concerns, additional safety and security measures are being planned and implemented. These measures include improved overall security of interface devices, review of network segmentation to ensure isolation of systems as appropriate, as well as implementing detection methods to identify undesired network traffic before it causes a problem. Plans are also under way, initiated by CSWG and ECS, to add strong cybersecurity to EPICS as a part of SLAC's contribution to the Collaboration. We don’t intend to stop there. As the Cybersecurity team likes to say, security is a journey, not a destination.
Note to all other teams: Purchasing new hardware
We want to remind everyone that anything ordered for integration or inclusion in the control system needs to be listed in the Supported Device List Supported Devices: Long Term Support. There is a process for adding new components to this list but there is no guarantee a component you order will be accepted and integrated. Furthermore, ordering an unlisted component before preliminary evaluation is strongly discouraged. If a nearly equivalent part already exists in the SDL, and there is not a very strong case and specific reason to use the new part number you ordered, then ECS will insist that you return the unlisted component and use a standard, already supported component. If a component is rejected or receives an unfavorable evaluation the same will apply.
The process for new component evaluation can take at least a month, depending on competing priorities, so please plan accordingly. You can begin the process of component evaluation here: Submit a Proposal for New Supported Device.
SC Readiness
We are closing out the effort to move from EVRs to TPRs for all devices expected to run triggered in the controls system. In addition, we added support to receive the LCLS1 timing from the LCLS2 fiber which sits behind the DAQs XPM as well as support for the DAQ partition bit.
PLC Continuous Integration Testing Pipeline
This project kicked off with Jakob Sagatowski, the author of the world-renowned All TwinCAT Blog, and leading expert in all things Beckhoff/TwinCAT, in late March/early April. We're very excited to be working with Jakob to advance our PLC workflows, making it easier to achieve a high degree of quality.
New PLC operating system: TwinCAT BSD
We started testing the new TwinCAT BSD operating system for the Beckhoff PLCs. This OS will replace our Windows Compact Embedded 7 PLC image which is standard on all PLCs. Eventually all of our PLCs will migrate to this new OS, and it will be glorious.
TCBSD is based on FreeBSD, a derivative of Unix, which makes it very similar to our typical linux operating environment. We get many enhancements using TCBSD including:
- bash
- python
- Ansible management (remote management and provisioning of the PLC image)
- Package management for PLC and OS libraries
- Improved potential security
- TCBSD can be virtualized, leading to possibilities for CI pipelines
- Remote recovery of the realtime task; ie., the realtime task can crash terribly and we can still recover the PLC remotely
- etc.
Given the current focus on cybersecurity we expect to upgrade systems on an as-needed basis to TCBSD. All new projects using PLCs are directed to use the new CX5240 with TCBSD as the OS.
LCLSPC-440 - Getting issue details... STATUS
LCLS-II HE
The LCLS-II-HE controls team continues to advance designs for the various instrument areas. CXI instrument PDR review was conducted April 19th. FXT, FEE, and XRT Transport Engineering Peer Review was conducted April 28th. The team is awaiting the committee's report from those two reviews in order to address any recommendation and move forward into the next activity. Common Components EPR is targeted for mid- to late May. The team also finalized the BCR for Lasers with the XES lasers scope changes.
MEC-U
MEC-U Controls has slowly begun ramping up in March and April and will begin to shift focus to laser beam transport controls and infrastructure design. Some notable MEC-U topics from the past couple months can be found below.
Rack Estimates and Tours:
In March and April we revisited SLAC Controls rack and rack power estimates in preparation for Facility's 90% DGPS. We estimated 21 full-sized racks and 14 shallow-depth racks at MEC-U's base scope. With NNSA's additional scope, we estimated an extra 19 full-sized racks and 18 shallow-depth racks. These are still preliminary quantities, but are needed for Facilities to estimate the approximate footprint needed for base scope and for future expansion.
The MEC-U team is also looking forward to meeting with various rack vendors such as Rittal and Steven Engineering in June as well as future suppliers (tbd). The rack visits with Rittal and Steven Engineering will consist of an initial visit at SLAC where we will provide them with a tour to see our current rack implementations and discuss the best path forward to improving this for future projects. The second visit will happen onsite at Steven Engineering in South San Francisco where we will be able to play/tinker with their Rittal rack hardware to obtain hands-on experience with their various solutions. They are encouraging SLAC visitors to bring any hardware we wish to test fit or use to spec out their solutions.
NNSA and DMPL:
The National Nuclear Security Administration (NNSA) sponsors an additional project, the Dynamic Material Properties Laser (DMPL) Project, to upgrade MEC-U's long pulse laser capacity. DMPL would add additional long pulse beamlines to the existing HE-LP laser in MEC-U scope, summing to four beamlines at 1.25kJ per beamline (5kJ total). In April, Controls participated in a cost estimate for this additional scope which will be presented to NNSA in the coming months.
FAC Review:
The Facility Advisory Committee Review is not a critical path review, but it is an opportunity for each subsystem to present their progress, designs, challenges, and risks to experienced personnel who have backgrounds in similar laser facilities and projects. The review is set for mid-July, but our team has begun planning to present several items in order to answer their controls-specific charge question: "Are the deliverables for the Control Systems unified across the three laboratories to enable value engineering and efficient operations and maintenance?"
In order to prepare for this, we are collaborating with LLNL and LLE to compile a deliverables list to present to the FAC to sufficiently answer their question. Tangential to this list, Alex is actively working on an overall MEC-U controls architecture diagram so that we can present this to the FAC and to ensure each lab has a clear picture of the path forward. He will also compile a Software Quality Assurance Plan for MEC-U that will be useful in regular ECS development and operations.
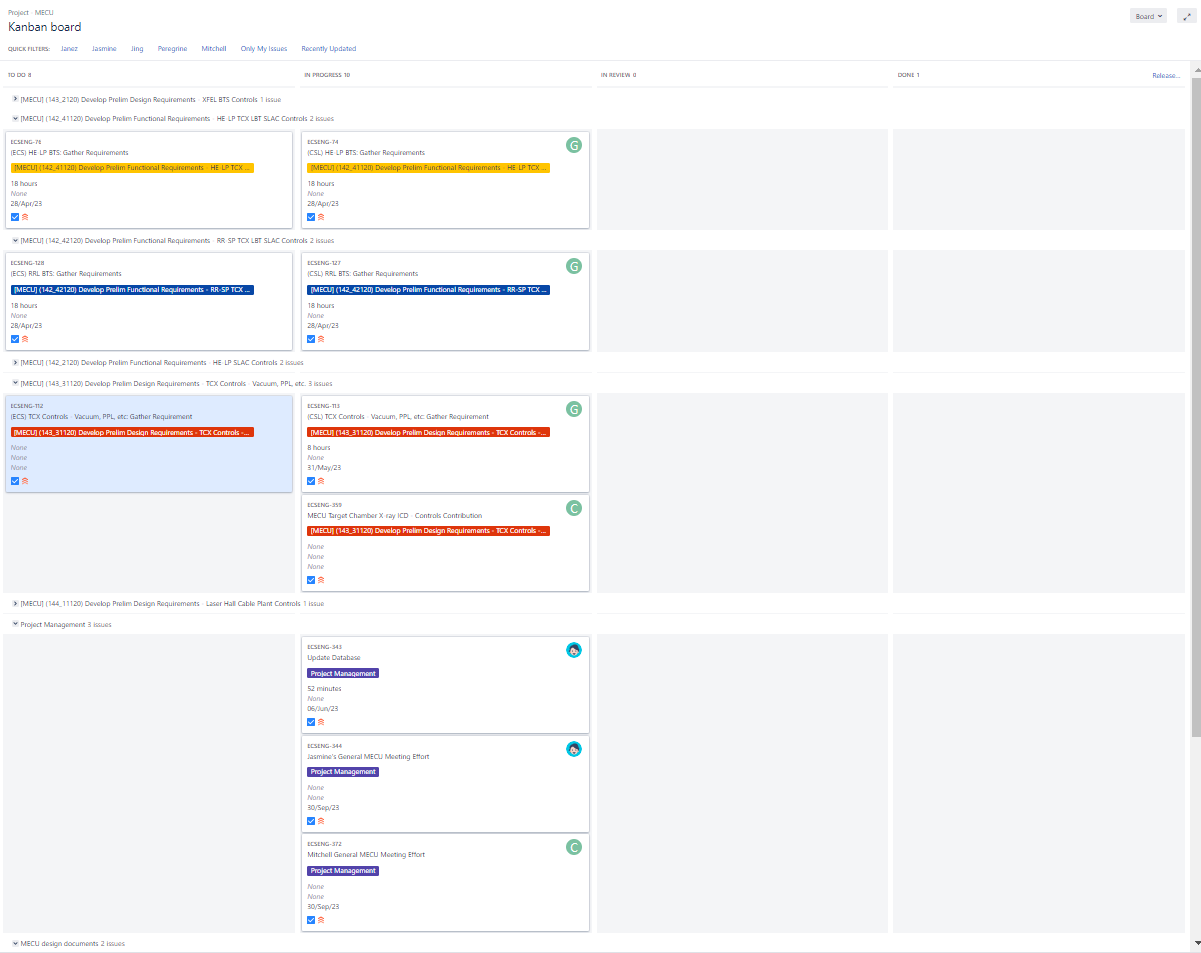
Jira:
We are currently organizing ECS and SLAC CosyLab work through Jira using the MEC-U Kanban board. So far, the board has proven to be effective at increasing visibility of the tasks to be completed at the SLAC Controls Level. Each tasks is organized under an epic, and (most) epics correspond to project activities within P6. The team continues to compile tasks under each active epic and we meet weekly to track progress and identify bottlenecks.
pcds_conda
pcds_conda version pcds-5.7.1 has been released! We released pcds-5.7.0, found a few issues, and then released pcds-5.7.1 a week later.
The intention of this release is to fulfill some long-standing package requests and get us ready for the new run with a stable python foundation.
Full release notes here:
We're preparing for a migration to python 3.10 and pyqt 5.15 within the next few months. This is for both performance and security reasons, as fewer and fewer new package versions support old builds of pyqt and of python. In particular, we're going to quickly run into a problem with openssl incompatibilities as openssl 1.1.1 reaches end of life and no longer receives security updates.
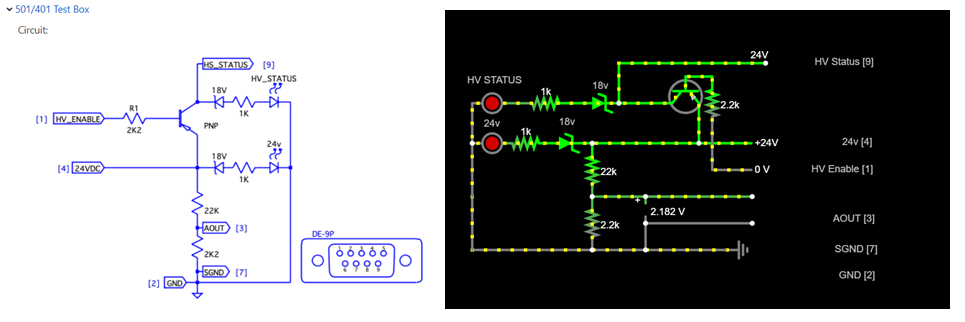
Motion and DC system architecture updates
Purpose
The architecture pages discussed below serve as one-stop references to aid in making design decisions as well as maintaining consistencies within the system.
Page Links
Motion Architecture
The motion control architecture page serves as a guide to using the standard connectors from the motor all the way to the Beckhoff components. The page covers all the standard architecture for stepper motors and encoders. It also covers architecture for specialized motion and legacy devices. The page is still a work in progress as there are new motors added for different applications. Any new motor/encoder is first approved by the Motion SME and the ECS-QA team before being added to the Motion Architecture page.

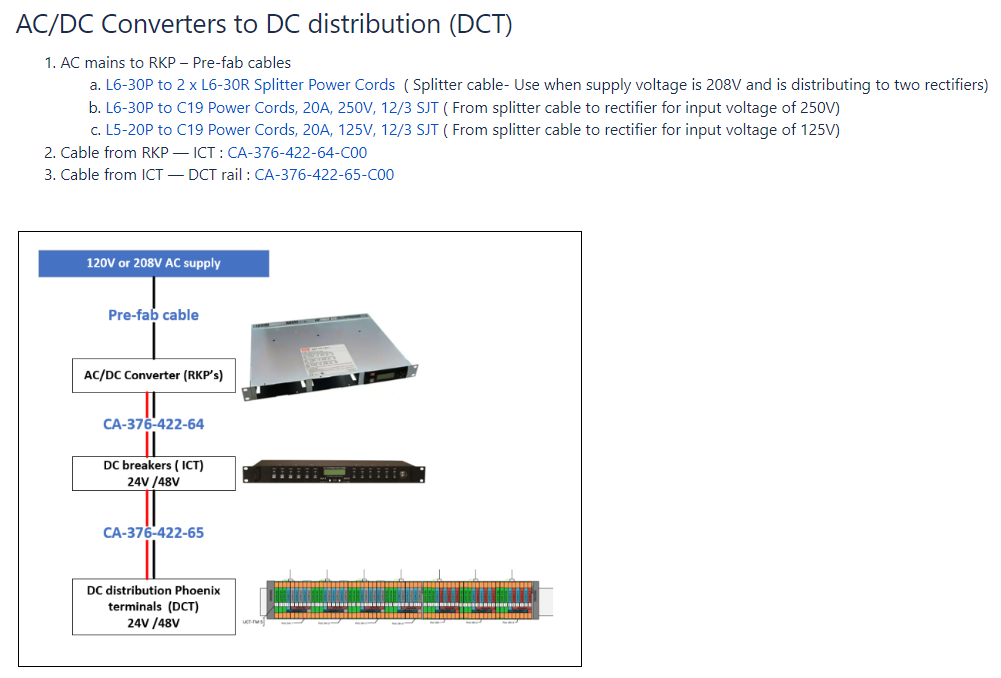
DC architecture
The DC system architecture page consists of architecture drawings depicting the connections from the supply to the end device which can be a component or a DIN-rail. The page covers which cables to use with which components and links to the released cable drawing page. A example of the architecture is shown in the image below.
Stepper Motor Torque Calculations and Serial Impedance Matching
Two new whitepapers were prepared to help resolve some commonly asked questions and points of confusion.
- Stepper Motor Sizing: This page is intended to help determine the pullout torque required for a particular application, given some mechanical parameters. The page also covers the effect that microstepping has on the motor torque, and why it should not be used for increasing resolution.
- Cable Impedance Mismatches: This page is intended to help evaluate the effects of an impedance mismatch between a signal's source, cable, and destination. Some mismatches are tolerable, while others are not. This page provides resources and a built in calculator to help with these evaluations.
Record of Decision regarding Micronix systems
After much discussion and evaluation, a Record of Decision has been written regarding the use of Micronix piezo systems in future designs. The RoD has yet to be finalized, but is discussed in more detail here and outlined below.
- The Micronix MMC-100 has a history of communication issues, requiring specialized controller knowledge and leading to a burden on Operations.
- The MMC-100 control has therefore been deemed EOL (end-of-life) in the Supported Devices List, and is considered to be legacy equipment. This means:
- The MMC-100 may only be purchased to replace non-functional units that have already been put into operations.
- It is strongly suggested that any units that are already in operation be replaced with LTS (long term support) equipment.
- The MMC-100, even if the hardware is already in use in LCLS-I, may not be re-used in upcoming projects such as LCLS-II HE.
Please direct any questions regarding this Record of Decision or the Supported Device List to ECS.
NALMS
The NALMS project has made significant strides in recent months, but the team faced some technical difficulties during the final phase of development. While the NALMS deployment in S3DF Kubernetes is almost complete, there are still some communication issues that need to be resolved. To track these issues, the team has created an epic ticket on Jira that outlines the remaining tasks that need to be completed in the coming weeks to achieve a full deployment.
Despite these challenges, the project has reached a prototype stage where it is ready for use, and the team is eager to receive feedback from users.
A recent demonstration with major users Bill and Stefan for Vacuum and GMD and XGMD fields was successfully completed.
If you're interested in trying out NALMS, see this dedicated web page for installation.
You can find more information about NALMS on Confluence, including a description and an explanation of the NALMS workflow. The team is committed to delivering NALMS in the next weeks.
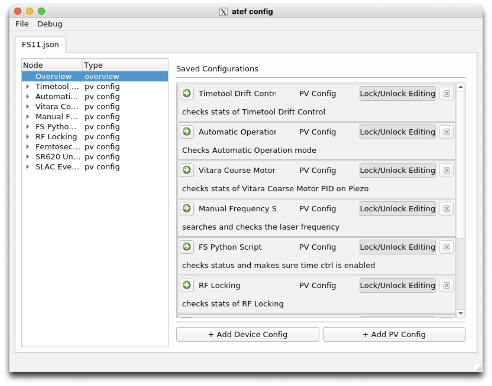
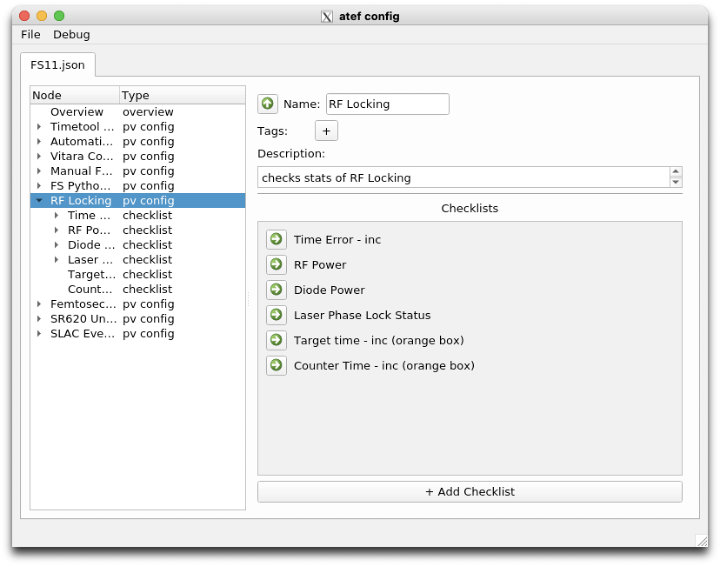
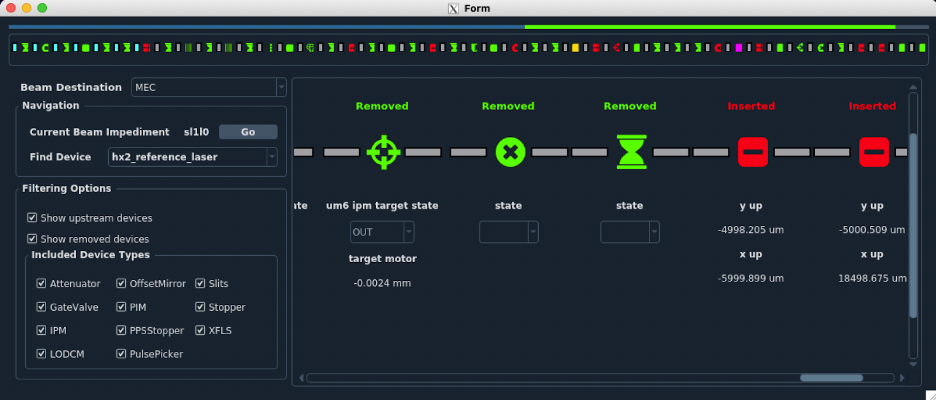
ATEF
ATEF continues to make steady progress toward becoming a useful tool for guiding and documenting checkouts.
Since the last time it was featured in the newsletter (Aug/Sept2022), ATEF has received a reworked GUI, added report generation, and begun implementing active checkout support.
What does this mean?
- GUI rework: ATEF now sports a GUI that not only allows users to edit and compose their checkouts, but also run them. The GUI is being expanded to support active checkout steps as they are added.
The passive checkout GUI also now supports more complex groupings of passive checks, allowing checks to be grouped by device, PV, or tool type. - Report auto-generation: Reports can now be generated from completed checkouts. These reports summarize the checkout settings, results, and collected data if applicabale. As more checkout steps are added, their corresponding report output styles will also be updated.
- Active checkouts: In contrast to passive checkouts, active checkouts involve making changes to the controls system (setting PVs, moving motors, etc). This is the current focus of our development, so please be patient with us!
For more information, see the atef summary page.
ATEF is still in pre-release, but if you are interested in testing it out and providing feedback on its functionality, let us know!
Standards, Guides, and Quality Assurance Plans
Ken Lauer Alex Wallace Federica Murgia
MEC-U and HE are driving ECS to develop and release a set of quality assurance plans that will document our engineering, build, and test processes. This effort will be tracked in this epic:
LCLSPC-705 - Getting issue details... STATUS
We may aim to validate these plans at the lab-wide level if possible.
Github Enterprise
Github Enterprise has been approved by the SLAC Engineering Council and the Controls Software Working Group to become the lab solution for source code management. We are in the process of receiving cybersecurity approval of the platform and will proceed with a trial and full licensing as soon as possible after that.
More details about the trial and how to use GHE will emerge in the coming months. Very exciting!
EPLAN and Teamcenter
We're planning to integrate Teamcenter PLM and EPLAN. This integration will bring several advantages, such as improved efficiency through automatically reflecting changes made in EPLAN to Teamcenter, better part tracking through Teamcenter's BOM, improved lifecycle management with a complete view of history provided by Teamcenter, and enhanced document control through specific repositories and tags.
Furthermore, Teamcenter offers a document control that will check all the blocks (check, revision, approval) and then release the drawing in order to have always a complete ad update version. Moreover, after the release, only an official revision can modify the drawing, ensuring consistency of updates.
The Teamcenter admins will ensure that the integration module is updated with EPLAN to maintain compatibility and optimize system performance.
To properly manage Teamcenter content, several tutorials are accessible with a Teamcenter license. We'll start familiarizing ourselves with the software soon.
Several meetings are scheduled to present the last version of Teamcenter to the ECS group and to start integrating Teamcenter and EPLAN.
UI/UX development process and systems engineering
Some new considerations are being made in the area of UI/UX development. In particular the team is considering new software that allows for quick GUI wireframing and mock ups. These methods originated in the form of pencil and paper and enabled a designer to quickly deploy and demonstrate the flow and appearance of an application. In this way stakeholders could quickly identify areas of the GUI that were confusing and failed to adhere to common GUI heuristics such as the ones listed here: https://www.nngroup.com/articles/ten-usability-heuristics/.
This pen-and-pencil wireframing method has made the jump to modern-day web applications. One can find a multitude of easy-to-use applications with a quick Google search.
These tools not only enable a designer to create a wireframe, but also lets the stakeholder join in. What's more, multiple users can edit a wireframe at the same time!
Here's an example of a Figma session with a quick mock up for the Compound Refractive Lens.
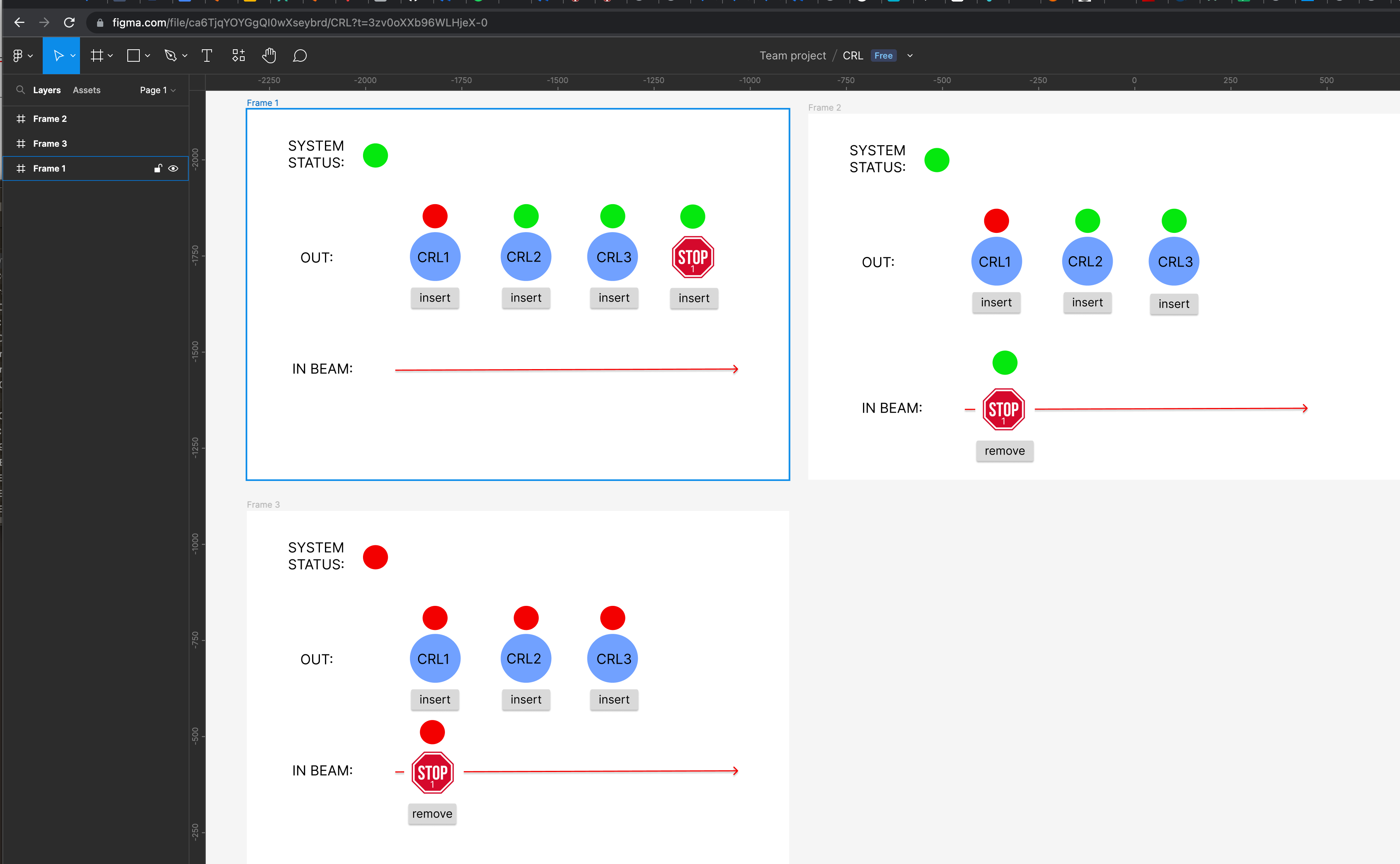
We’ll be evaluating a number of prototyping tools and processes, if you have thoughts about this topic let us know!
Hannover Messe
A detachment of ECS engineers headed to Germany April 17-21 to attend the Hannover Messe, an industry automation fair. In addition of getting to know the latest developments made by some of our usual suppliers (Beckhoff, Phoenix Contact), the team also investigated solutions for wireless sensors, power supplies, and new motions and position measurement systems.
Some highlights, in no particular order:
- Wireless I/O link by IFM

- Beckhoff EJ terminals solution for motion systems

- Ubuntu Core real-time engine
- JVL intelligent motors
Deployed EPICS IOCs and module usage statistics
To view information on all currently deployed EPICS IOCs, see the following document:
EPICS IOCs Deployed in IOC Manager
To see statistics regarding EPICS modules and versions, see the following document:
SLAC IT's Newsletter
We'd like to highlight the SLAC IT newsletter and site and give props. It looks great and has a lot of useful information. Check it out!
https://it.slac.stanford.edu/news
Hello, Goodbye
We had to say goodbye to Ortiz, Jose on May 1st and wish him and his family all the best for their lives (back) on the east coast. He will remain with us on a casual basis to ensure continuity for DXS/XCS.
Hill, Bruce officially retired on March 24th. He still works casually, but please go through ECS to request work that he used to take on!
On the plus side, we hired Josue Zamudio as an SEA. He started March 17th.
Jira Results
to
Introduction and Executive Summary
- We consider this inaugural forum a success.
- We liked how issues and topics were raised and we could get immediate feedback and ratification of the discussion.
- It was a good format for broadcasting the roadmap.
- We anticipate the forum as being a productive augmentation of the newsletter for communicating progress in our various campaigns/ goals.
- We plan to do it again.
- We think it is a good idea to host a forum on a quarterly basis. In-between runs was also suggested, and we may change to this cadence if we hear from more people this is a better option.
- We will send out a targeted survey a week in advance of the next forum to collect information we can use to drive the conversation.
- Topics in this forum included UI/UX QoL improvements, Experiment setup reconfiguration/ flexibility, SDL process, and ongoing stakeholder feedback.
- A number of specific issues that were raised were filed directly into GitHub Issues.
UI/UX Quality of Life Improvements
- Forum opened with discussion of LUCID and Typhos, procedurally generated screens (as opposed to artisanal screens).
- Screen space efficiency was raised as an issue, which ECS has been aware of for some time. The feedback on this issue gave us a few new ideas for how to tackle the problem.
- We believe there are some worthwhile improvements that could be prioritized.
- Procedurally generated screens are considered advantageous for a number of reasons including reduced long-term maintenance costs, increased fidelity to the as-built system configuration and consistency in function between UI and command line interfaces (CLI).
- Artisanal screens are considered inevitable as it may be in some cases easier to achieve a more dense and intuitive arrangement of readbacks and controls this way. However, we strive to make artisanal screens unnecessary.
- We believe 2023 will include opportunities for improvements in the UI to be prioritized and look forward to reporting progress at the next forum.
Experiment Setup Reconfigurability
- Feedback regarding the reconfigurability of the L2SI systems, and the proposed designs for HE was discussed.
- ECS has been exploring the possibility of user-deployable motion control systems since XPP designs for HE proposed them earlier this year.
- Such systems were purposefully excluded from L2SI designs. This was because an overarching goal for L2SI was to do more with less by leveraging automation. System stability was considered essential for automation to work and thus L2SI intentionally focused on building hutches without allocations for user reconfigurable systems.
- Despite this, the ECS architecture inherently has the ability to be changed or extended as necessary.
- ECS will continue to look into technical solutions to this challenge, but will refrain from any implementation until a larger discussion regarding the nature of operations at LCLS because how LCLS intends to handle ad hoc changes to experiment plans, and experiment planning is still unclear.
Supported Device List
- Piezo actuators play a key role in high-precision, in-vacuum (and air), positioning for a variety of applications in LCLS systems.
- There are at least two piezo actuator “makes” deployed at LCLS, SmarAct and Micronix. PI may also be deployed, but not as prevalently.
- When the SDL was first published in January of 2022, ECS had marked the Micronix line of piezo actuators (and controllers) as end-of-life. This was done to encourage consolidation of makes and models, and because Micronix controllers allegedly have a history of issues with reliability.
- The forum discussed this change, and how SDL statuses should be handled in general.
- More discussion is needed, but there are some outlined processes that will be followed for future changes in status, including additions. In short the process will include collaboration between identified subject matter experts from both mechanical engineering and controls. It remains to be determined how stakeholders from SRD will be included in this process.
- More assessment of overall consolidation probably ought to be done. Consider that much of LCLS was pieced together without an objective to minimize the number of makes and models in our systems. We might find that we truly have duplicated solutions, each with their own idiosyncrasies.
Ongoing Stakeholder Feedback
- It is vital that ECS is responsive to stakeholder feedback, and for stakeholders to know how their feedback is processed.
- Spent some time in our close-out session discussing ECS processes for stakeholder feedback.
- To understand how stakeholder feedback is acted upon one should understand how ECS is structured internally. ECS’s internal macro-structure consists of two departments, Platform Development and Delivery.
- The idea is that the Delivery team consists of points of contact that are meant to represent the wider stakeholder crowd.
- We think these Delivery PoC may be the best way to accumulate and cohere stakeholder feedback for Platforms to act upon.
- We have determined we need to reinforce our internal interfacing between PD and Delivery through a few changes, and intend to work on this going forward.
- Therefore, we want to continue to encourage stakeholders to work through their Delivery PoC to capture feedback, in addition to filing Jira issues (as Jira issues are where all feedback must be recorded in any case).
- When appropriate, PD SMEs will be engaged to work directly with stakeholders to ensure we have the best communication possible, while at the same time maintaining PoC engagement to ensure coherence with wider facility needs.
SC Readiness
The LCLS directorate held a Run 21 readiness workshop in early September to review preparations for the arrival of the LCLS2 beam. After the workshop, LCLS formed an SC Readiness taskforce (Delta Force) to tackle issues, risks, and scope raised at the workshop. The effort is ongoing and we're having a blast!
ECS created a Run 21 readiness dashboard for the workshop you can review here:
https://jira.slac.stanford.edu/secure/Dashboard.jspa?selectPageId=14380
Any controls/data/timing/IT issue that is considered essential or important for the arrival of SC beam, or SC commissioning, KPP measurements, or validation measurements is labeled with an sc-readiness label and this makes it appear in the dashboard.
Supported Device List Update
We officially completed the Jira epic to update the SDL after nearly a year. Please refer to the SDL for system design and support.
One item of note is the status of Micronix piezo actuators and drives. Due to some concerns over reliability, these drives have been marked as EOL, meaning they are not approved for new designs, nor approved for purchase for new assemblies. Existing configurations are still supported, as is purchasing replacements for existing configurations. For more information contact Tyler Johnson .
TXI installation for RP air attenuation test
TXI will conduct RP testing on the HXR line in March - April 2023. This test is to verify air attenuation models at different repetition rates.
During this summer shutdown, we started controls work in FEE and TMO hutch for both (HXR & SXR) TXI lines. This includes design, some procurement, panels/cable fabrication, installation, testing and PLC/IOC software work. All the Vacuum and Motion PCLs are setup and both TXI lines in FEE area are online with Pydm screens.
TMO hutch installation is still ongoing and we plan to have that work completed by end of this year depending upon the hutch access during upcoming PRP experiments and other related work.
Motor soft-limit display issues
A long-standing, GUI bug, causing inconsistencies between the display limits, the limit protection in the python layer, and the limit protections in the motor IOC, has been fixed. This issue occurred for specific motor types due to python GUI/display related classes failing to notice underlying limit position updates.
This bug is caused by differing behavior in how certain motor IOCs update their limit metadata and possibly how this metadata propagates (or does not propagate) through the channel access gateways.
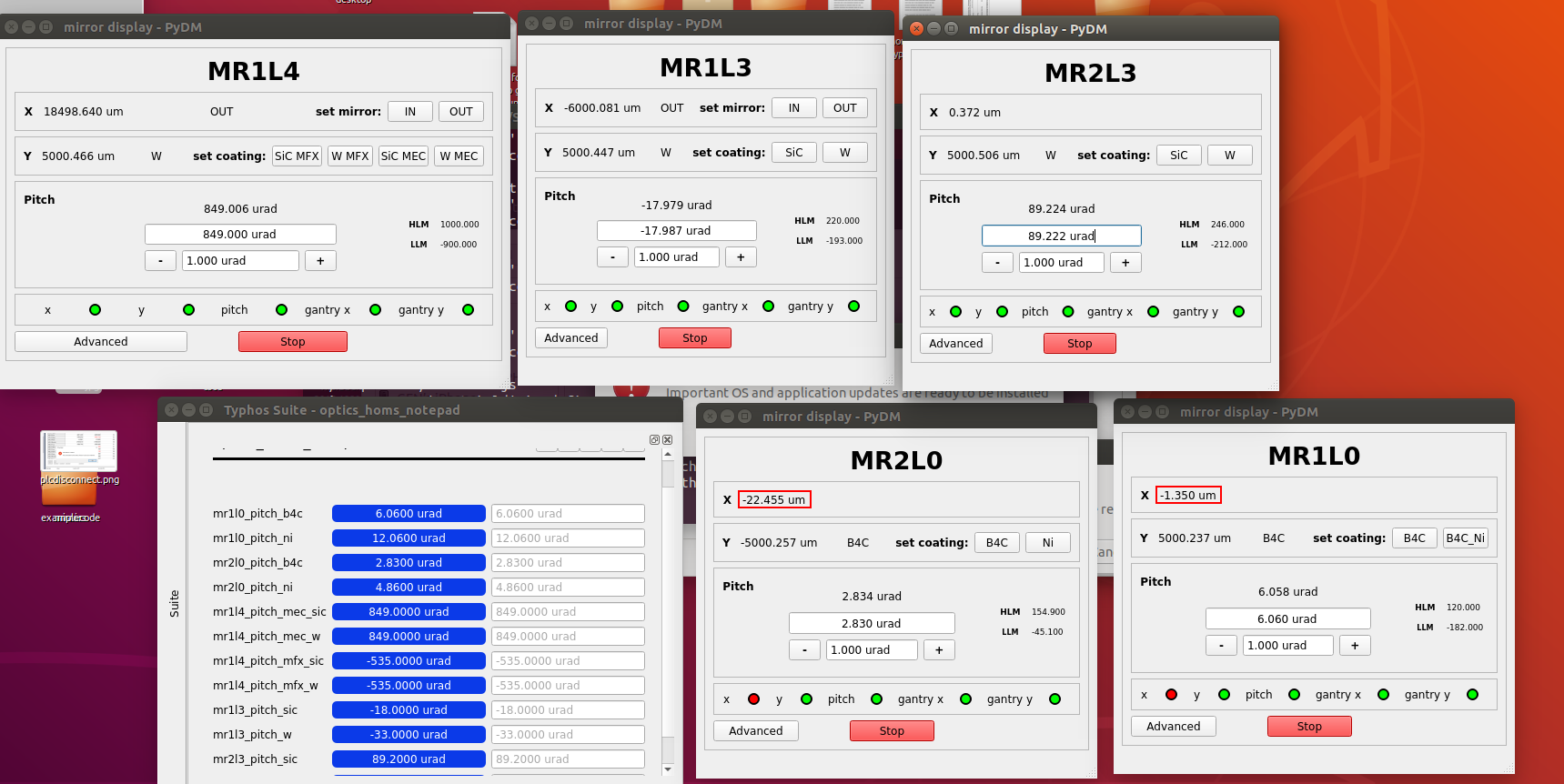
Automatic pitch adjustment for offset mirrors
Offset mirrors will now auto-pitch along with the ability to select a coating position. Desired pitch positions based on hutch and coating can now be saved in a notepad. When users request a coating, the mirrors will respond by moving to a preset coating position and then auto-pitching.
Better power supplies for 901
Federica Murgia All din-rail power supplies in building 901 have been replaced by sealed, desktop power supplies for better compliance with electrical safety.
The new 24V desktop power supplies are currently stored in office 113 F, and they can be used only for the racks in building 901.
Each power supply comes with a power cord and a 24V power supply cable 3ft long (they are all labeled).
Note: each power supply can handle more than one PLC, but the current range is 0 ~ 11.67 A.
You can find more information about the first power supply inspection and the new power supply on this confluence page.
Please, update the equipment tracking sheet if you take one of them.
Improvement of python environment testing
It was noted recently that the Python environments update too dramatically from release to release. Our python environment is a mix of SLAC+ECS developed libraries in combination with other open source software (OSS) projects. We adhere to a policy of rigorous testing and refreshing all dependencies when we update our own libraries, but it has become clear the pace of external community "unexpected bugs" far outpaces our testing capacity.
We've added more local testing steps and have rewritten our update scripts to minimize dependency updates. Hopefully this brings us to a state where most bugs introduced by an environment update are minor and mostly our own creation, rather than being introduced by an external OSS contributor.
Imaging systems and network impact analysis
We've recently looked into some theoretical limits for running imager systems (GigE cameras) in general and on our IT infrastructure. The methods, reasoning, and conclusions can be browsed at Understanding Camera Network Traffic Limits.
In a related note, TMO triggered GigE camera acquisition has seen stability issues as we approach these theoretical limits. These issues can cause dropped frames which is problematic for DAQ data. Efforts to stabilize these is ongoing.
Ion Pump QPC Controller Issues, Improvements Incoming
We contacted Gamma Vacuum regarding issues with long-run (cable distance) ion pump QPC controllers and their noisy pressure readings in August. This led to a meeting with Edwards Vacuum, their partner company, where we discussed a temporary solution to update the controller firmware with an unreleased version. This unreleased firmware had been deployed to solve similar issues in Germany and the AD at SLAC. In October, we updated the firmware on B940:009:R03:PCI:01 inside of the FEE. This improved the stability of the pressure reading on two of the three working ion pump channels, however there was still some variance in the third channel.
Another ongoing issue is the inability to run all four QPC channels at once without error. When all four channels (and sometime even three or two) are run simultaneously the controller will eventually trip off all channels due to an error. This topic was discussed with Edwards as well, but the fix is to replace the CPU chip in each QPC or to procure completely new QPCs with necessary hardware updates and RMA the controllers with issues. All QPCs with the 4-channel error must be sent back to Edwards so that they can replace this chip, but this is not possible at the current time with supply-chain issues and critical dates for operations. We are pushing to get new QPCs, which were ordered last year, to be prioritized in their backlog so we can replace these controllers and send the defective ones out to be fixed.
Finally, there have been multiple problematic ion pumps on the HXR line that have been delivering lackluster vacuum levels for months. One pump has been replaced. After a long RMA process due to the aforementioned supply chain issues, the controller for all of these pumps was swapped for a freshly RMA'd one. While the pumps are able to stay on consistently now, their pumping capacity seems to remain sub-nominal. They have been hi-pot tested and the worst performing pump was determined to fail the hi-pot test. This debugging process is ongoing.
LCLS-II-HE
The HE Controls team have, as of early October, completed PDR for 4 out of the 7 L5 WBS areas: XPP instrument controls, MFX instrument controls, FEE and XRT area and Common Components. Congratulations team! Preliminary design activities for the other areas are on track with good engagement from the team. Activities for 3B reviews and drilldowns preparations are in progress.
Validated Machine Configuration Database Project Update
Alex Wallace Machine Configuration Database
We have a concept demo up and running. We still need to find some bandwidth to polish the frontend, and then we'll be ready for a release. Aiming for early November.
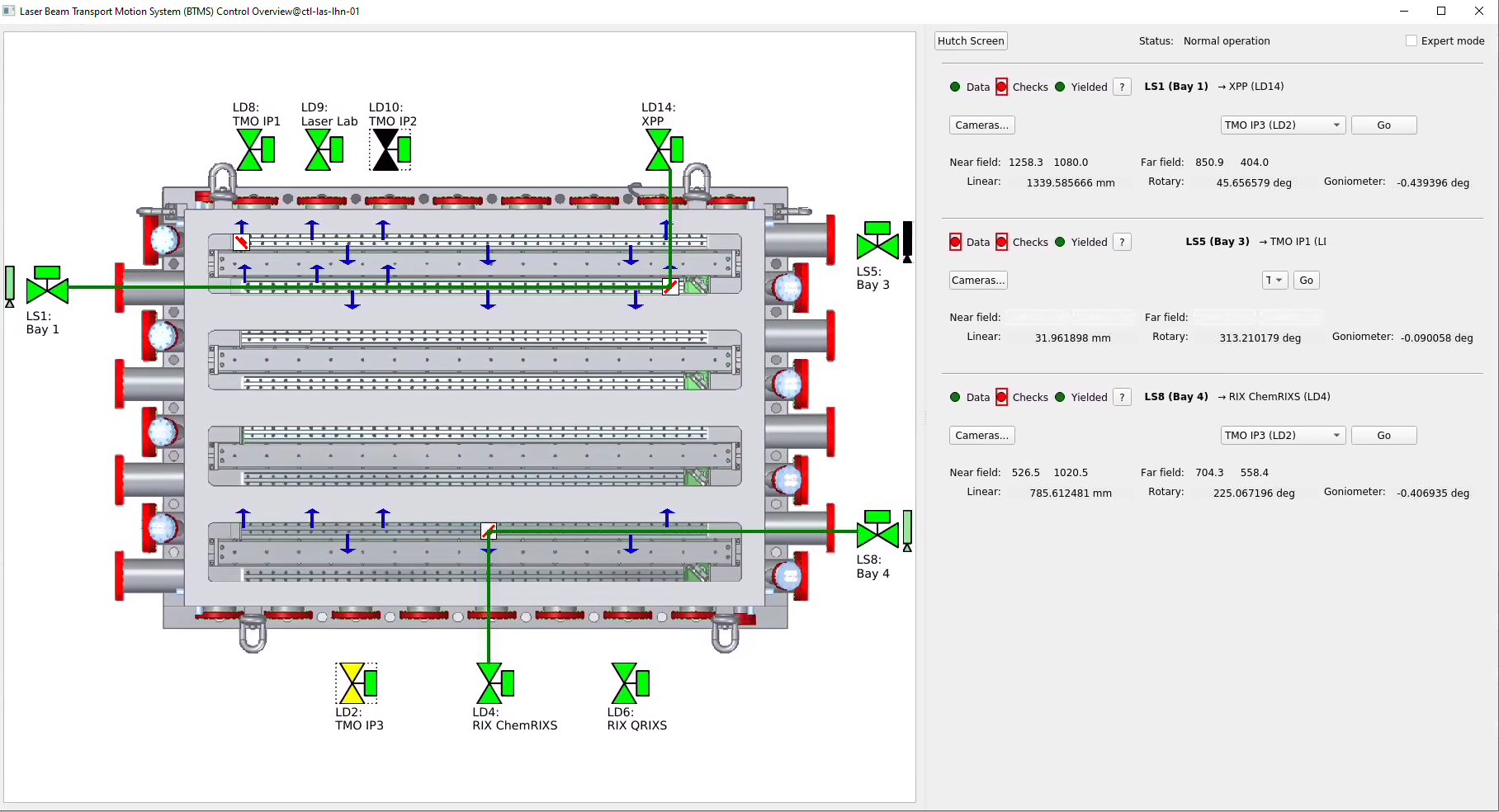
Laser, Beam Transport System (BTS)
The Beam Transport System connects the NEH interaction points with the laser hall laser sources through an easy to operate, and safely interlocked interface. A new motion control screen and back-end system was developed and deployed in September. This system includes configurable, archived values for nominal beam delivery positions from every laser source to every laser destination, automated source → destination motion control, and protective logic checks to protect against equipment damage. The system determines laser destination based on motor position, making the active laser destination available as PVs. The GUI provides graphical feedback of motor positions, as well as estimated beam delivery based on system state (see the green lines below representing the approximate beam path).
EPICS Collaboration
The 2022 EPICS Collaboration Meeting took place this year in picturesque Ljubljana, Slovenia.
The meeting was hosted by Cosylab, with the workshops taking place at their headquarters and presentations at Jožef Stefan Institute.
There were over 100 attendees (in-person and virtual). Of the in-person attendees, 32 were external to Cosylab.


Several SLAC and local Cosylab engineers were fortunate to be able to join the meeting in person this year.
The first day was dedicated to an EPICS 7 workshop, run by Kay Kasemir.
The second day of workshops included Timing (Jukka Pietarinen), Build and Deployment (Ralph Lange), and Motion Control (Torsten Bögershausen).
SLAC talks included Current and Future Development of PyDM (Yekta Yazar) and whatrecord (Ken Lauer).
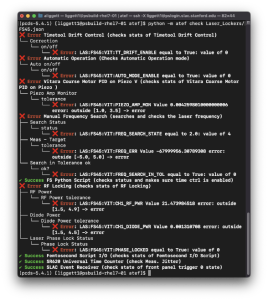
ATEF
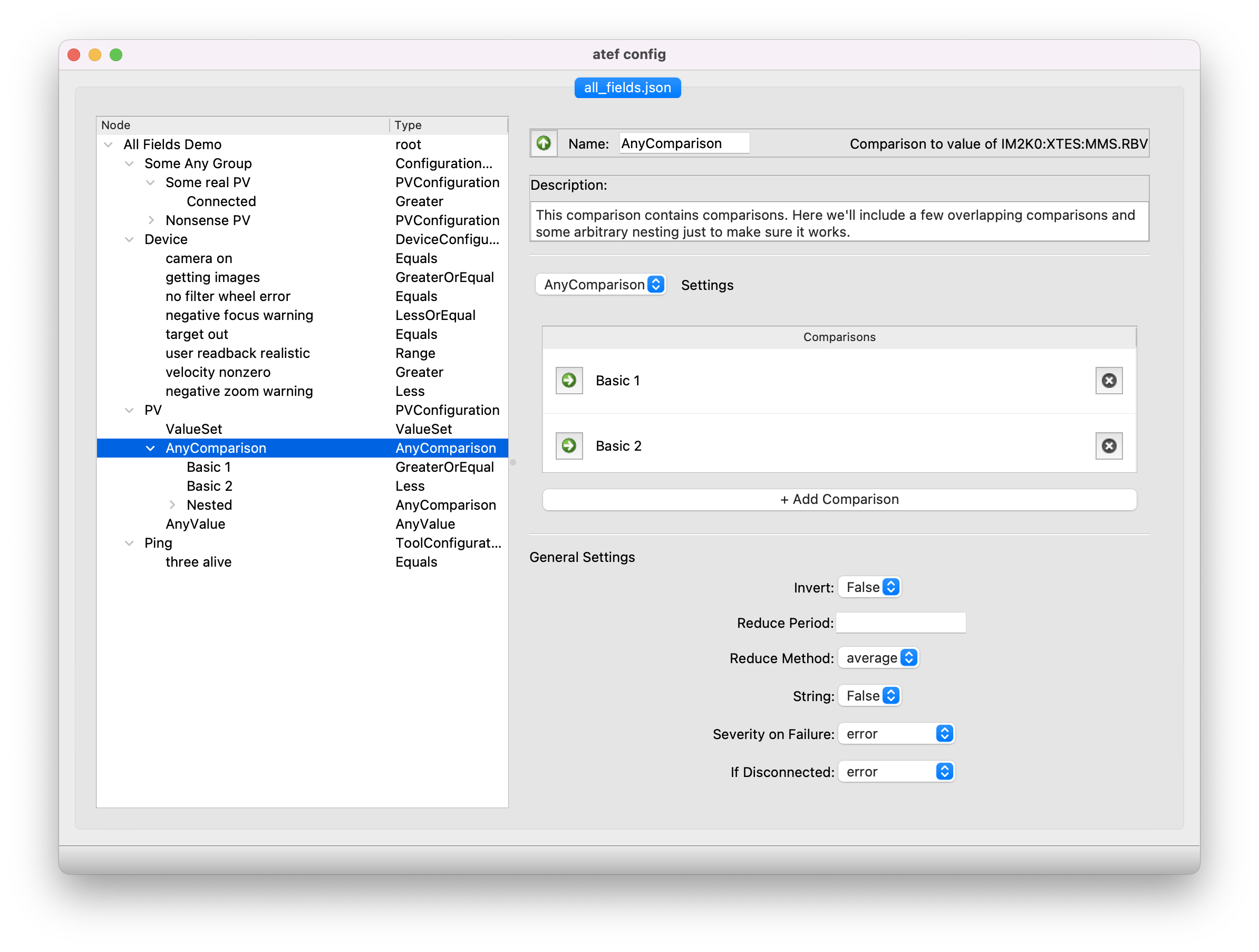
Since the last newsletter, the passive check configuration scheme in ATEF has been reworked. ATEF now supports user-specified groupings of passive checks.
The configuration GUI (graphical user interface), pictured above, is currently being reworked in order to be able to support this new and flexible format.
LY45
LY45 (CVMI with complicated new configuration) was delivered successfully. Control did lots of work including adding new manipulator in the beam line, moving two piezo motors from LAMP to CVMI, redefining CVMI six motion axises, rearranging CVMI vacuum design. All works very well and TMO decides to keep the new manipulator into the beam line and adding two more piezo motors into CVMI gas jet later because the good experience of LY45.
Lightpath
Lightpath is coming along nicely. As the major work on the UI approaches completion, our focus shifts to updating existing devices to fit the new lightpath interface.
Previously many devices did not ready themselves for lightpath, or did so half heartedly. Most devices were straightforward to update, with some more complicated devices
requiring more investigation (eg. the various offset mirrors). We are doing our best to update and test these devices thoroughly, in order to minimize disruptions during deployment.
With the changes to the lightpath interface, we have updated the package documentation to include information on what lightpath expects and how to ensure your python / ophyd device can be read by lightpath. (https://pcdshub.github.io/lightpath/)
A lightpath demo has been set up, try it by running: (and let Robert S. Tang-Kong know if anything doesn't work)
/cds/home/r/roberttk/lightpath_demo/test_lightpath.sh -h
For basic usage notes: Lightpath basic usage
Hello, Goodbye
| Jasmine, Nguyen joined the ECS Platforms Development team as a Staff Engineer 1, Controls System integrator, with a previous background in industrial controls. Studying mechanical engineering, mechatronics engineering, and sustainable manufacturing, Jasmine contributed to the SLAC sponsored, Spatial Alignment With Machine Vision Robot project at CSU Chico. When Jasmine is not on a rock, they can be found at a skatepark, ice rink, or ski resort. |
| Aron Rezene is a new intern from Washington, DC, joining the LCLS Exp. Control Systems Delivery Team. As an undergrad in Physics at SUNY Oswego, he fancied extracurricular studies in DSP & control systems engineering along with C++ to complement the experimental practices used in physics research. His personal interest include embedded systems and computational physics and before joining SLAC, he served as a test intern measuring thermal impedance of SiPh lasers at the LiDar startup Aeva. His indoor hobbies include chess and watching Arsenal matches, but he prefers to spend free time outdoors, playing soccer, catching up with friends, or going for a hike. |


We waved goodbye to Tyler Pennebaker in August as he prepared to set off for graduate school at UCSB. You can read his kudoboard here.
Jira
If you can't see these Jira plugins, please log into Jira/ Confluence. If you can't log into Jira, send mail to apps-admin@slac.stanford.edu and ask to be added to Jira.
Getting issues...
Introduction
Do us a favor and give a thumbs up or leave a comment to let us know you saw this newsletter! (at the bottom of the page. If you don't see it, try logging into Confluence, windows credentials)
Check out the RIX newsletters when you get a chance as well!
PMPS UI Fixes and Updates
We had a few fixes and feature updates for the PMPS UI diagnostic tool in July.
- Fixed a bug where the rate and transmission readbacks on the line beam parameters page were showing the live totals instead of the controlled readback value, causing some confusion.
- Add a default "Beam Permitted: False" filter on the fast faults page. This makes the GUI load slightly faster because it doesn't have to render all the fast fault widgets on load, and it lets us get to the most important view first.
- Disable the grafana web views for now, these are causing crashes on operator consoles.
- Rearrange the "Arbiter Outputs" page that was previously difficult to see which status was connected to which PLC.
Hutch Python and Conda Updates
The following environments were released during May, June, and July:
- PCDS Conda Release Notes: pcds-5.4.0
- PCDS Conda Release Notes: pcds-5.4.1
- PCDS Conda Release Notes: pcds-5.4.2
pcds-5.4.2 is the first environment with "gentler" dependency updates to minimize the potential for picking up unexpected behavior on update.
Note that any applications using pcds-5.3.1 should update if they plan to use hutch-python in an experiment setting. There is a bug in this version that can lead to dangerous results where the history of separate ipython sessions will get mixed during execution, so someone else's "move" command can end up in your history and it is very very easy to accidentally run their command instead of re-running yours.
Python Performance Project (Ongoing)
We've been working on tracking down the reasons why various Python apps are slow to load (vs. expectations) and trying to optimize what we can. To this end, we have already found a number of potential improvements and work is ongoing. Some of these are tricky because, while startup speed is important, having a design tradeoff that adds slowness later can be just as bad.
A project page is opened here and work is ongoing: Hutch Python/Lightpath Device Loading Slowdown Findings/Fixes
L2HE Update
Margaret Ghaly Vincent Esposito
Over the past couple of months, the ECS HE team has been making significant progress on the new controls infrastructure designs. The cost estimates for each hutch has been mostly completed and we are approaching PDR-level readiness in many areas. PDR is now planned for September 2022 (exact date TBD).
The team is working on refining the designs and continues to focus on the PDR, collaborating closely with the mech-E leads and Cosylab.
As a new member of ECS, Mitch Cabral has joined the effort and is working on Jama integration, a collaborative web-based tool for reviewing, approving, and exporting system requirements for release. We have begun capturing L2SI Motion and Vacuum System Functional Requirement Specifications (FRS), and although these requirements are still being reviewed and revised, the hope is to make these documents more accessible for projects to follow, and possibly establish these as standards for our control systems. Transferring to Jama will also allow for agile navigation to find conflicts with upstream or downstream alterations in future project requirements between stakeholders and the team.
We released a major ICD detailing the R2A2 between ECS and other groups in HE. It details many important divisions of work and everyone should at least take a quick look through to better understand what ECS does:
https://slac.sharepoint.com/sites/pub/Publications/LCLSII-HE-1.4-IC-0488.pdf
MEC-U Update
Electrical safety compliance has been a primary focus of recent collaboration between LLNL, LLE and ECS controls teams in MECU. We convened a meeting between the Collective (handle of the partner lab collaboration on controls for MECU) AHJ and LCLS's SO to begin to discuss how the electrical designs of all the partners will be accepted by SLAC ES&H. The discussion was fruitful and identified a number of action items that will ensure MECU's laser systems can be installed without issue.
Thanks to the efforts of the ECS division, the patience of MECU project management, and the collaborative spirit of the other labs in the Collective, we are happy to report that the MECU control system will be developed with a uniform technology stack throughout the experiment, beam delivery, and the LLNL, LLE laser systems. This result is a reflection the ECS team's dedication to their work and their commitment to the support of the MECU project. Writing as PD department head I want to say I am very proud and grateful for the team's candor and stamina in their presentations to the Collective.
Cosylab was introduced to LLNL and the ECS workflow with Cosylab was demonstrated. Thanks to Jing, Maggie and Dan for establishing and running a very productive and exemplary workflow with Cosylab. This also played a large part in reassuring our partners in the Collective of the feasibility of using a common control system stack.
We have been working on the resource plan. The MEC-U resource plan has been integrated with ECS resource allocation planning. A SOW for engineering support for MEC-U control system design has been sent out for review.
Lightpath Campaign
We've been working to rebuild the lightpath application, a tool that aims to give a high-level summary of the beam, where it's pointing, and which devices are blocking. In order to properly represent the facility, significant changes were made both how lightpath organizes devices and how those devices are represented. As of the writing of this newsletter, we have completed the major infrastructural changes to lightpath, implemented a new device interface, and begun to spot check the app's performance for select end stations.
Design details and FAQ's are being gathered at this page, which (like the lightpath app) is a work in progress.
We look forward to the redeployment of this tool with the hope that it will more accurately track beamline state, addressing these kinds of scenarios.
ATEF
atef has seen some improvements since our last update:
- The atef passive check GUI is now easier to use and more feature-complete
- ECS engineers that work in the laser hall have been trialing ATEF.
- They have been providing the development team with helpful and actionable feedback (thanks, Liggett, Andrew and Christina Pino !)
- See below for a few screenshots of their effort, courtesy of Liggett, Andrew
- Tool configurations have been added
- The first tool is "ping" - verifying that a given host is online prior to starting a test
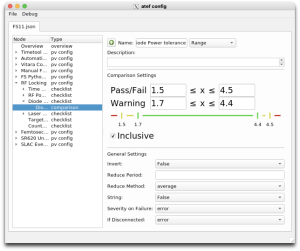
There is also much work left to be done. Next on our list is a final restructuring of the passive check mechanism. The result of this effort, which is now underway, will allow more flexibility for the user to group their checks in intuitive ways. We will also be integrating dynamic values of a variety of sources into the comparison mechanism, meaning that PV to PV comparisons will be a possibility.
EPICS Codeathon
SLAC hosted the May 2022 EPICS Codeathon. There were 3 separate sessions: EPICS core (C/C++), Java tools and extensions, and Python tools and extensions.

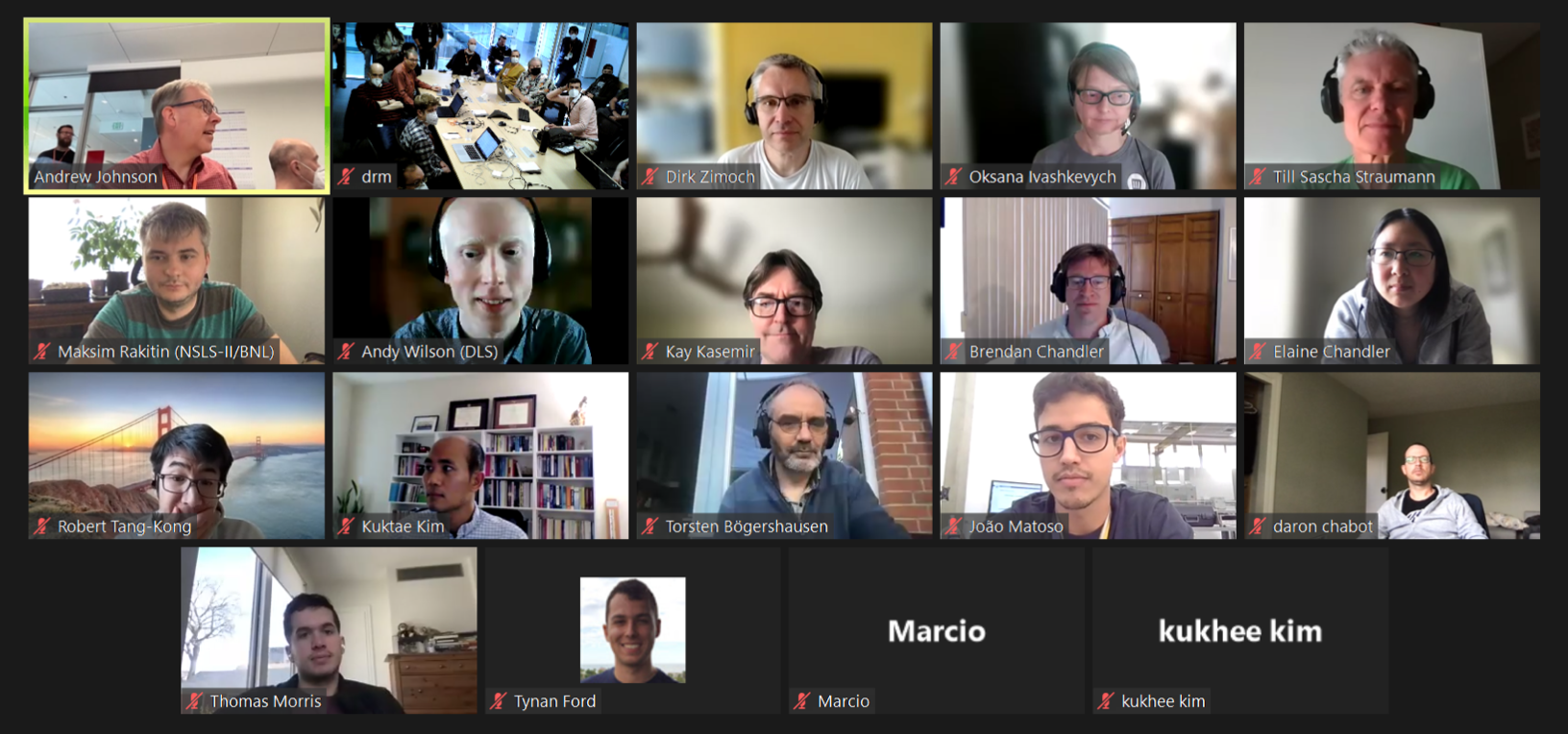
On-site and remote participants for the 2022 EPICS Codeathon (Monday, May 9th 2022)
SLAC saw many on-site participants as well as remote ones from 20 institutions. The following charts break down participant sessions and the number of those remote versus on-site:
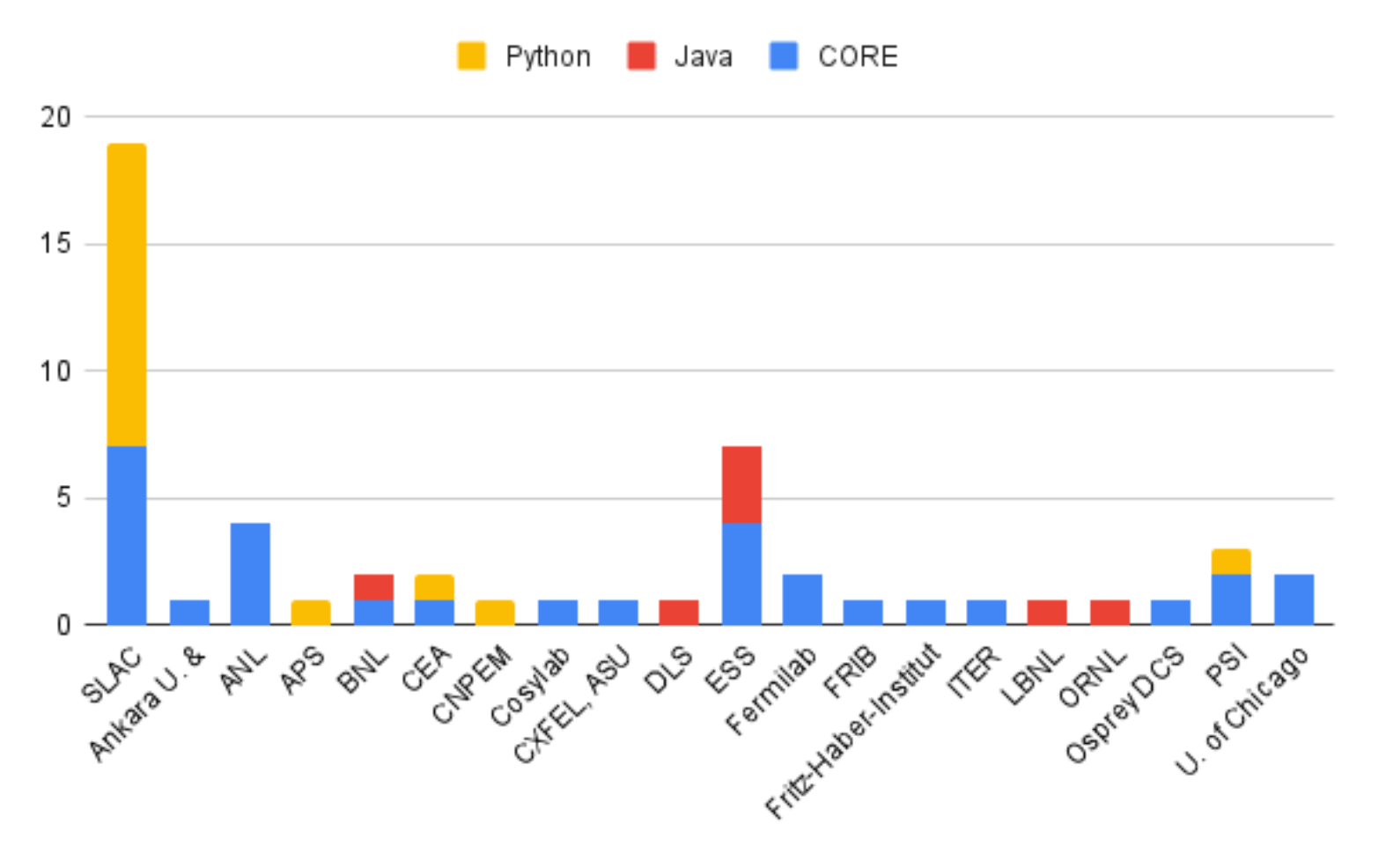
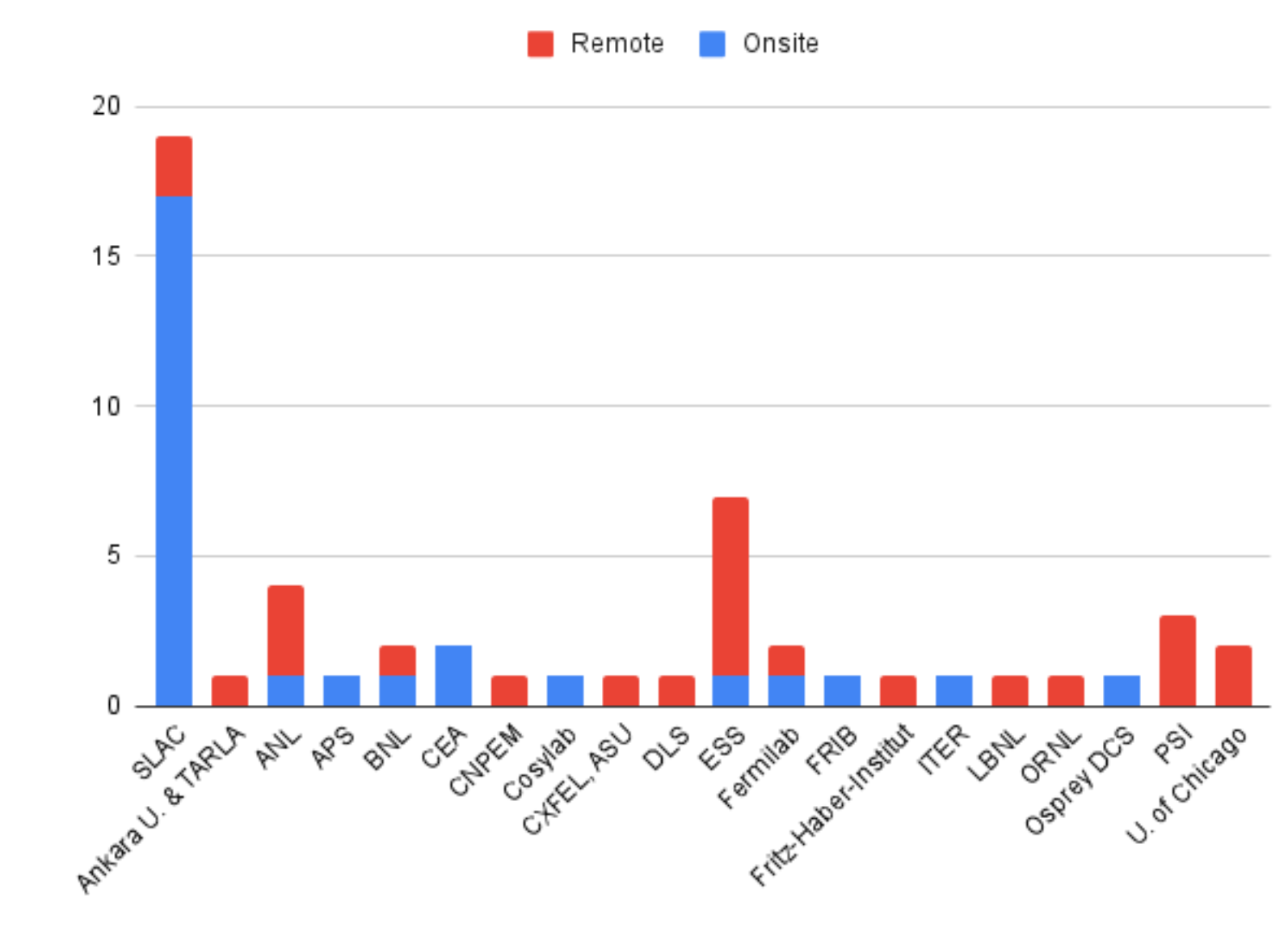
Track | Total | Onsite | Remote |
Core (C/C++) | 30 | 13 | 17 |
Java | 7 | 2 | 5 |
Python | 16 | 13 | 3 |
Totals | 53 | 28 | 25 |
Andrew Johnson hosted the core team, Kunal Shroff hosted the Java team, and ECS controls engineer Ken Lauer hosted the Python session.
The Python session tracked our results on GitHub and ended up fixing and working on an impressive (if I do say so myself) number of things over the course of a few days:
Project | Contributors | Total Issues | Total PRs | Merged/Resolved |
adl2pydm | 1 | 2 | 2 | 1 |
happi | 1 | 4 | 4 | 3 |
ophyd | 4 | 7 | 7 | 6 |
pmps-ui | 1 | 1 | 1 | 1 |
pyca | 1 | 1 | 1 | 1 |
pydm | 9 | 19 | 19 | 14 |
pythonSoftIoc | 1 | 1 | 0 | 0 |
timechart | 3 | 10 | 10 | 10 |
typhos | 1 | 3 | 2 | 3 |
whatrecord | 1 | 1 | 1 | 1 |
Total | 15 | 49 | 47 | 40 |
Special thanks to all of the participants, on-site and remote, for helping bring the community together and fix/enhance so many projects.
For information on the other sessions, please see the attached summary slides:
NALMS
The NewALarMSystem (NALMS) is almost ready for deployment. After the last updates on the system, the testing section is almost ready to start. Thanks to Thorsten, Omar, Jesse, Ken, Michael, and Victor for all the effort.
The GMD and XGMD NALMS will be used for testing purposes. To create a dedicated NALMS for GMD and XGMD, several steps were followed:
- Create a spreadsheet that includes all the PV involved in the GMD and XGMD instruments.
- Discuss with the scientists the best value/boolean thresholds that need to be alarmed
- Give a hierarchy to the selected PVs
- Check the PV's value saved on EPICS and update the values and severity according to the spreadsheet
- Create the XML file that will be the core of the NALMS
The picture shows the first attempt of the Grafana board for NALMS GMD-XGMD.
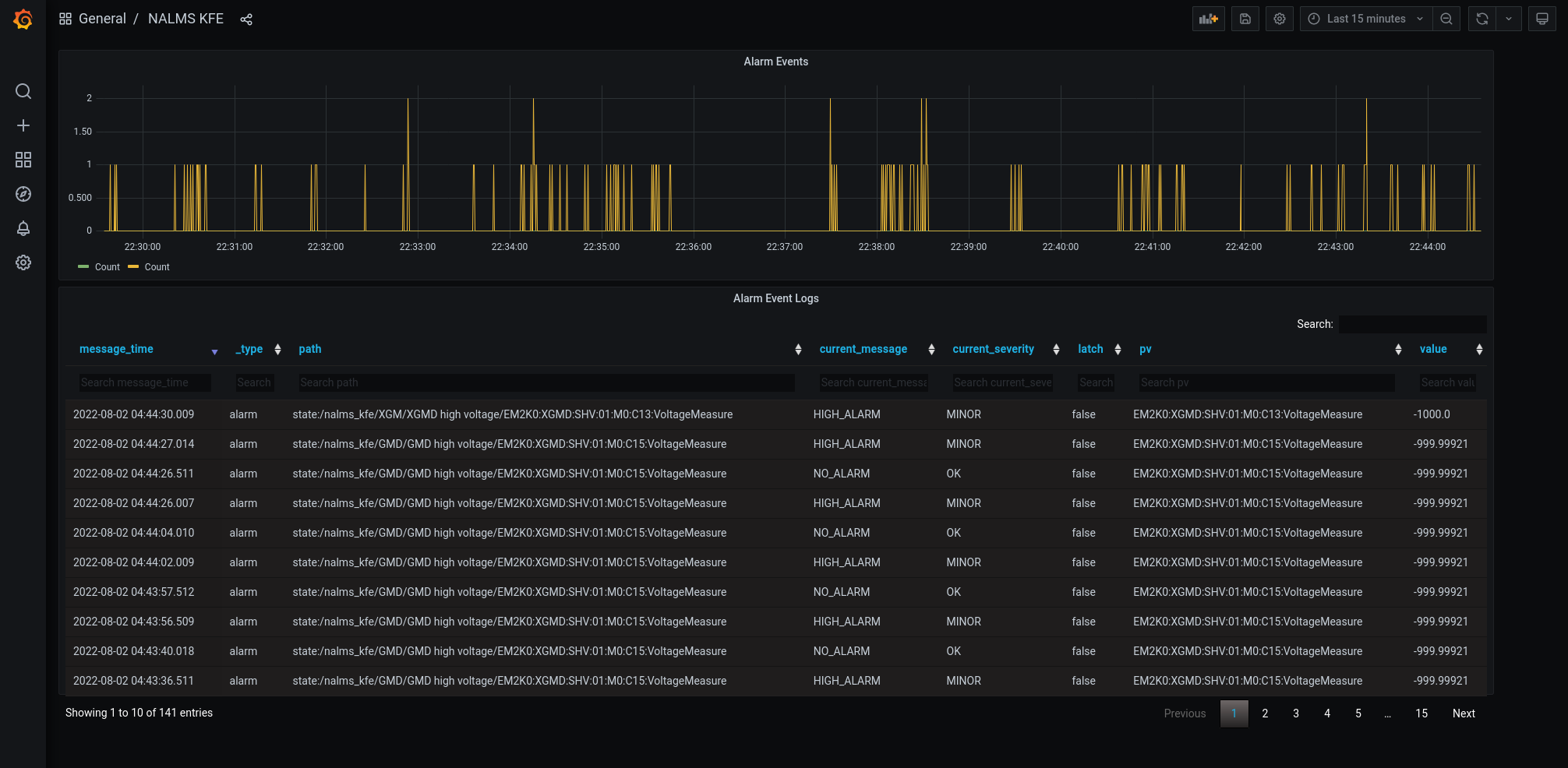
In the future, more PVs will be added to the NALMS. They will be grouped by subsystems (i.g., vacuum, power, common component, etc). For simplicity, to ensure a good understanding and track of possible faults is essential to include in the alarm list only the PVs that are important for the operation purpose. Therefore it is necessary to keep this list as short as possible. Right now, the most critical PVs are being grouped for each subsystem, in the EBD, and in the FEE area, by the DOE summer student Samara Steinfeld. You can follow the upgrade of the NALMS deployment on the NALMS confluence page.
Eventually we hope to summarize our control system status into a navigable alarm tree using NALMS.
TMO
- Granite 3 (all components are checked) is ready to go for DREAM mirror check out experiment(starting from 8/7): IP2(no chamber)-Granite 3 Controls I
Mirror: Waters, Nick Vacuum: Jing Yin Tong Ju Motion: Maarten Thomas-Bosum Zachary L Lentz PMPS: Margaret Ghaly Tong Ju Image: Tong Ju Govednik, Janez
- TMO whole beam line PMPS is completed from the FEE to granite 3 : TMO PMPS System Margaret Ghaly Tong Ju
Scientists will run dream mirror check out experiment and test all PMPS and veto groups at the same time.
DREAM
For the past a couple of months, we have been working on SAT of DREAM components and the integrated DREAM schedule with checkpoints to capture the critical paths.
Vacuum
We recently added several new components to the vacuum systems. For the past month we have been working on the designs of test boxes for these new components. The designs have been tested by an online simulator and will be sent out for team review soon (link). These test boxes will facilitate reconfigurations and new installations by simulating expensive devices with cheap hardware.
IM4K4 Motor Resonance Crashing a Turbo
TMO had a strange problem back in April: whenever they would move IM4K4 in or out, it would vibrate the stand violently to the point that it would cause a nearby turbo pump to crash, which was extremely disruptive to endstation operations.
Stepper motors are known for having some problems with resonance and high vibrations. Typically in industry you would pick servo motors if extremely smooth motion was a requirement. This isn't a requirement here, but "do not shake the stand when moving" is absolutely a reasonable ask.
All of the PPM imager/power meter combination units were tuned based on a single instance before it was installed onto the beamline. As such, the parameters were optimized for a lab bench in the temporary clean room in B750 rather than for the beamline as-installed. With the rush to close out the installation of the L2SI components, it looks like this had never been revisited.
In general, we expect every instance of a motor to have slightly different tuning needs based on the precise specifications by which the assembly was installed. This won't always be worked on to completion because often there won't be any problems, and because the most important specification for the majority of our motors is position accuracy and precision of the end position, along with motion reliability, which is not covered by this vibration case.
It was observed that the PPM units have higher vibrations than one would expect in the FEE, RIX, and TMO, culminating in this turbo pump incident. So, we took some time to do the following for every installed/active PPM:
- Make the position correction loop more gentle. The PLC software that governs the in-transit motion was very aggressively conforming the stepper's movement profile to the "optimal" profile, leading to overcorrection and some slight increase in the vibrations. They were also tuned for an expected runtime velocity of 65 mm/s, when in practice we were running them at 5 mm/s.
- Pick a runtime speed for the PPM that minimized vibrations from resonances. It turns out that all of the PPMs have strong resonances with their stands in the 5 mm/s - 8 mm/s movement speed ranges. This is why most of the PPMs could perform OK if they were slowed down. What isn't obvious if you aren't aware of the resonances is that you can also make the PPM perform better by speeding it up. Most of the PPMs had a "best-case" (minimum vibration) speed at around 12 mm/s, though some performed best as high as 15 mm/s or as low as 11 mm/s.
After these adjustments, the PPMs are silky smooth, quiet, and reach their destinations reasonably quickly.
Supported Device List Amendment Process
ECS added a set of steps to our SDL curation page to give insight into how we would like other teams to work with us to add a new device to the list. We also plan to write up a process for how we'll go about changing an existing device's status. Please take a look at this process to learn about how you can get a device added to the list, and let us know what you think!
ECS Supported Devices Curation
ECS+ME SME Teams
ECS and ME are working on arranging subject matter expertise teams to collaborate on system architectures and curation of the supported device lists. They will also work on engineering design templates, eg. how to specify and select mechatronic actuators, or arrange a vacuum system to use already existing and tested interlock logic.
Validated Configuration Database
LCLS has never had a single-source-of-truth for beamline configuration (the arrangement and state of components in the beamline). This has led more than one incident where either equipment was added to the beamline without notification or proper planning leading to last minute mitigation. Projects also suffer as an updated as-built of the beamline configuration is mythical. In some cases the beamline GUI is the best and only as-built reference.
ECS and ME (you could call us together, LCLS engineering), have been collaborating since early 2022 to develop requirements for a database system to address this issue. We considered a number of options, including using an existing system from the AD. Our requirements aim for a highly collaborative platform, with an excellent API, and ease of use as the key to ensuring an accurate as-built record. Essential information to be tracked by this database includes x, y, z, functional component name, and status (planned, installed, commissioned, etc.), with the ability to add fields as desired. We plan to link other modules such as Happi, and the Asset database to this configuration database to keep everything in sync. Development started in June and is proceeding. Learn more here. We're anticipating initial deployment at the end of August.
MEC SPL Upgrade
The MEC Short Pulse Laser new platform work in the target chamber, which included significant changes to hutch radiation monitoring and shielding, is a PEMP goal for SLAC. This was successfully demonstrated with the in-house experiment X455 [Lee: Commissioning of compact HAPG spectrometer with higher X-ray photon energy from 8 keV to 24 keV] and will be used for the upcoming X523 [Khaghani: Commissioning of a standard beam-delivery platform for high-intensity laser experiments at MEC].
In conjunction with the SPL work MEC is also commissioning two new spectrometers – XRTS and XTCS [X-ray Transmission Crystal Spectrometer]. The Cu K-alpha and K-beta lines are clearly visible in this image from the XTCS on-board camera taken on 6 August 2022.
Vera C. Rubin Observatory Presentation by Peregrine McGehee
Peregrine presented a short introduction to the Vera C. Rubin Observatory at a recent MEC SRD team meeting: PDF of slide deck is attached.
Hello! Goodbye...
| Antonio Gilardi has joined the ECS Delivery group as the new MFX and UED Point of Contact. |
 | Mitchell Cabral has joined the ECS Platforms Development team as a Control System Integrator, whose focus is supporting developing projects (L2HE and MEC-U primarily). Mitchell is a recent mechatronics engineering graduate from CSU Chico and alumni of the CSUC Engineering Capstone program. His project, sponsored by SLAC for the past year, was to develop a prototype computer vision system robot for Dr. Diling Zhu in XPP. Some of his hobbies/interest include cooking, the Sacramento Kings, volleyball, rock climbing, (hiking to/swimming in) large bodies of water (with a nice beverage). |
| Divya Thanasekaran has joined the ECS Delivery group as a Staff Software Engineer and the new CXI Controls and Data Point of Contact. Divya has a masters in Computer Engineering from New York University and prior to joining SLAC she was the Lead Device Control Software Engineer for Primary Mirror Control System of the Giant Magellan Telescope. In her term there, she was involved in subsystem specific resource priorities and scheduling. She carried the software from design inception, through design reviews, testing and test readiness reviews as well as initial successful system test campaigns. Her background is in Embedded Systems, C/C++, Control Software using EtherCAT. She loves to hike, run and is currently learning how to play tennis. |
| Christian Tsoi-A-Sue has joined the ECS Delivery group as a Staff Engineer 1 and his current focus is providing support for CXI as the SEA. He studied robotics engineering and electrical engineering at UC Santa Cruz and graduated in 2019. His areas of interest are embedded systems/microcontrollers, C and Python. In his free time he enjoys playing pickleball, watching movies and playing Pokemon Go with friends. |
| Josue Zamudio Estrada is a new intern on the LCLS Exp. Control Systems Delivery Team. He studied Computer Engineering and recently graduated from UC Santa Cruz. On his free time he likes to skate board, fish, and spending time with friends. |
| Lana Jansen-Whealey has joined the is a new intern on the LCLS Exp. Control Systems Delivery Team and is excited to continue learning about hutch instrumentation and software interfacing. She recently graduated from Cal Poly, San Luis Obispo with a physics degree and has been working at SLAC since July 12. She prefers to spend her free time visiting national parks, hiking, doing ballet, cooking, and making new friends! |





We said goodbye and farewell to Maarten in July. He will be missed. You can see his Kudoboard here.
Github
It should be noted a huge quantity of our work is done on Github.com, all development is tracked there. Jira issues capture a significant body of work as well, but at least as much work is also captured in the closure of Github tickets (issues) associated with our various codebases. Unlike Jira, getting a consolidated metric of work done in a past period is not possible without a paid subscription to Github. Roughly speaking over 80 projects were touched since April 8th, with multiple changes of various sizes.
Jira
If you can't see these Jira plugins, please log into Jira/ Confluence. If you can't log into Jira, send mail to apps-admin@slac.stanford.edu and ask to be added to Jira.
Getting issues...
Introduction
This edition is extra special as we have for the first time a section for LCLS IT recording some of the improvements and maintenance activities of Omar's team!
Safety Stand-down and EEIP
The newsletter is being released approximately 1 week later than we originally planned due to the SLAC-wide safety stand-down on Wednesday 5/4. While the circumstances prompting the stand-down are not good, the outcome of the activity was positive.
ECS took time to refamiliarize ourselves with the WPC and electrical safety aspects of our work. We also spent some time collecting data from the division on (over)work, including consecutive hours, and days worked, as well as peak number of assignments in an effort to better understand the issues Mike Dunne mentioned in his all-hands.
ECS would like to take a moment to emphasize the importance of EEIP at LCLS and SLAC in general and remind everyone reading this newsletter to look into what EEIP is, and how to make sure your equipment is compliant. You can learn more about EEIP here: https://slacspace.slac.stanford.edu/sites/pcd2/eeip/default.aspx
ES&H Ch8 (Electrical Safety) is everyone's responsibility.
LCLS-II-HE update
The ECS team continues making progress, advancing instruments’ designs, and ramping up efforts with greater engagement from instrument’s leads. The goal for the remainder of FY22 will be to refresh the overall cost estimate as recommended by the committee, while at the same time remaining committed to advancing the design maturity of all Experiment control systems to Preliminary Design Review (PDR) (60%) level. The PDR for controls is slated for August of 2022.
Roles and Team Fully Released
All major roles in LCLS-II HE Experiment Controls have been assigned to ECS team members. Check out the list below to determine who you can talk to in the ECS team for help with HE. If you have any questions please contact Margaret Ghaly
L2HE Project Roles and assignment table can be found here. (This will be the updated list at any time.)
MEC-U update
Rack allocations
We spent some time doing rough estimates of rackspace for MECU, here are some of the figures we developed for your consideration. These don't include the other partner labs in the count, their estimates are elsewhere. Other systems outside of this count include Safety (PPS/BCS/HPS/LSS), Timing and IT infrastructure.
| Full depth racks (42U) | Shallow racks (42RU, for small depth devices) | |
| Laser BTS controls | 4 | 2 |
| Xray BTS | 3 | 3 |
| TCX | 6 | 3 |
| TCO | 4 | 2 |
| Total | 17 | 10 |
Other controls requirements
More controls requirements were developed in March and April. These requirements were specifically focused on EPICS network size, DAQ bandwidth, EPICS archiver size and reliability, as well as the logging systems. High-level requirements are being developed as ConOps are updated/ generated. If there is any particularly important requirement of the control system, or high-level functionality please let Alex Wallace or Jing Yin know.
LLE+LLNL Onsite Visit
The Rochester and Livermore team came to SLAC on March 22nd and 23rd to learn more about MEC operations and collaborate in person on the project. This was the first time all three partner labs met in person to work on MEC-U. The controls breakout session reviewed the operations and the high-level supervisory control software of the Omega laser facility. We also learned more details about the mechatronics, industrial and timing system controls of the LLE system.
Hutch Python Update
Hutch python's conda environment was updated to pcds-5.3.1 near the start of April.
You can read the full release notes here: PCDS Conda Release Notes: pcds-5.3.1
Robert S. Tang-Kong Zachary L Lentz
New Dual-Acting Valve Widget
Dual acting valves are now integrated into pcdswidgets with a nice looking icon to represent the functionality of the valve.
Extensive documentation on the process of making a new pcdswidget was provided as well as scripts for testing widgets in development.
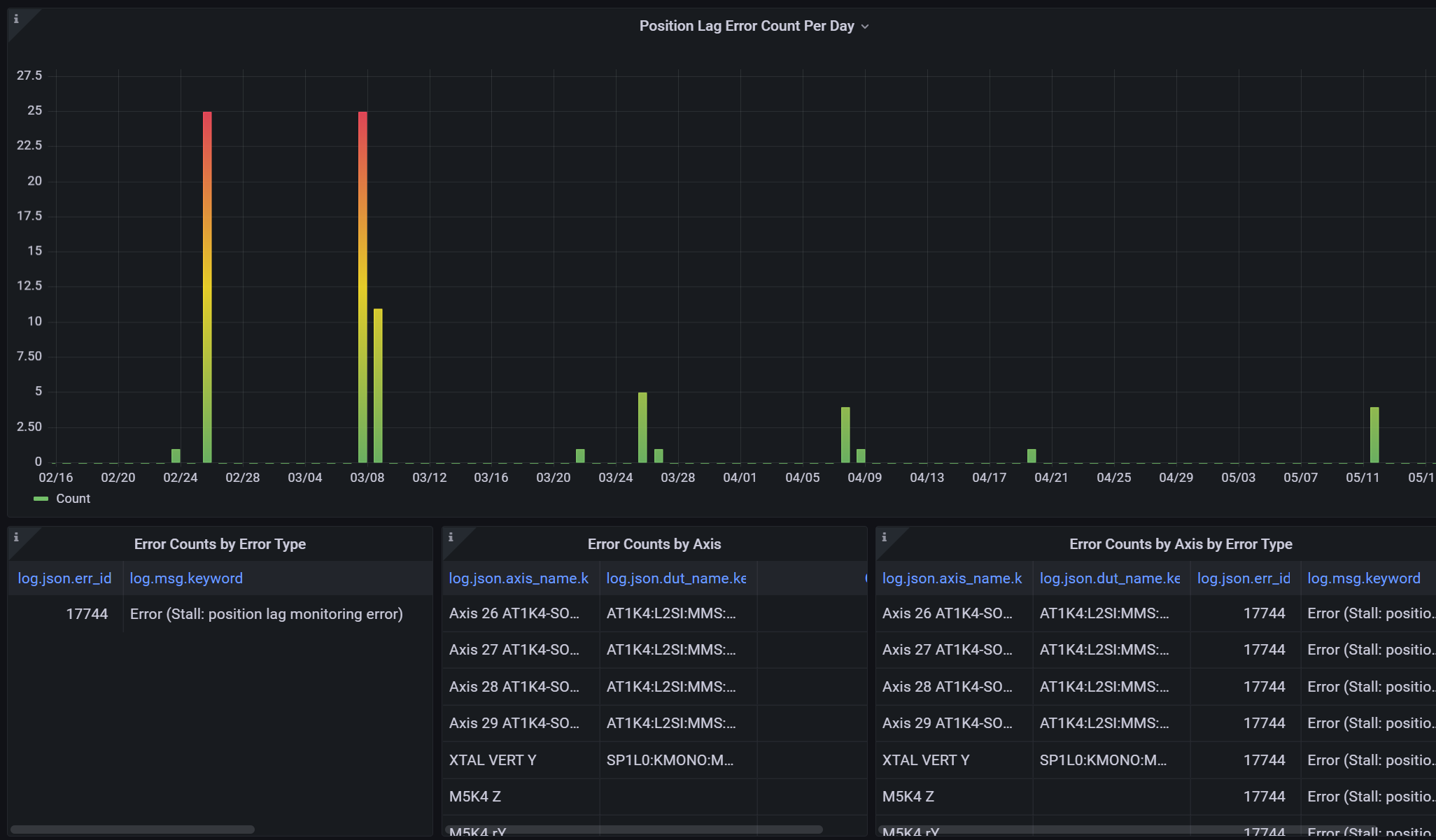
Issues with mechatronics in production
A streak of issues with motor driven actuators in March and April ate a significant amount of beamtime. Many of these issues could be classified as stalls (spurious and real), where a motor is commanded to move and its actuator readback indicates no movement has occurred within some time. Stalls can occur for a variety of reasons, real physical obstruction, or improperly set motor or protection parameters.
In an effort to track and reduce such issues (and motion system issues in general) we built a new Grafana dashboard using data from our logging system (L2SI systems) to organize and track all of these motion system issues in one place. The dashboard can filter between different kinds of motor issues, and specific devices as well as give us a clear view of the most problematic parts our system.
We also met with our Mechanical Engineering counterparts and began a long-term collaboration on motion systems in general together. We plan to use this collaboration to create better design recipes for LCLS mechatronics, and study and correct pervasive issues in deployed systems. We will supply updates from this work as it develops.
If you have any questions about this section please contact:
Lightpath Campaign
Lightpath is a tool that aims to show users and scientists which components are blocking the beam path, greatly expediting troubleshooting and recovery of operation.
Unfortunately the tool has been plagued with bugs and efficiency issues for quite some time. We are planning a substantial rework of the tool, with the goal of making the tool available and useful for all hutches.
A JIRA Epic has been created to gather existing lightpath issues/bug reports. If you have ideas for features or bugs to report, feel free to add an issue to the epic. We will be basing the re-design on requested features, so submitting an issue now is the best way to see those issues solved. We will continue to reach out for input throughout development, so be ready to hear from us!
New ECS PD Campaign: Code Review
ECS currently has nearly all of our hutch-python and related Python source code in the pcdshub organization on GitHub.
We utilize a standardized workflow that improves understanding among our team, provides automated quality and style fixes, and in the end results in a higher quality set of code.
We want to apply the same standards we have for Python development to all PLC, EPICS module and EPICS IOC development.
This will be an ongoing effort over the course of months.
See more details on the initiative page here - ECS GitHub and Code Review Campaign - feedback is welcome.
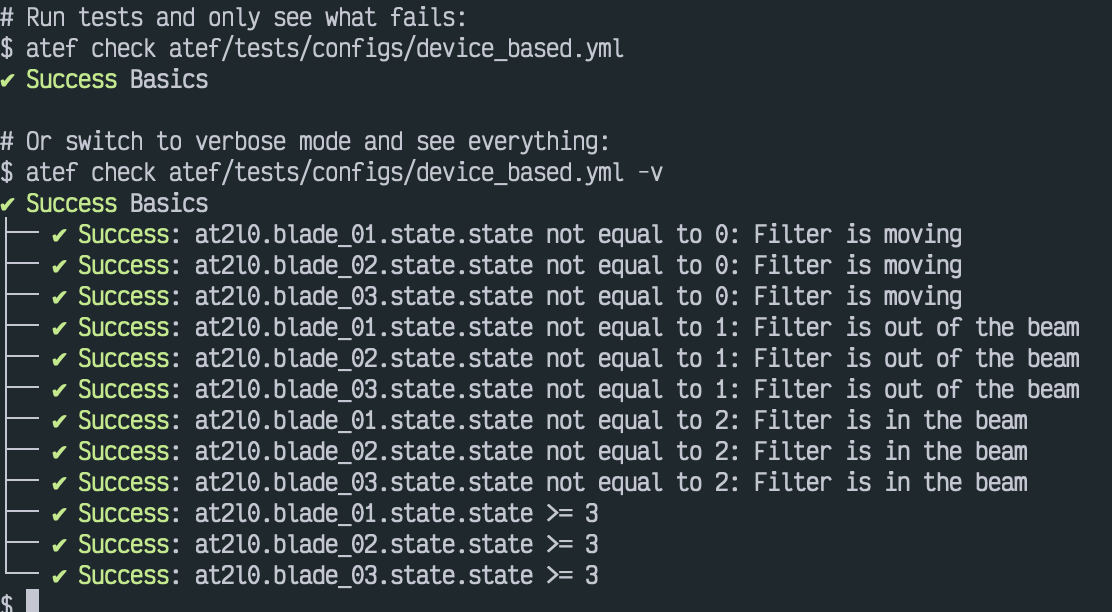
ATEF Status Update
We are continuing our ATEF development effort, targeting passive testing of control system devices. The "passive" portion of this means that it will be fully-automated and non-intrusive (that is, it will not move your motors or otherwise execute a caput).
We are making progress on the user-facing components of atef for passive checks. This includes a work-in-progress set of GUI elements, allowing for a more straightforward specification of a passive checkout configuration, with a happi device search tool and ophyd device inspector. A preliminary command-line based passive check running tool has also been developed.

Future development will include: active tests (guided, with humans in the loop) including integration with bluesky, a synoptic for viewing the atef-reported status of all devices, integration with Grafana, views of devices in typhos/hutch-python at a given time in the past, and many other things.
shared-dotfiles
What are dotfiles?
- Dotfiles are configuration files that sit in your home directory, like
.bashrc. - Dotfiles set per-user configuration settings for different applications, like the text editor vim or your shell.
- If you have a unix account, you likely have dotfiles in your home directory on pslogin, whether you have customized them or not.
In a survey of users' configurations, we found that many were similar, likely copied and tweaked from one user's home directory to another when they joined ECS.
In some strange form of the telephone game, a bit of meaning was lost between each successive copy, with configuration lines remaining with not a clue as to why they were there.
To make things better we created a shared repository as good starting point for new engineers, or existing ones that want to improve (or just better understand) their settings.
Almost every line contains an explanation as to why it is there, with some offering suggestions as to how to adjust it to your preference.
Here is a link to that repository:
→ https://github.com/pcdshub/shared-dotfiles
It includes a variety of suggested configuration files for various basic tools like ssh, bash, vim, and so on that ECS staff and others who use the same computing infrastructure may find useful.
It also explains a bit about what scripts are available and how to better navigate your environment in its documentation.
If you have ever felt like your command line interface was missing commands, or you wish it had more colors to help with readability, or you just want to make sure you're not missing out on some nice features, check out the repo.
Vacuum System
Added a new supported gauge! Instrument hot cathode gauge IGM401 will be used in TMO. Please check here.
We also gave a seminar on the LCLS II vacuum control system. If you missed the seminar, you can find the slides and meeting video here .
QRIX Controls

The Spectrometer Arm has been installed and checked out. The spectrometer arm has a total of 27 axes installed with coupled and coordinated motion with strict EPS requirements. The acceptance test went very well with Toyama and even were complete ahead of schedule.
The QRIX vacuum PLC code has been merged with that of the spectrometer arm. The vacuum controls integration is complete for all the installed devices.
TXI
Cables were successfully pulled in the FEE for patch panels for both K and L lines.
TMO
First deployment of VAT590 variable valve in LAMP. Jing Yin Govednik, Janez Maarten Thomas-Bosum
This was used with the Magnetic Bottle (MBES) iteration of the LAMP endstation.
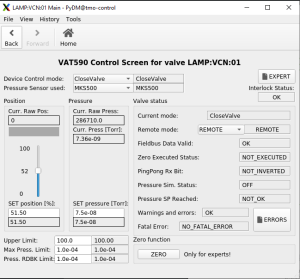
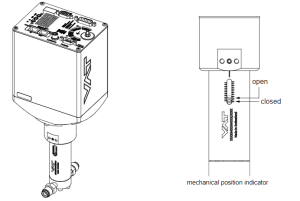
TMO requested this very-low flowrate leak valve for experiment gas delivery and vacuum level control in the IP1 chamber.
The valve plate acts as a throttling element and varies the conductance of the valve opening.
Actuation is performed with a stepper motor and controller. The stepper motor/controller version ensures accurate pressure control due to exact gate positioning. The onboard controller and built-in PID loop were integrated into the control network of the LAMP vacuum PLC and IOC, and a custom PyDM GUI was developed as a user interface for this device.
In the future, this device will be integrated into the vacuum control systems of other endstations in TMO. Furthermore, work will be done to allow users to set and tune the PID loop parameters themselves, which are currently locked into the lower level CoE settings. This is because the control loop needs to be adjusted for chambers of different volume, gas flow rate etc.
Documentation page: LAMP MBES Variable Leak Valve Commissioning 3/22
Radiation Monitoring in the FEE
We installed a live radiation measurement system in the FEE! We have been busy integrating this equipment for the past several months.
From four different locations we gained 2 sensor readouts each. Here we see Hard Xray beam energy mapped against dose rates.
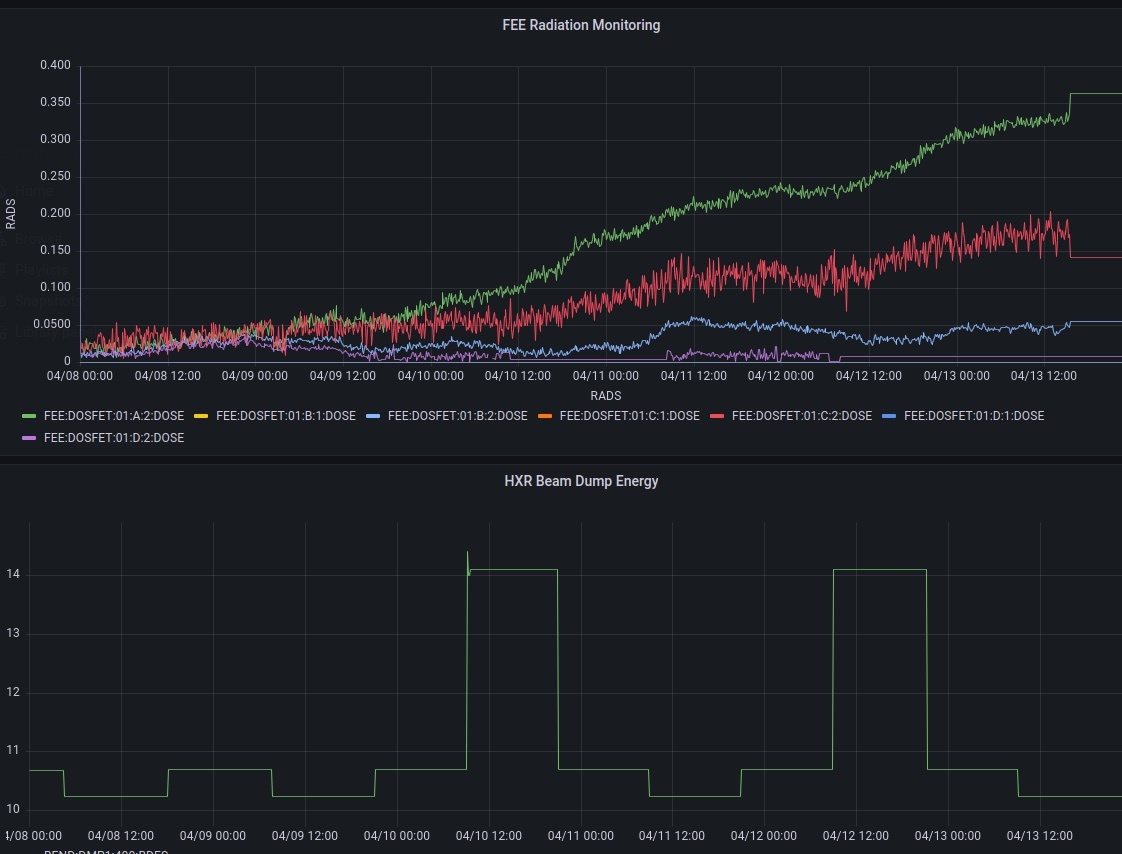
A shift was made to bring the rest of the sensors online. Looking forward to collecting more data this month!
The plan is to collect data on radiation in the FEE and EBD to prepare a baseline for comparison with SC beam when it arrives. Ultimately we want to be able to discern between device failure due to normal use and radiation damage.
X-ray Optics Controls Updates
MR1L3, MR2L3, and MR1L4 XRT HOMS Mirrors
- Temperature sensors added to XRT HOMS Temperature
- State Control fully implemented! We can now reach mirror coating positions and move the mirrors in and out of the beam with one click!
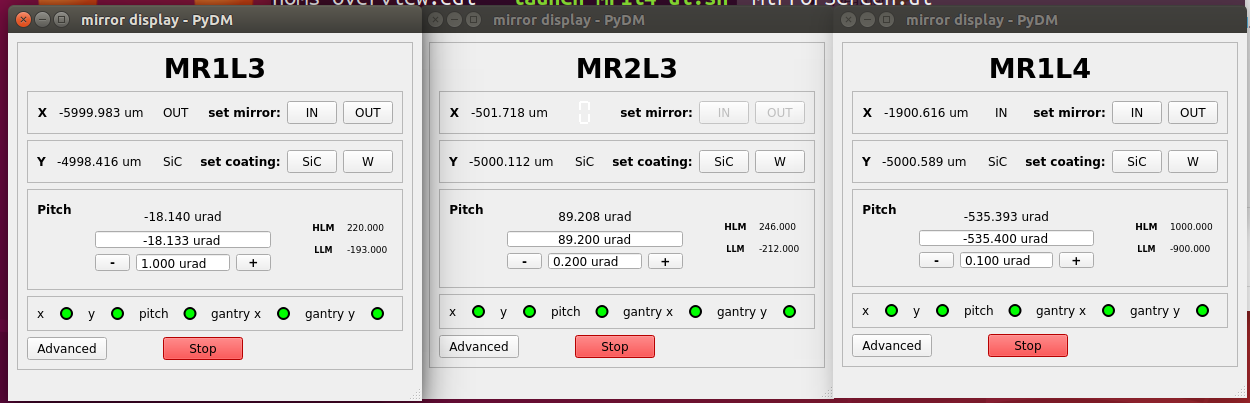
MR1K4 FEE TMO Mirror
- Newly upgraded with coating state control.
- PMPS states implemented.
MR3K4, MR4K3, MR2L1, and MR3L1 TXI Mirror
- Site Acceptance complete: TXI SAT
MR4K4, MR5K4 TMO DREAM Mirror
- Granite installed/Mirror moved into the hutch.
- Controls fully checked out: DREAM Install
- Coming: Internal RTD, Pressure, and Flow Sensors.
MR2K4, MR3K4 TMO LAMP Mirror
- Look for some higher performance in the axis control
- Control loops changed and deadbands tightened
Experiment State Tracker and Eloggrubber
Based on popular demand, the Experiment State Tracker has been integrated with the eloggrubber and the possible state list has been extended (with much more detail for 'instrument down' in particular.)
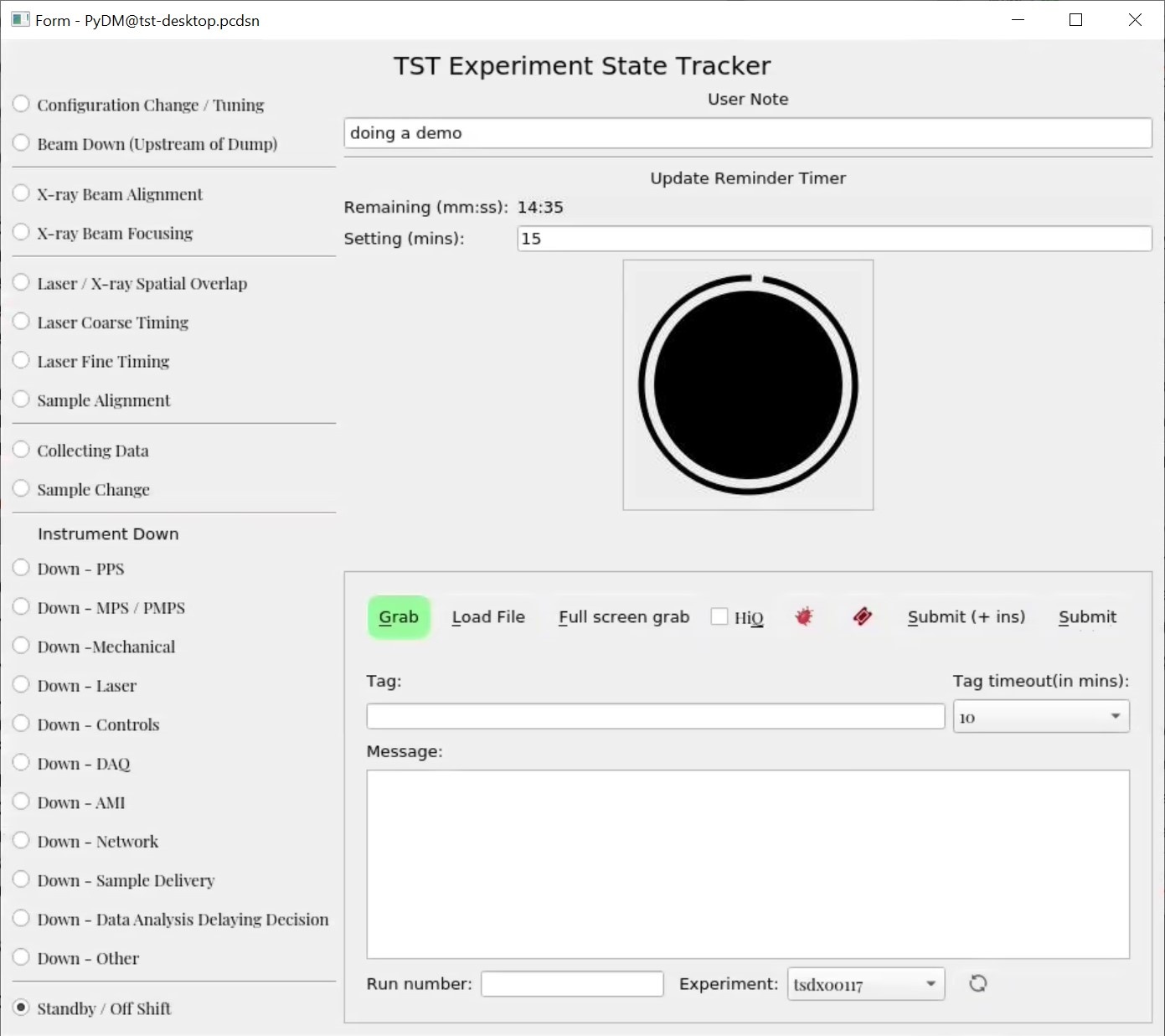
The eloggrubbers JIRA implementation has changed to allow automatic assignment to the instruments as well as posting of the attachments Murali Shankar
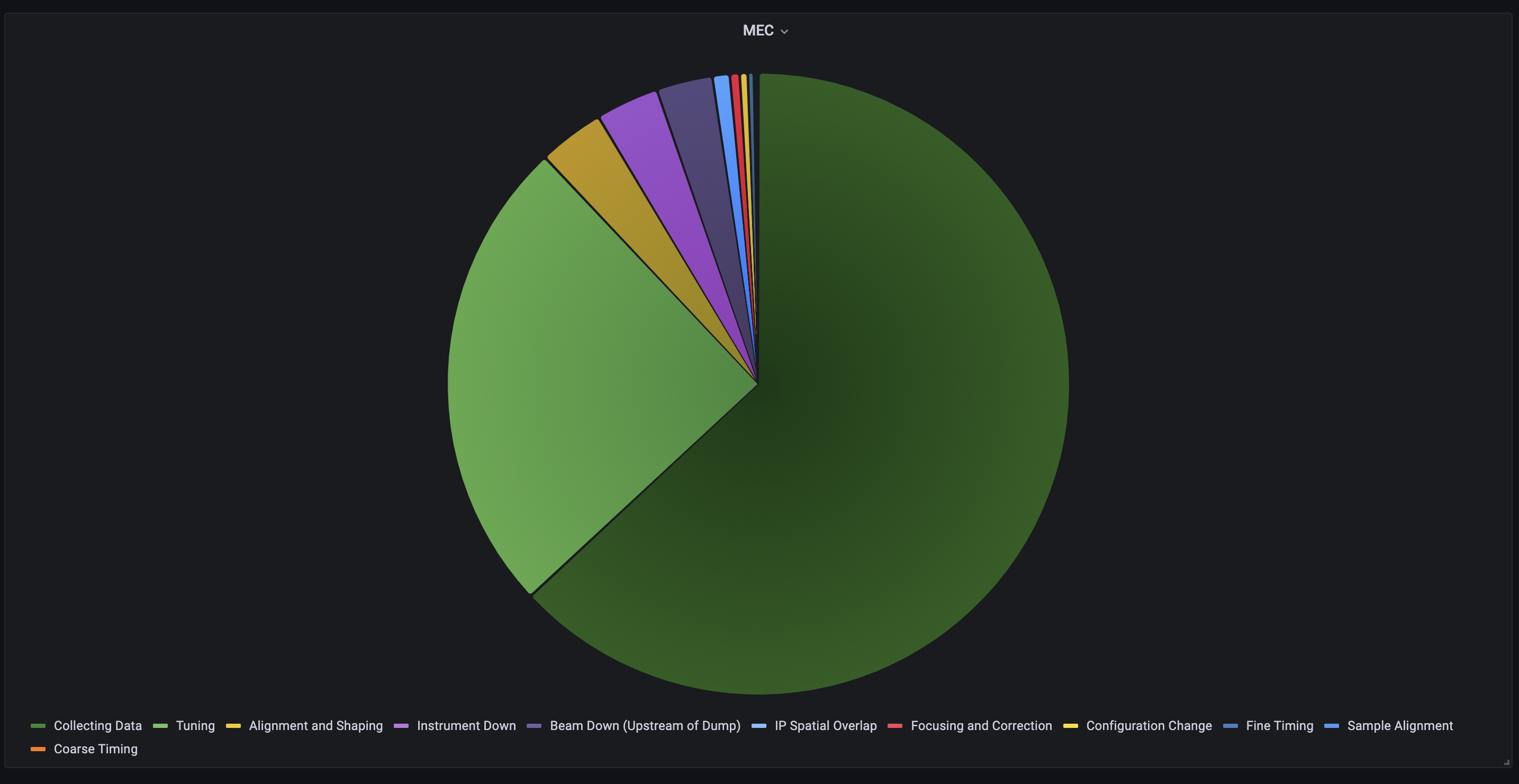
Grafana has also been extended to allow the creation of piechart data from the archived Experiment State Tracker output.
Jungfrau [0.5/1]M IOC
The smaller jungfrau detectors which use a Rohde-Schwartz power supply now have an IOC (ioc/common/roving_jf) to make the process of turning them on/off consistent with the various epix-detectors. This IOC will trip the detector should a problem with the chiller flow or power supply is detected.
Jungfrau4M Tripper
Thanks in large part to Daniel Scott Damiani, a tripper has been created for the Jungfrau 4M detector in CXI. This is similar to the CSPAD tripper and will help to protect the detector from intense X-ray by blocking the beam when too many hot pixels are detected. The tripper runs through a combination of an IOC and AMI plugin. The IOC host PVs that for input and output to the tripper and closes the shutter when necessary. The window below can be easily seen on the CXI Home Screen, and can be used to adjust the threshold or clear a trip. From now on, the tripper should always be enabled to prevent burning out any more pixels.
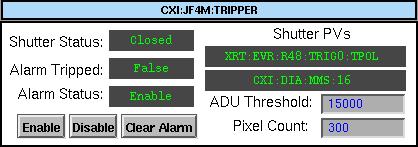
The "ADU Threshold" is the number of ADU below the saturation in low gain allowed before a pixel is considered too high. The "Pixel Count" is the number of high pixels allowed before tripping the beam. Please do not adjust these values without discussing with Mengning Liang or Tyler NT Pennebaker beforehand.
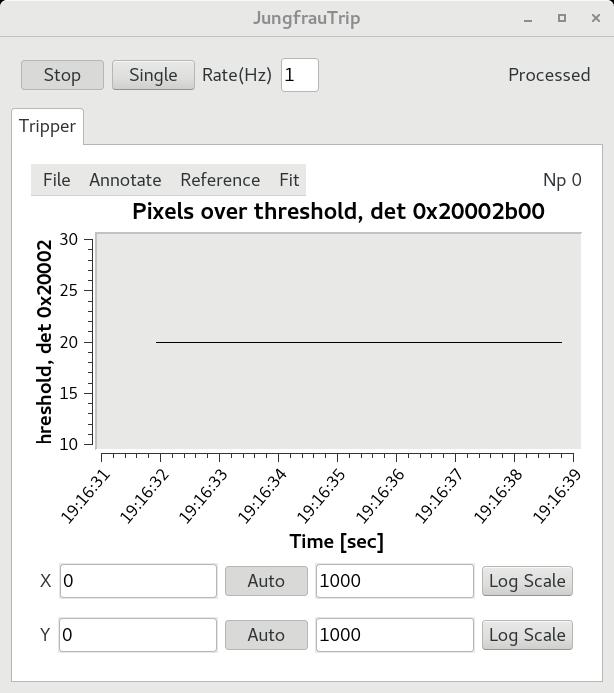
As another form of feedback, the AMI plugin adds an option in the AMI window called "JungfrauTrip" that allows the user to watch the number of pixels above the threshold over time. Below, we can see a constant 20 pixels above the threshold, using the current settings without beam, due to the misbehaving already-burnt pixels. If you have any questions about the tripper, please feel free to reach out to me!
CSU Chico Engineering Capstone Collaboration
This year is a prototype system for determining interaction point component alignment using machine vision sponsored by Diling Zhu. The CSU Chico Engineering Capstone Collaboration project team visited XPP in early March to do some final fit measurements around the interaction point for installation of their project later this year.
The team won Best Project this year at the CSUC design expo (May 13th), competing with ~20 other project teams from the program. The team will also present their project this summer in Dallas TX at a national competition for engineering capstone projects.
L-R Anthony Aliotti Mitchell Cabral Clarice Rucklos Jasmine Nguyen |
The team in front of their winning project and display showing off the robot, their SLAC affiliate badges, and the numerous iterations on the 3D printed camera mount. |
The team hosted a local Girl Scout group and used the collaboration project to demo robotics. |



For the past five years LCLS departments (SED and ME) have sponsored projects with the Mechanical/Mechatronic Engineering departments of CSU Chico for their engineering degree capstone. Each year the collaboration project offers a chance for LCLS to develop prototype concepts, or even to offload a manageable portion of work to a team of 4-5 students and a faculty advisor (for a nominal fee + M&S). These projects offer us a chance to discover talented candidates and provide the students with an incredible experience doing a project at a national lab. If you have an idea for a project, please contact Alex Wallace for details (or if you want help setting up a collaboration with your school). On a final note, this year we are excited to announce that we hired a student from this year's team, Mitchell Cabral. He will join ECS as a control system integrator in June.
HXR Single Shot Spectrometer Updates
Restoration and recommissioning of the HXR spectrometer mechatronics has been completed. The spectrometer has already been utilized in experiments including some in MFX. Below are some images taken from the Orca camera. Some minor updates to the gui have been made including power cycle control as well as quick access to the webcam used for remotely viewing how the spectrometer is behaving.
Full design and motion system details can be found here
Hutch Rack Cleanup Efforts
Progress in hutch cleanup has began with network switch rack organization in both XCS and XPP, below are before and after images taken from each:
XCS:
| Before | After |
|---|---|
|
|




XPP:
| Before | After |
|---|---|
|
|


IT Updates
Spencer, Aalayah I Omar Quijano Otero, Julieth
Network Reorganization
Over the past few months, the CDS-IT (hereafter IT) team has worked to upgrade and simplify the network set up across the NEH and FEH Hutches, XRT, and FEE. Currently, CXI is the only Hutch remaining to undergo the new network restructuring.
The purpose is to provide 100GbE stacking and/or uplinks for maximum reliability and multigigabit access. The first 24x (1 - 24) ports provide 1000 Mbps connection and the next 24x (25 - 48) ports provide 10,000 Mbps connectivity. All ports provide POE+/802.3bt (90W per port) with up to 1500W power budget with 2 power supplies.

Ruckus ICX 7850-48ZP
WEKA Home/FFB Cluster Upgrade
LCLS has 2 WEKA storage clusters: i) provides the home directories and software for all users and staff, and ii) the FFB for the user's experiments. There was a bug with the previous release of WEKA affecting quota. The latest version was installed to fix the quota bug and improve performance. The team is still working with the WEKA team to deliver a feature for users to check their current quota usage.
DSS and MON Nodes
There have been many incidents where the DSS and MON nodes fell into disrepair during an experiment and communication about their state as well as a checklist for the required setup was missing. To provide transparency across the multiple teams, the IT team has created a confluence page that explains the validation methodology and provides a log of the current functional DSS and MON servers. This will prevent the teams from guessing which nodes are available and allow the IT team to fix those that are not available. Coming soon, the IT team will deploy a new image with monitoring that will provide alerts so that actions can be taken in a timely manner.
SRCF Datamover Bandwidth Upgrade
There has been a request by the Data Management team to provide more bandwidth to the SRCF datamovers to keep up with the current data rates. A 2 x 10Gb bond was created to support a bandwidth of 20Gbps. There are 5 servers used by the Data Management team as SRCF datamovers to support the various experiments.
Workstations and Servers Matrix
To organize, clean, and validate the current host database, the IT team decided to check each Hutch for the currently existing online and offline devices. After inspecting in detail the host database, information was gathered with the objective of removing the devices that were no longer required. This process involved the participation of the POCs, SEAs, instrument leads, and the IT team to ensure that the information was coherent. Currently, the team is still working with the various staff to finalize this extensive activity.
Remote Operations Hardware Maintenance Schedule

Although LCLS has devices for making remote operations more efficient, each hutch counts with a Realwear HMT-1 headset and the Double3 robot. The Realwear HMT-1 headset can be used for an interactive hands-free video conferencing call (expert troubleshooting) and documenting by taking pictures/recording of such call. The Double3 is a telepresence robot with video conferencing and remote driving capabilities. There has been a lack of support for these devices, so the IT team is working on providing a weekly and monthly maintenance guide. In addition, each device will be transferred to its respective custodian, and training will be provided to more IT members so that they can provide assistance to the various staff personnel. A weekly status report will be logged for the continued maintenance and support of these devices: ROH Maintenance Logs.
Integrate UED to LCLS Standards
There is an effort in progress to support UED's revamp to the LCLS standard. Now, UED has a main system named ued-daq with multiple screens, which support both the LCLS and ASTA controls. The idea is to integrate the Accelerator Network into the LCLS managed devices to provide the current LCLS IOCs and DAQ systems with the capability of accessing the Accelerator PVs. This step will provide two key functions: i) removal of the UED local gateway and leverage the LCLS gateways, and ii) allow UED to slowly transition their control system to the LCLS environment.
New Ciara Purchase
A new purchase for workstations and 1U AMD Rome servers has been made. There will be an additional 10 control room workstations and 65 servers. The servers will be deployed across LCLS for new DAQ and Control Systems, or to replace faulty ones. The workstations will be deployed across the different control rooms and hutches.
Pit Cleanup
Over the past few weeks, members of TID have been supporting the Pit Cleanup effort. Old infrastructure and non-working devices have been set aside to be sent to salvage. At this time, the team is trying to coordinate a time with the RPFO office to do the radiological survey for all unwanted hardware. Once the survey has been completed with the appropriate paperwork, TID staff will move the hardware to salvage.
Upcoming IT Tasks
The following are short-term tasks the IT team is working to deliver:
- CXI network upgrade.
- Switch tool for user management.
- Diskless server upgrade to provide resilience.
- Diskless monitoring to make sure all DSS and MON nodes are operational
- Extra 20 batch nodes for the FEH queue.
- Finalize the ioc-xrt-rec07 image to validate 10G network.
- Finalize and validate GNOME key binding shortcuts process.
- Deploy NoMachine extended capabilities to support remote operations.
Jira
Jira showed an interesting trend in the past two months.
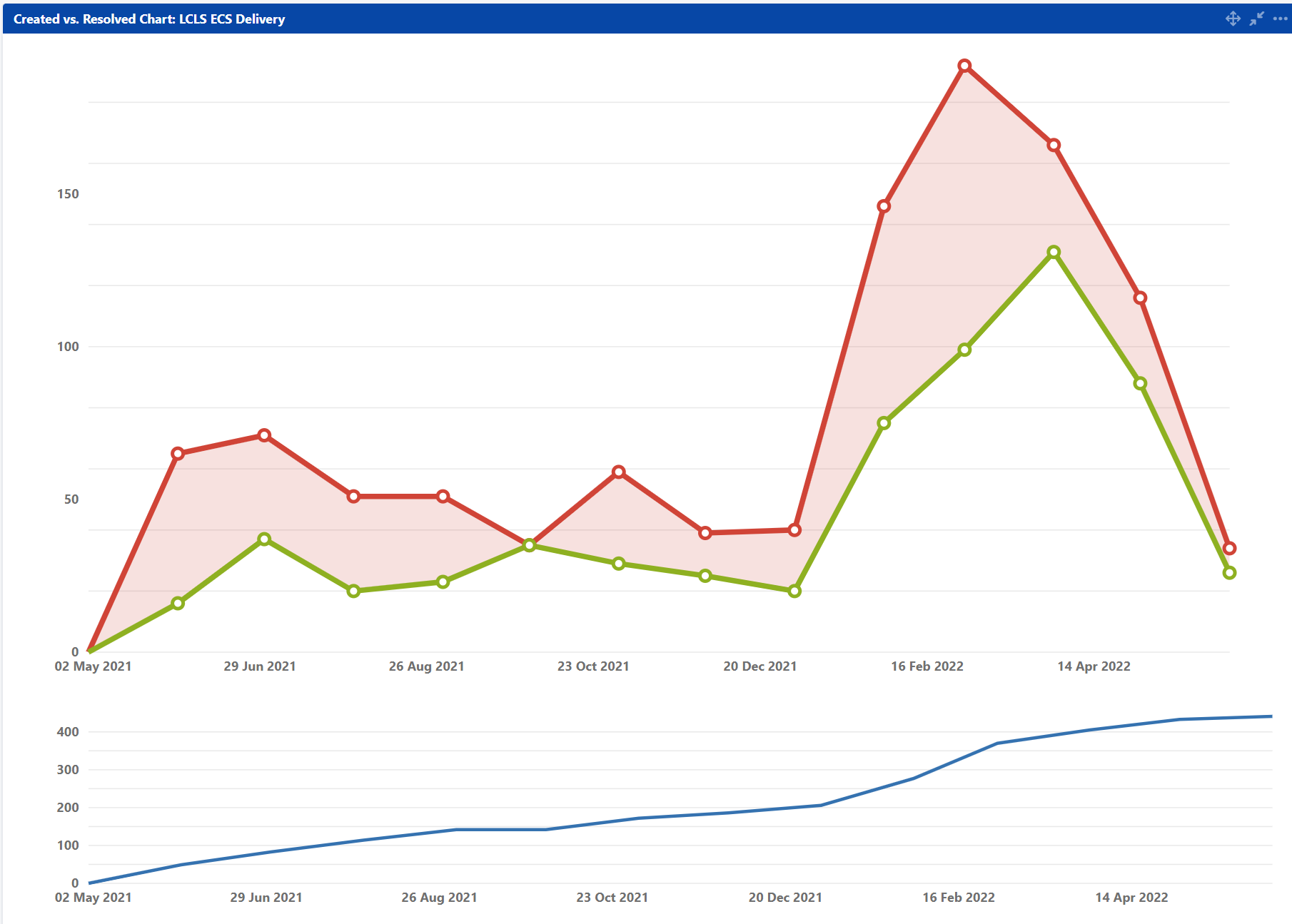
We saw the highest number of resolved issues in March and in general a leveling out of delivery related issues.
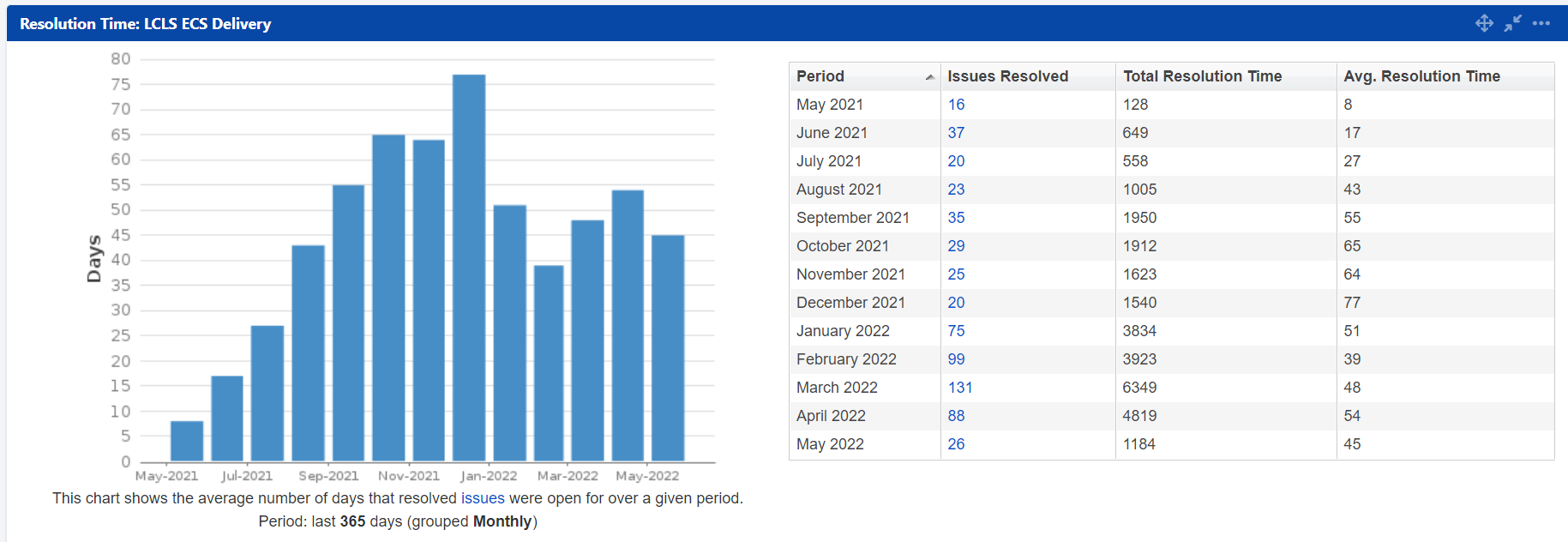
Introduction
The release of this newsletter was delayed and then delayed again as at first we were coming back from a winter break and then trying to wrap up our overhaul of the supported device list (SDL).
Future of Cameras
Collected here are some notes regarding ECS's direction for camera development. Please consider these in the context of your current camera needs and let Silke Nelson and Alex Wallace know if you have any concerns or questions. Our intent is not to disable anything in production or planned, but rather to start to bring some consolidation and uniformity to our vision systems. This is just the start (or is it a continuation) of what will be likely an extended effort to shore up camera reliability and address any outstanding camera integration requests (device and feature).
- Discontinue Pulnix camera usage
- Identified as problematic, and should be replaced at the earliest opportunity.
- Currently classified as DO NOT USE in our SDL.
- Deprioritizing CamLink Development
- Halting further development of CamLink including: new feature requests, new camera integrations, bugfixes, and integration of new libraries.
- Still the only way to get a real "hardware" timestamp on a frame at 120Hz.
- Moving towards USB3
- Current camera integration requests are mostly USB 3
- Prioritizing development of solution for proper timestamping but it seems OK for now (OBO issues).
- See SDL list.
Getting Help from ECS, Seminar
We had another control system seminar in January all about ECS scope and how to use our Jira system to request help from the team.
We think it's a highly valuable presentation for new and veteran LCLS employees to understand what ECS can do for them.
Getting Help From ECS Control System Seminar
All the other control system seminars are posted here: Control System Seminar Series
HE Controls
ECS presented XES controls design status for the February Director's review. The review focused on preparation for CD2/3 with focus on plan, design status and resource profile. The team demonstrated that as per December 2020 DOE Status review recommendation that lessons learned have been addressed and being implemented.
The team also showed the plan and ramp up towards CD2/3 now that we have secured the resources needed to execute the project.
The review committee observed in their reports that our designs appear to be sufficient at this point.
Currently, the team is focused on preparing for the upcoming DOE Review in March.
Controls ICD under review
We recently completed a draft of an ICD for experiment controls for HE and it turned out so well we're thinking about making it a general purpose ICD for ECS to any and all projects going forward. ICD stands for Interface Control Document, and in systems engineering it can have a varied definition. Some projects use ICDs as a way to describe the physical and functional aspects of an interface between two subsystems. In HE and MEC-U's case the ICD will be used to describe the project interface between subsystems, clarifying who has what scope, and what information is needed from ECS and the respective other aspects of the projects.
It's a good document to read and understand because it clarifies what ECS will do in the HE and MEC-U project, and also in general.
ATEF Development
We are working on refocusing our ATEF development efforts, with a primary target of passive testing of control system devices.
The "passive" portion of this means that it will be fully-automated and non-intrusive (will not move your motors or otherwise cause a PV to change).
We are looking to create a configuration GUI for easy specification of these checks and a report generation system for all results.
Future development will include: active tests (guided, with humans in the loop) including integration with bluesky, a synoptic for viewing the atef-reported status of all devices, integration with Grafana, views of devices in typhos/hutch-python at a given time in the past, and many other things.
Alarm System Campaign Kickoff
Federica Murgia has kicked off the design and implementation of the alarm system at LCLS.
The NewALarMSystem, developed by the TID CDS Advanced Controls group, is designed for the availability, integrability, and extensibility of the alarm systems at SLAC.
The installation of the NALMS will start from the FEE in the coming weeks. Future updates will be posted as comments on the Jira ticket.
The scope of the campaign is working to capture and implement alarm thresholds, and hierarchical summaries of alarm states throughout the control systems, using NALMS.
What does this mean? For example, if there is an error with an encoder readback, and it will prevent motion of a diagnostic element, that error will be flagged in EPICS as an alarm, and that alarm could be propagated to a very high-level summary display for operators to understand and trace. So at any given time an operator could see for a given area (like the FEE), if there are ANY issues with mechatronics, and then which component has an issue, and then which sub-component has an issue.
This will not only make our operations more robust as issues can be discovered earlier, but also pave the way for us to obtain real metrics on device reliability and availability.
Experiment State Tracker

One outcome of an LCLS upper-MGMT retreat in December 2022 was the determination that we need more data on how beamtime is spent. Having these metrics will begin to give us an understanding of the impact of various changes we might make to operating procedures, software, hardware, beamline configurations, etc. etc. Basically everything...
It should be noted that this system is a very high-level measurement of a very complex system. Our expectation is to see some correlation of beamtime spending changes to any other changes, but how we will determine a cause is another matter. At the very least it is a start from which we can develop a more refined system health measurement.
The first pass at the state-tracker was assembled by Ken Lauer and Zach Lentz. Further development is owned by Mike Browne with Sebastien Boutet as the stakeholder. If you have any suggestions for features or changes to the state tracker please reach out to Sebastien. If you notice any bugs or issues with the tracker please issue a Jira ticket and let your PoC know.
Grafana Public (login-less) Dashboards
If you have been following the LCLS-II superconducting linac cryomodule cooldown status, you have (perhaps unknowingly) already been using our new non-interactive public-facing Grafana dashboards.
The current list of available dashboards can be found here:
→ https://pswww.slac.stanford.edu/swdoc/ecs_dashboards/ ←
These public-facing dashboards are non-interactive rendered images of the full dashboard. They are accessible to anyone on the Internet, with no SLAC login or affiliation required.
If you have additional dashboards you would like to see listed, please let us know.
ECS Supported Device List
The supported device list (SDL) is a primary component of our Confluence documentation. The original intent of the SDL was to document what kinds of devices users and other LCLS teams could bring to LCLS that could be integrated with the control system (I think). Then it sort of morphed into a list that tried to capture details of any device we had used with the control system. Things like manuals, datasheets, self-written user guides. Our unwritten rule for device support development was to create at least a page for each new device. This resulted in some pages being perfectly sufficient, others being woefully sparse, and still others excessively verbose, nearly to the point of duplicating a manual. Furthermore the SDL became a sort of Interface Control Document (ICD) between PCDS and other teams. Sometimes we might ask, "is it on the SDL?" and if the answer was no, then we didn't support a device. Other times the answer didn't matter. Someone perusing the SDL might occasionally find a listing had a part number, and then place an order without another check and find later that it was a bad part number. Other issues included perhaps ordering a piece of hardware they found on the list, only to find that it had been ordered with a different interface than we had seen before, or any other variety of divergent configurations. There were problems.
So we set out to revamp this crucial piece of documentation. You can see some of our development notes here: 2021-11-12 ECS PDG Meeting Notes 2021-11-19 ECS PDG Meeting Notes.
A few months later and we're nearly done with the overhaul. Of course this is really just the start as not every device has been captured in this pass, and new devices will need integration as we go along. Most of our work focused on stuff that had been in the list before. We defined a standard way of creating new device pages (called stubs), created an easy to use template button, a page labelling scheme to organize our content, and leveraged some cool Confluence macros. We ended up with a collection of stubs, which we then worked on properly organizing (highlighting another area of Confluence that needed attention, our Subsystems area). The stubs have also given us an excellent structure for further organization of our help-guides and notes on particular devices.
Other notable features about the new SDL include: global scope, and the ability to create arbitrary organizations of stubs. The former means anyone anywhere on confluence (in any space), can make a stub, and if they use our labeling scheme, we can include the stub in our lists, meaning our stubs can be merged with other groups' to form a lab-wide view of supported devices. The latter meaning we can organize stubs according to any category we create a label for. As an example, a temperature controller might be used for multiple categories, timing system stabilization and sample delivery instrumentation. By applying each subsystem label, plus one for "thermal controls" we can then present this device in any of those contexts. So anyone perusing our SDL could find that temperature controller multiple ways, meaning there's a better chance of them locating information they need quickly.
Finally one of the best features in the new system is the indication of support status. The previous SDL had to maintain information on all devices in production, even (and maybe even especially) the ones we might have wanted to see retired. This would lead to confusion as other people viewing the list might misunderstand that just because something was on the list didn't mean it was still "supported." Now the SDL uses a specific label for Long Term Support, End of Life and Do Not Use so it is crystal clear if the device you're looking at is really still supported or if we're just keeping a stub around to make sure we never buy another one... More explanation of these terms is available on the SDL page: Supported Devices (SDL).
PS. As the newsletter editor I want to highlight that the SDL overhaul was a herculean team effort and a bit of a grind. Thank you to the team for your dedication to making real progress improving our documentation!
QRIX


We have been busy with testing, checkouts and install of QRIX endstation Controls. The schedule has been pulled forward with tasks that needs to be completed/ready in preparation for Toyama's visit to install and checkout the spectrometer arm.
All the in-vacuum stages have been functionally tested prior to installation.
Installation and termination of 80% of vacuum control components (DRLs and cables) are complete and 50% of motion controls components.
The qRIX Motion and Vacuum PLC are up and running with their IOCs and vacuum screen live and added to RIX LUCID screen.
DC System Procedure Updates
The DC Power confluence page has been updated to include a section on the EEIP standards and processes. The EEIP certification section gives an overview of the EEIP requirements, EEIP reports and documentation required before powering up a new system.
We have a new DC System Checkout Page which can be used as a template for completing DC Certification of new systems and modification to existing systems.
We also have a new DC List of Certification Page which will be used to update any new DC certification and EEIP reports. This will help maintain a database of all the DC certification.
The DC power confluence page has an update on the section Example Component Panels. The section has updated drawings for component PLC & motion DIN Rail. Additionally, a new document has been added for points of contact to remember while doing DC connections on DRL.
Vacuum Control System Architecture Expansions
Adding a new variable leak valve, VAT Series 590 dosing valve, to our supported device list. Check the confluence page here. This valve has integrated controller with EtherCAT interface. One more member to our increasing EtherCAT family! This valve will be installed on TMO vacuum system soon. We will also test two new gauges during March. Watch next month ECS newsletter for the announcement!
MEC-U
Project is on track! This month we are busy with gathering requirements for kicking off the control system design. Continued with LLNL and LLE collaboration meetings on MEC-U laser control systems. We had 4 successful information exchange sessions in the past two months. We will have LLNL & LLE onsite visiting during the next week.
New team members!
| Robert Tang-Kong has joined the ECS Platforms Development team, and will primarily work on the hutch python environments. Prior to joining ECS, Robert got his PhD in Materials Science at Stanford and worked at SSRL as part of their data acquisition pilot project. In his downtime, Robert enjoys reliving his glory days in competitive yo-yoing and playing video games. |
| Peregrine McGehee has joined the ECS Delivery group as the new MEC PoC. His background includes teaching physics and astronomy at Ventura College, working as a staff astronomer at NASA'S Infrared Processing and Analysis Center, and prior to that as a controls engineer at the Los Alamos Neutron Science Center. A few other things that take his time include being a co-chair of one of the Rubin Observatory science collaborations and continuing the study of Balinese gamelan. | |
| Mike Estrada Mike Estrada has joined ECS as the new PoC for the XBD group. His hobbies include weightlifting, seeing live music, cooking, trying new restaurants, and travelling. He likes to fill his spare hours playing video games, visiting with family, and going wine tasting. |


Jira
We're getting better at Jira. Check it out:
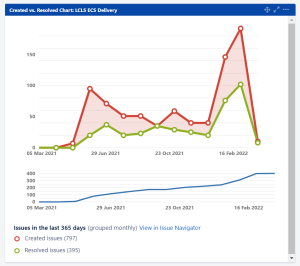
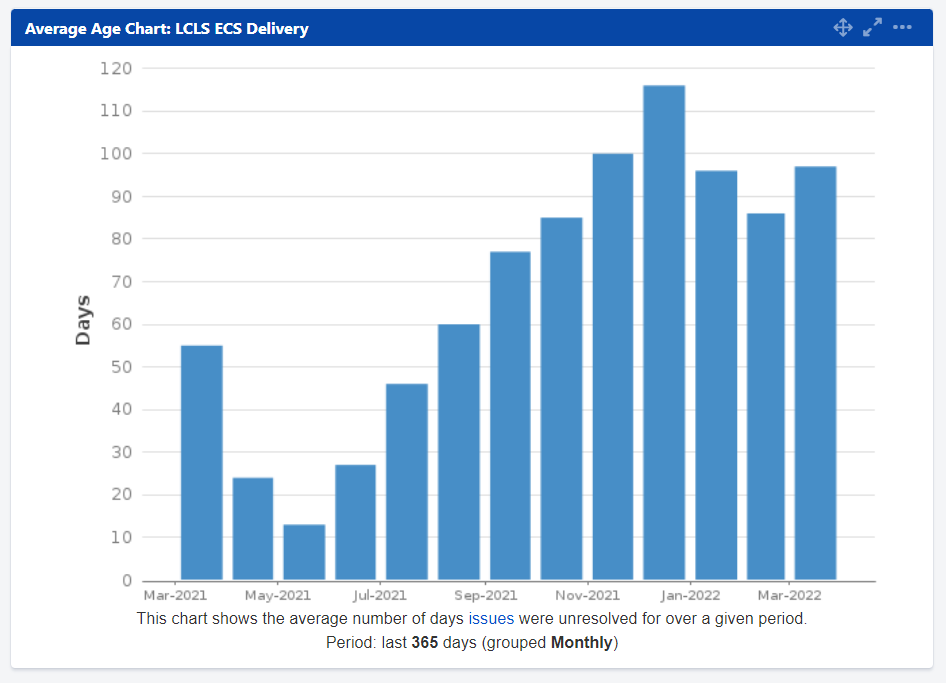
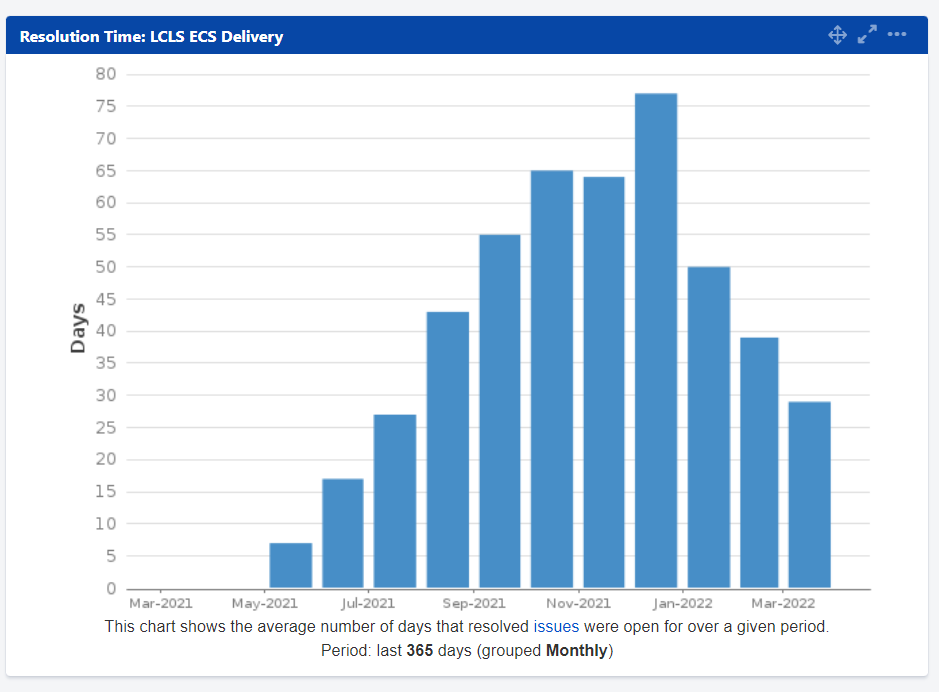
Our unresolved tickets grew by about 50% from December to the end of February. We're keeping pace, and perhaps with our new resolution workflows we'll start to cut down on the complete backlog.
One thing to note is we'll soon cross a point where it is a good idea to check Jira for prior tickets before submitting a new one. Much like Stack Overflow, Jira tickets are a kind of knowledgebase.
Note, the list below might have some tickets on it that were resolved in an earlier period. Due to a confluence workflow change some statuses were changed to "Closed" or "Done" again in January. This issue only appears to affect this Confluence-Jira plugin.