def calib_jungfrau(det, evt, cmpars=(7,3,200,10), **kwa):
"""
Returns calibrated jungfrau data
- gets constants
- gets raw data
- evaluates (code - pedestal - offset)
- applys common mode correction if turned on
- apply gain factor
Parameters
- det (psana.Detector) - Detector object
- evt (psana.Event) - Event object
- cmpars (tuple) - common mode parameters
- cmpars[0] - algorithm # 7-for jungfrau
- cmpars[1] - control bit-word 1-in rows, 2-in columns
- cmpars[2] - maximal applied correction
- **kwa - used here and passed to det.mask_v2 or det.mask_comb
- nda_raw - if not None, substitutes evt.raw()
- mbits - DEPRECATED parameter of the det.mask_comb(...)
- mask - user defined mask passed as optional parameter
"""
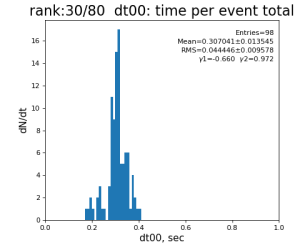
t00 = time()
src = det.source # - src (psana.Source) - Source object
nda_raw = kwa.get('nda_raw', None)
arr = det.raw(evt) if nda_raw is None else nda_raw # shape:(<npanels>, 512, 1024) dtype:uint16
if arr is None: return None
t01 = time()
peds = det.pedestals(evt) # - 4d pedestals shape:(3, 1, 512, 1024) dtype:float32
if peds is None: return None
t02 = time()
gain = det.gain(evt) # - 4d gains
offs = det.offset(evt) # - 4d offset
t03 = time()
detname = string_from_source(det.source)
cmp = det.common_mode(evt) if cmpars is None else cmpars
t04 = time()
if gain is None: gain = np.ones_like(peds) # - 4d gains
if offs is None: offs = np.zeros_like(peds) # - 4d gains
# cache
gfac = store.gfac.get(detname, None) # det.name
if gfac is None:
gfac = divide_protected(np.ones_like(peds), gain)
store.gfac[detname] = gfac
store.arr1 = np.ones_like(arr, dtype=np.int8)
t05 = time()
# Define bool arrays of ranges
# faster than bit operations
gr0 = arr < BW1 # 490 us
gr1 =(arr >= BW1) & (arr<BW2) # 714 us
gr2 = arr >= BW3 # 400 us
t06 = time()
# Subtract pedestals
arrf = np.array(arr & MSK, dtype=np.float32)
t07 = time()
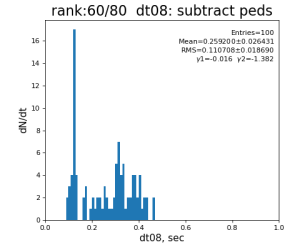
arrf[gr0] -= peds[0,gr0]
arrf[gr1] -= peds[1,gr1] #- arrf[gr1]
arrf[gr2] -= peds[2,gr2] #- arrf[gr2]
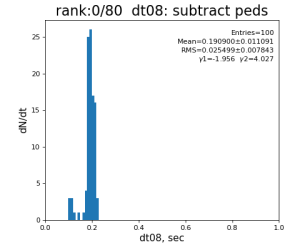
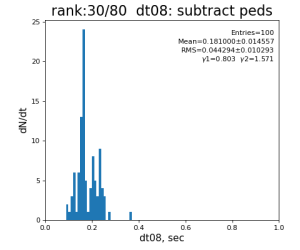
t08 = time()
factor = np.select((gr0, gr1, gr2), (gfac[0,:], gfac[1,:], gfac[2,:]), default=1) # 2msec
t09 = time()
offset = np.select((gr0, gr1, gr2), (offs[0,:], offs[1,:], offs[2,:]), default=0)
t10 = time()
arrf -= offset # Apply offset correction
t11 = time()
if store.mask is None:
store.mask = det.mask_total(evt, **kwa)
mask = store.mask
t12 = time()
if cmp is not None:
mode, cormax = int(cmp[1]), cmp[2]
npixmin = cmp[3] if len(cmp)>3 else 10
if mode>0:
#arr1 = store.arr1
#grhg = np.select((gr0, gr1), (arr1, arr1), default=0)
logger.debug(info_ndarr(gr0, 'gain group0'))
logger.debug(info_ndarr(mask, 'mask'))
t0_sec_cm = time()
gmask = np.bitwise_and(gr0, mask) if mask is not None else gr0
#sh = (nsegs, 512, 1024)
hrows = 256 #512/2
for s in range(arrf.shape[0]):
if mode & 4: # in banks: (512/2,1024/16) = (256,64) pixels # 100 ms
common_mode_2d_hsplit_nbanks(arrf[s,:hrows,:], mask=gmask[s,:hrows,:], nbanks=16, cormax=cormax, npix_min=npixmin)
common_mode_2d_hsplit_nbanks(arrf[s,hrows:,:], mask=gmask[s,hrows:,:], nbanks=16, cormax=cormax, npix_min=npixmin)
if mode & 1: # in rows per bank: 1024/16 = 64 pixels # 275 ms
common_mode_rows_hsplit_nbanks(arrf[s,], mask=gmask[s,], nbanks=16, cormax=cormax, npix_min=npixmin)
if mode & 2: # in cols per bank: 512/2 = 256 pixels # 290 ms
common_mode_cols(arrf[s,:hrows,:], mask=gmask[s,:hrows,:], cormax=cormax, npix_min=npixmin)
common_mode_cols(arrf[s,hrows:,:], mask=gmask[s,hrows:,:], cormax=cormax, npix_min=npixmin)
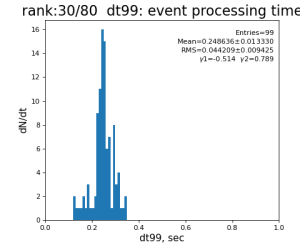
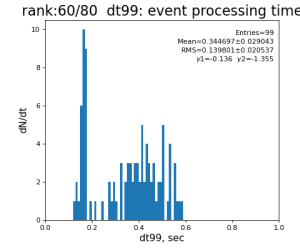
logger.debug('TIME: common-mode correction time = %.6f sec' % (time()-t0_sec_cm))
t13 = time()
resp = arrf * factor if mask is None else arrf * factor * mask # gain correction
t14 = time()
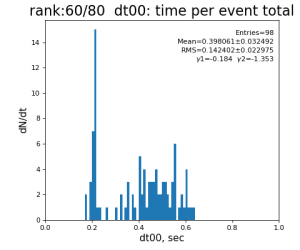
times = np.array((t00, t01, t02, t03, t04, t05, t06, t07, t08, t09, t10, t11, t12, t13, t14), dtype=np.float64)
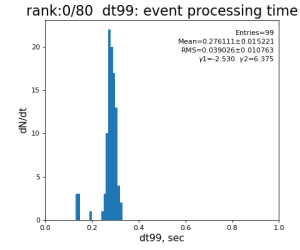
return resp, times