TULIP results
Faisal generated TULIP results for SLAC as target (134.79.18.188) and TULIP geo-located it to be in Wyoming. Screenshot here. This is obviously way off.
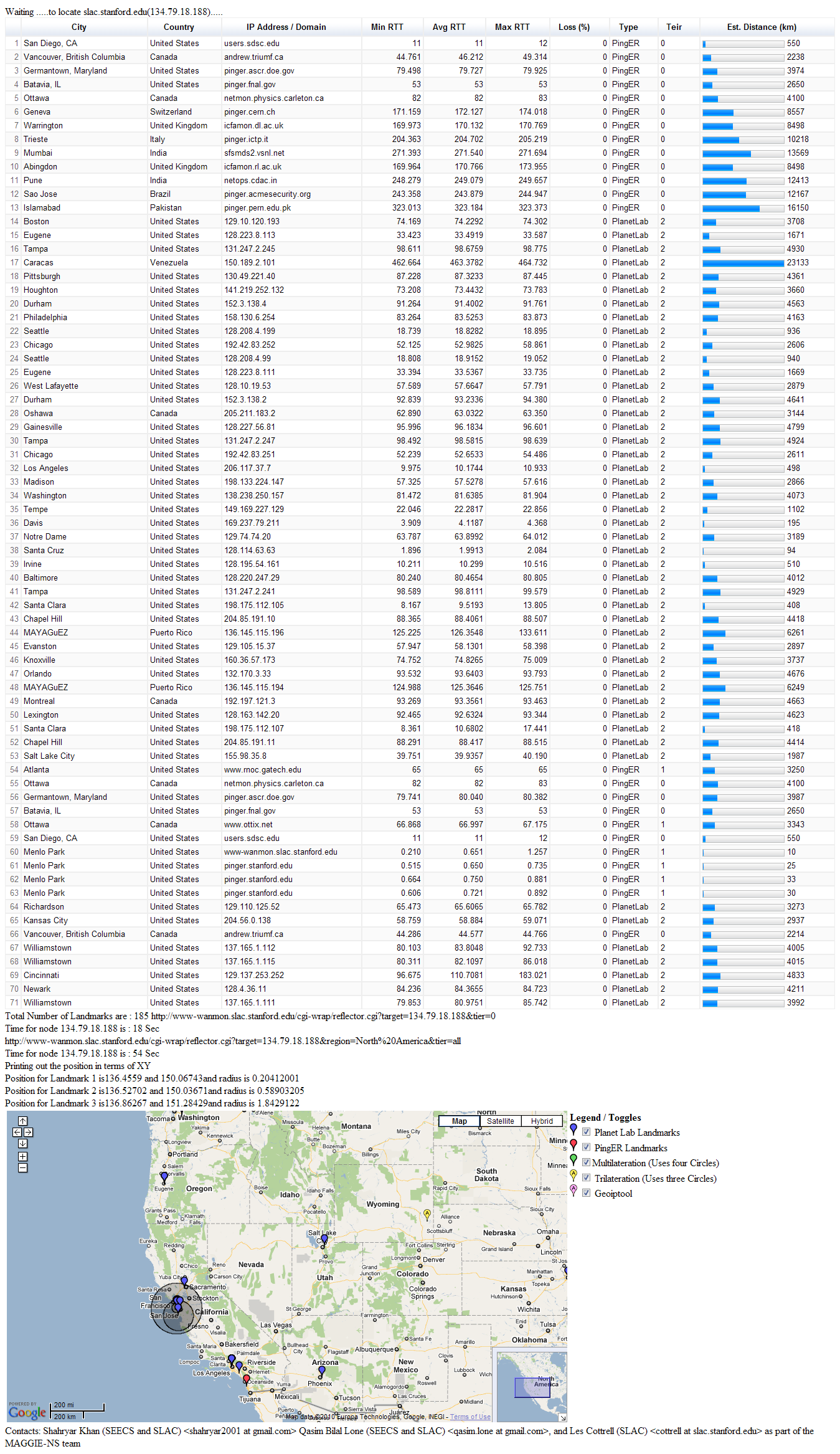{kind=link}
CBG results
Dr. Les quickly explained to me what TULIP was doing and wanted to do a quick analysis of the same location (i.e. SLAC) using CBG with tri-lateration. So I found a target located at SLAC (134.79.18.134) in CBG list. We ran CBG with tri-lateration for this target. The results were way off. The error distance was of the order of ~3200 km.
However Dr. Les pointed out that we should be using three landmarks that have the minimum RTT values from the target. Thus we shuffled our values accordingly and re-ran the test with two different set of landmarks. This helped to verify our results. Table below shows the results:
Landmark 1 |
Landmark 2 |
Landmark 3 |
Error (km) |
Distance to nearest landmark (km) |
Area of Region (km) |
Est. Lat/Long |
Actual Lat/Long36.9899 -122.06 |
|---|---|---|---|---|---|---|---|
36.9899 -122.06 (Santa Cruz) |
38.4829 -121.64 (Davis) |
37.3558 -121.954 (Santa Clara) |
25.254 |
2.5132 |
1498.5 |
37.474 -121.93 |
37.418 -122.2 |
37.4285 -122.178 (Stanford) |
37.3762 -122.183 (Palo Alto) |
37.3558 -121.954 (Santa Clara) |
2.5156 |
2.5132 |
1048.8 |
37.429 -122.18 |
37.418 -122.2 |
Other results are also encouraging, so far I've analyzed around 20 targets, comparing multi-lateration and tri-lateration results. CBG with tri-lateration seems to be performing well.
Points to consider
These results prove that tri-lateration works. So the question is why is TULIP failing so miserably?
CBG multi-lateration vs CBG tri-lateration comparison
Spreadsheet here shows a comparison of error (in km) between CBG with multi-lateration and CBG with tri-lateration. The technique I've followed:
- Sorting target lists in ascending order on the basis of distance between the target location and landmark location.
- Re-running the CBG code for new results.
- Populated the spreadsheet with results.
What I didn't do so far and why:
- Avoiding duplicate landmarks.
- Reason: If you look at the spreadsheet you will notice that there are duplicate entries for multi-lateration as well. You can infer this from matching Estimated Lat/Longs to Actual Lat/Longs and by observing the distance to the nearest landmark values. Also a few targets don't have more than two landmarks and in all such cases those are duplicates (in terms of Lat/Longs). So in such a case I don't have an option but to use the duplicate ones. However I do require comments on this - whether I should remove duplicates or not. The two reasons of my concern are that multi-lateration uses duplicate landmark values and a few targets having none but duplicate landmarks.
- Avoiding landmarks present within a target's vicinity. This requires taking note of the location.
- Reason: Closely related to the point mentioned above.
What I've tried and didn't work:
- Sorting target lists on the basis of RTT to bring those landmarks at the top (of the Target files) which have lowest RTT values. This technique fails since in some cases the top three landmarks in the Target files are located thousands of kilometers apart. I don't know how these landmarks managed to have such low RTT values from the target. CBG with tri-lateration failed on such a sorting technique .. because landmarks were way off!
Results, some discrepancies and explanation
In the spreadsheet we have made various calculations in order to understand the results.
1. Amount of NaNs in error for multi-lateration and tri-lateration
67/171 for multi-lateration and 6/171 for tri-lateration.
NaN (Not a Number) is a value of numeric data-type representing an undefined or unrepresentable value, especially in floating point calculations. Reference and more [here|http://en.wikipedia.org/wiki/NaN![]() ].
].
According to the CBG code NaNs represent "bad pairs that lead to no region". This means that landmarks that fail to produce intersection regions, consequently also fail to produce an estimate for the location of the target and instead giving out an erroneous value. Author has handled such values with NaN (code snippet below).
if constraintType
warning('Trying speed of light')
constraintType = 0;
% switch the constraint type and try again
[locest,actual,error,regarea,distNearestLandmark,target_id,constraintType,inRegion\] = geolocate(file,extension,hullbool, constraintType, bestlineTable);
return;
else
% find the badPairs that lead to no region, write them to stdout
badPairs = analyzeNoRegion( measurements )
%error(\['No SOL intersection region for ', char(file)\])
region = \[NaN NaN\];
locest = \[NaN NaN\];
error = NaN;
regarea = NaN;
results = \[target_id error; distNearestLandmark regarea; locest; actual; region\];
dlmwrite(\[char(file),char(extension)\],results,' ');
return;
end;