Overview
In this project we study and investigate network anomaly detection algorithms [1], [2] and [3] for Internet Paths. We also develop a Decision Theoretic Approach (DTA) based on our observations regarding the characteristics of the performance-measurement statistics obtained from the IEPM-BW project.
To study and compare the algorithms we use the data sets collected by IEPM-BW spanning approximately 2 years (i.e. 2006 - 2008). The Internet paths observed were the links between Stanford Linear Accelerator Center (SLAC) and the following sites:
- San Diego Supercomputing Center (SDSC) USA,
- Oak Ridge National Laboratory (ORNL) USA,
- European Organization for Nuclear Research (CERN) Geneva, Switzerland,
- Forschungszentrum Karlsruhe (FZK) Germany,
- Deutsches Elektronen-Synchrotron (DESY) Germany,
- University of Toronto (UTORONTO) Canada and
- National Laboratory for Particle and Nuclear Physics (TRIUMF) Canada.
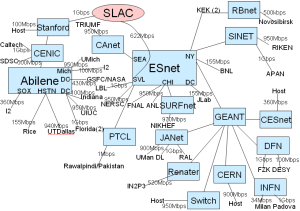
The topology of the monitoring framework is shown in figure 1.
Fig. 1: Topology of IEPM as of 07/2008 |
|---|
|
Data Sets
The data sets used in the study may be downloaded from the links listed below. These data sets were collected by the IEPM-BW project and the latest performance statistics may be accessed from here.
Table 1: Performance measurement statistics compiled by IEPM, as seen from SLAC.
|
Raw data |
Labeled data |
|||||
|---|---|---|---|---|---|---|---|
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="e31fb701-b40a-4ce1-8ef8-e5e95065c475"><ac:plain-text-body><![CDATA[ |
SDSC |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/SDSC-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/SDSC-pathchirp.xls]] |
[[txt |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/UTORONTO-pathchirp-labeled-events.txt]] |
]]></ac:plain-text-body></ac:structured-macro> |
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="72674ee6-dec5-484b-93b7-c127ac64d8b7"><ac:plain-text-body><![CDATA[ |
CERN |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/CERN-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/CERN-pathchirp.xls]] |
[[txt |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/CERN-pathchirp-labeled-events.txt]] |
]]></ac:plain-text-body></ac:structured-macro> |
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="396c0d75-9b8c-4f52-9c4d-d72e9995f551"><ac:plain-text-body><![CDATA[ |
FZK |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/FZK-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/FZK-pathchirp.xls]] |
[[txt |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/FZK-pathchirp-labeled-events.txt]] |
]]></ac:plain-text-body></ac:structured-macro> |
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="3d4565ab-1d8d-4526-955e-a625a4b99feb"><ac:plain-text-body><![CDATA[ |
DESY |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/DESY-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/DESY-pathchirp.xls]] |
[[txt |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/DESY-pathchirp-labeled-events.txt]] |
]]></ac:plain-text-body></ac:structured-macro> |
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="3d9f59a4-4dd7-4b45-b95c-efdcdb2faf04"><ac:plain-text-body><![CDATA[ |
UTORONTO |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/UTORONTO-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/UTORONTO-pathchirp.xls]] |
[[txt |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/UTORONTO-pathchirp-labeled-events.txt]] |
]]></ac:plain-text-body></ac:structured-macro> |
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="93533f44-db00-41fd-b4d3-9492967a2451"><ac:plain-text-body><![CDATA[ |
TRIUMF |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/TRIUMF-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/TRIUMF-pathchirp.xls]] |
[[txt |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/TRIUMF-pathchirp-labeled-events.txt]] |
]]></ac:plain-text-body></ac:structured-macro> |
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="dad05b86-6551-47f5-8ff1-233d1eac8b19"><ac:plain-text-body><![CDATA[ |
ORNL |
[[csv |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/ORNL-pathchirp.csv]], [[xls |
http://www.slac.stanford.edu/~kalim/event-detection/published-data/ORNL-pathchirp.xls]] |
[txt] |
]]></ac:plain-text-body></ac:structured-macro> |
Download the complete data archive [zip![]() 10 MB] or [7z
10 MB] or [7z![]() 8 MB]
8 MB]
Labeling and Detection Algorithms
To perform a fair comparison between [1], [2], [3] and the proposed DTA we devised a labeling algorithm to identify true anomalies in the data sets. This labeled data was then used to determine the accuracy (true-positive rate), corresponding false-positive rate and the detection delay.
Events
Before we proceed to discuss the labeling algorithm we define anomalous events as "a set of anomalous observations is called an event if the deviant observations persist for a period greater than or equal to a defined epoch". With reference to the IEPM data, we define the epoch to span at least 3 hours.
Given a set of bandwidth measurements, extraction of the baseline behavior essentially entails removing all anomalous observations (and the corresponding bandwidth values) from the set. The remaining measurements can then be used to characterize the baseline behavior. Anomalous bandwidth values always cause significant fluctuations in the measurements, albeit these fluctuations may be sustained or spurious in nature.
To remove the anomalous bandwidth measurements from the dataset, we apply an n-tap median filter to the dataset. A median filter is a sliding window low-pass filter that stores n previous values of the input and at each step outputs the median of the stored values. Consequently, high frequency spikes are removed from the input data. Note that the value of n is a crude upper bound on the maximum duration for an anomaly. If a bandwidth change sustains itself beyond n observations then it is treated as a change in the underlying baseline behavior. Therefore, care should be exercised in choosing the value of n for a given bandwidth measurement dataset. We define an empirical lower bound on n as
n <= 2 * d * u
where d is the epoch and u is the average number of IEPM performance measurements made in one hour. In the present dataset, we observed that a maximum value of n=15 is sufficient to remove sustained and spurious bandwidth fluctuations.
The median filtered dataset are treated as normal bandwidth values of an Internet path. The baseline behavior is then characterized by computing the mean of the filtered measurements. Then as per our definition an anomaly is flagged when an anomaly deviates significantly from this baseline behavior and sustains itself for more than 3 hours.
To flag significant deviations, we first compute the mean of the baseline. We then analyze the measurements in sub-sets (windows) of length 3. The mean of the window is computed and a test is performed such that:
0.5 <= (mean of window)/(mean of filtered data) <= 1.5
We opt for such thresholds in light of definition of an event. In order to define an observation as anomaly, we conclude that it should be significantly different from the baseline observations. In order to define 'significant difference' we manually observed data sets with and without anomalies. Our empirical observation suggests that nearly 6% of the observations show a difference of greater than or equal to 50% from the mean observation. This result is summarized in Fig. 2 below. Also, such deviant observations tend to maintain their state and feature small variation (irrespective of the duration of the event) thereby endorsing the fact that significant change is primarily observed in the mean observations and not in the variance.
Fig. 2. Percentage of Measurements significantly different from normal observations.
SLAC-UTORONTO |
SLAC-DESY |
|---|---|
|
|


The labeling algorithm and the decision theoretic approach for real-time anomaly detection are discussed at length in the research paper [F. Hussain, U. Kalim, N. Latif, S. A. Khayam, "A Decision-Theoretic Approach to Detect Anomalies in Internet Paths", submitted to INFOCOM 2009].
Implementations and Parameter Tuning
The source code of the implementations and the tuning of parameters is discussed below. Please consider two important factors while we discuss the parameters tuning: a) We define an anomalous event as one which significantly varies from the normal behaviour of the Internet Path and the perturbation persists for at least three hours. b) The measurements made by IEPM-BW are at least 45 mins apart.
Fig. 2: ROC curves for Plateau (PL), |
|---|
|

a) Plateau Algorithm
The Plateau Algorithm![]() [1] takes four input parameters - history buffer length, trigger buffer length, sensitivity and threshold. We define the trigger buffer length to hold observations spanning at least 3 hours (since we define an anomalous event as one that persists for at least 3 hours). Since the measurements made by IEPM are 45 mins apart, we get about 6 observations. We then empirically determine the optimal length of the history buffer to span at least 5 days ~ 240 observations.
[1] takes four input parameters - history buffer length, trigger buffer length, sensitivity and threshold. We define the trigger buffer length to hold observations spanning at least 3 hours (since we define an anomalous event as one that persists for at least 3 hours). Since the measurements made by IEPM are 45 mins apart, we get about 6 observations. We then empirically determine the optimal length of the history buffer to span at least 5 days ~ 240 observations.
We initially define the sensitivity as one (1) and determine the optimal threshold value for each link (i.e. the value with the optimal ratio of true-positives to false positives). As suggested by the authors, this threshold falls between 30%-40%. Finally for the history buffer length, the trigger buffer length and the optimal threshold, we vary the sensitivity to determine the spectrum of the ratio of true-positive rate to false positive rate. Based on the observations we plot the ROC curves as shown in figure 2. One set of data points is shown in table 2.
Table 2: Results compiled by Plateau algorithm when analyzing the Internet path between SLAC and DESY.
H |
TB |
TH |
S |
TP |
FP |
#P |
N~days |
TPR |
FPR |
|---|---|---|---|---|---|---|---|---|---|
240 |
45 |
30% |
2.3 |
0 |
25 |
31 |
672 |
0 |
0.037 |
240 |
40 |
30% |
2.2 |
1 |
28 |
31 |
672 |
0.032 |
0.042 |
240 |
32 |
30% |
2.1 |
1 |
32 |
31 |
672 |
0.032 |
0.048 |
240 |
28 |
30% |
2.0 |
2 |
35 |
31 |
672 |
0.065 |
0.052 |
240 |
24 |
30% |
1.9 |
2 |
41 |
31 |
672 |
0.065 |
0.061 |
240 |
19 |
30% |
1.8 |
4 |
50 |
31 |
672 |
0.129 |
0.074 |
240 |
16 |
30% |
1.7 |
6 |
59 |
31 |
672 |
0.194 |
0.088 |
240 |
13 |
30% |
1.6 |
7 |
66 |
31 |
672 |
0.226 |
0.098 |
240 |
10 |
30% |
1.5 |
11 |
74 |
31 |
672 |
0.355 |
0.11 |
240 |
9 |
30% |
1.4 |
13 |
81 |
31 |
672 |
0.419 |
0.121 |
240 |
8 |
30% |
1.3 |
14 |
97 |
31 |
672 |
0.452 |
0.144 |
240 |
7 |
30% |
1.2 |
16 |
103 |
31 |
672 |
0.516 |
0.153 |
240 |
6 |
30% |
1.1 |
20 |
114 |
31 |
672 |
0.645 |
0.17 |
240 |
6 |
30% |
1.0 |
21 |
122 |
31 |
672 |
0.677 |
0.182 |
Legend:
H - History buffer length, TB - Trigger buffer length, TH - threshold, S - sensitivity, TP - true positives obtained, FP - false positives obtained, #P - true positives, N~days - days observed, TPR - true positive rate, FPR - false positive rate.
The source code of the implementation is available in C#![]() [cs
[cs![]() ] and perl
] and perl![]() [pl
[pl![]() ]
]
b) Adaptive Fault Detection
The Adaptive Fault Detection [3] method employs four parameters - the desidred detection rate, the desired false positive rate, the history buffer length and the observed window length. We use the values as suggested by the author and for observed window length of 20, a history buffer length of 100 and the desired detection rate of 0.95 and we vary the desired false positive rate to obtain the spectrum of the ratio of true-positive rate to false positive rate. Based on the observations we plot the ROC curves as shown in figure 2. One set of data points is shown in table 3.
Table 3: Results compiled by Adaptive Fault Detection (ADF) method when analyzing the Internet path between SLAC and DESY.
N |
HN |
B |
a |
TP |
FP |
#P |
N~days |
TPR |
FPR |
|---|---|---|---|---|---|---|---|---|---|
20 |
100 |
0.95 |
0.0300 |
0 |
31 |
31 |
672 |
0 |
0.046 |
20 |
100 |
0.95 |
0.0200 |
2 |
90 |
31 |
672 |
0.065 |
0.134 |
20 |
100 |
0.95 |
0.0090 |
6 |
619 |
31 |
672 |
0.194 |
0.921 |
20 |
100 |
0.95 |
0.0080 |
9 |
796 |
31 |
672 |
0.29 |
1.185 |
20 |
100 |
0.95 |
0.0070 |
16 |
994 |
31 |
672 |
0.516 |
1.479 |
20 |
100 |
0.95 |
0.0050 |
23 |
1672 |
31 |
672 |
0.742 |
2.488 |
20 |
100 |
0.95 |
0.0040 |
23 |
2179 |
31 |
672 |
0.742 |
3.243 |
20 |
100 |
0.95 |
0.0030 |
29 |
2837 |
31 |
672 |
0.935 |
4.222 |
20 |
100 |
0.95 |
0.0023 |
30 |
3528 |
31 |
672 |
0.968 |
5.25 |
20 |
100 |
0.95 |
0.0022 |
31 |
3611 |
31 |
672 |
1 |
5.374 |
Legend:
HN - History buffer length, a - desired false positive rate, B - desired detection rate, N - observed window length, TP - true positives obtained, FP - false positives obtained, #P - true positives, N~days - days observed, TPR - true positive rate, FPR - false positive rate.
The source code of the implementation is available in C#![]() [cs
[cs![]() ].
].
c) Kalman Filters
The Kalman Filter [2] method employs two input parameters - the observed window length and the Kalman gain. We use the values as suggested by the author and for the observed window length and vary the kalman gain to obtain the spectrum of the ratio of true-positive rate to false positive rate. Based on the observations we plot the ROC curves as shown in figure 2. One set of data points is shown in table 4.
Table 4: Results compiled by Kalman Filters (KF) method when analyzing the Internet path between SLAC and DESY.
W |
K |
TP |
FP |
#P |
N~days |
TPR |
FPR |
|---|---|---|---|---|---|---|---|
3 |
0.800 |
1 |
309 |
31 |
672 |
0.032 |
0.46 |
6 |
0.500 |
2 |
333 |
31 |
672 |
0.065 |
0.496 |
6 |
0.100 |
3 |
366 |
31 |
672 |
0.097 |
0.545 |
6 |
0.005 |
3 |
371 |
31 |
672 |
0.097 |
0.552 |
6 |
0.001 |
3 |
371 |
31 |
672 |
0.097 |
0.552 |
Legend:
W- observed window length, K - kalman gain, TP - true positives obtained, FP - false positives obtained, #P - true positives, N~days - days observed, TPR - true positive rate, FPR - false positive rate.
The source code of the implementation is available in C#![]() [cs
[cs![]() ]. (not up to date, will be revised soon)
]. (not up to date, will be revised soon)
d) Decision Theoretic Approach
Decision Theoretic Approach employs four parameters - the desired false positive rate (alpha), the desired detection rate (beta), the history buffer length and the low-pass median filter length. We apply the median filter of minimum length 7 to remove the high frequency component. We then determine the optimum history buffer length by empirical observation. This turns out to be 90. Opting for the maximum detection rate of 0.99, we vary the desired false positive rate to obtain the entire spectrum of the ratio of true-positive rate to false positive rate. Based on the observations we plot the ROC curves as shown in figure 2. One set of data points is shown in table 5.
This algorithm use three parameters one is threshold which is calculated in terms of Alpha and Beta, and other two are buffer lengths (History buffer and n-Tap Median filter). Same scheme is used for this algorithm, such that minimum value of n = 7 is used for n-Tap Median filter with some appropriate value of History buffer. By keeping these values same and changing different values of Alpha and Beta (Threshold) for each dataset ROCs are generated.
Table 5: Results compiled by the proposed DTA when analyzing the Internet path between SLAC and DESY.
H |
a |
B |
n-tap |
TP |
FP |
#P |
N~days |
TPR |
FPR |
|---|---|---|---|---|---|---|---|---|---|
90 |
0.01100 |
0.99 |
7 |
0 |
9 |
31 |
672 |
0 |
0.013 |
90 |
0.01150 |
0.99 |
7 |
4 |
9 |
31 |
672 |
0.129 |
0.013 |
90 |
0.01200 |
0.99 |
7 |
4 |
12 |
31 |
672 |
0.129 |
0.018 |
90 |
0.01400 |
0.99 |
7 |
13 |
26 |
31 |
672 |
0.419 |
0.039 |
90 |
0.01600 |
0.99 |
7 |
17 |
31 |
31 |
672 |
0.548 |
0.046 |
90 |
0.01800 |
0.99 |
7 |
18 |
45 |
31 |
672 |
0.581 |
0.067 |
90 |
0.02000 |
0.99 |
7 |
22 |
69 |
31 |
672 |
0.71 |
0.103 |
90 |
0.02100 |
0.99 |
7 |
25 |
84 |
31 |
672 |
0.806 |
0.125 |
90 |
0.02160 |
0.99 |
7 |
29 |
88 |
31 |
672 |
0.935 |
0.131 |
90 |
0.02163 |
0.99 |
7 |
29 |
91 |
31 |
672 |
0.935 |
0.135 |
90 |
0.02164 |
0.99 |
7 |
30 |
91 |
31 |
672 |
0.968 |
0.135 |
Legend:
H - History buffer length, a - desired false positive rate, B - desired detection rate, n-tap - median filter length, TP - true positives obtained, FP - false positives obtained, #P - true positives, N~days - days observed, TPR - true positive rate, FPR - false positive rate.
The source code of the implementation is available in C#![]() [cs
[cs![]() ] and perl
] and perl![]() [pl
[pl![]() ] (utilityFunctions
] (utilityFunctions![]() [pm
[pm![]() ], conf
], conf![]() ).
).
References
- C. Logg, L. Cottrell, and J. Navratil. Experiences in traceroute and available bandwidth change analysis. In NetT '04: Proceedings of the ACM SIGCOMM workshop on Network troubleshooting, pages 247-252. ACM, 2004.
- A. Soule, K. Salamatian, and N. Taft. Combining filtering and statistical methods for anomaly detection. In Internet Measurement Conference (IMC 2005), pages 331-344. USENIX, 2005.
- H. Hajji. Statistical analysis of network traffic for adaptive faults detection. In IEEE Transactions on Neural Networks, pages 1053-1063, 2005.