ATLAS twiki page for T539: https://twiki.cern.ch/twiki/bin/viewauth/Atlas/RadDamageTBSpring2016
Event log
Jul/06
- Caladium back to beam line, but chillier not yet on and g-2 platform post is blocking beam line to the dump.
- Cleaned up the remnants of g-2 from DUT rack. Mounted DUT rotation stage. Reconfigured the web cams and updated the confluence portal list.
- Queuing one BK Precision 9130 supply for survey to exit ESA for let Mike Dunning working on its RS232 interface for EPICS.
Jul/07
Operations team: Maurice Garcia-Sciveres, Katie Dunne, Su Dong
Maurice's CMOS sensor shipped to SLAC from Sensor Creator's Inc directly. A 'camera' like standalone readout unit connecting the sensor via a thin flex. Beamline support scheme worked out with Matt McCulloch with CMOS sensor taped behind the 94-04-03 double chip FE-I4 module. Vertical readout chain to allow easy rotation. Ethernet port address 192.168.2.1. |  |
|---|
- Doug McCormick turned on chiller, moved aside g-2 stage and reordered web cams.
- Alignment encountered several issues: coarse Y appeared to be not stopping and having strange pauses during moves. Coarse X is at hard limit and we are still ~2cm off. Fine XY panel scale factor didn't look right. Rotation goes scarily fast.
- Caladium commissioning got stuck on NI crate not ping-able. Traced the network route for NI crate and DUT Sun server to table below. Early stage found NI crate power dropped - tracked to loose power cable at the back, but firm reconnect didn't get it back still. tried to swap NI crate's Belden channel to 22 but made no difference.
| Node | IP name | IP address | Tunnel cable | Belden PP chan | Switch port | swh-b061-nw01 |
|---|---|---|---|---|---|---|
| NI crate | ni-eudaq | 172.27.104.9 | 3 | 20 | 32 | Gi1/0/32 |
| DUT Sun server | esadutdaq1 | 172.27.104.45 | 2 | 19 | 33 | Gi1/0/33 |
- Prep-prod HSIO-2 X1 moved into ESTB tunnel DUT rack. Network table needed update of HSIO-2 MAC address.
- CMOS cam ethernet readout needs to find a host server. Sun server esadutdaq1 both ports occupied.
Jul/08
Operations team: Maurice Garcia-Sciveres, Katie Dunn, Su Dong
- Doug McCormick and Juan Cruz moved the whole Caladium to the south (-x) by 25mm to center the telescope to beam and still in the middle X coarse range. Also adjusted the yaw.
- Following recommendation from Matthias Wittgen and Martin Kocian to add a NetGear G105 router between Sun server and readout devices such as HSIO2 and the CMOS cam so that the single DUT readout ETH1 port of the Sun server can take in multiple DUT readout sources in a private network. To avoid the complication of changing the CMOS cam IP config, the RCE and Sunserver private network IPs are modified to create a common private network:
| Node | Node name | DUT private network IP |
|---|---|---|
| DUT Sun Server | esadutdaq1 | 192.168.2.3 |
| HSIO-2 RCE | rce0 | 192.168.2.10 |
| CMOS cam | 192.168.2.1 |
- Mike Dunning and Juan Cruz helped to debug the NI crate unreachable issue. Belden channel moved to 22 and again verified made no difference. Hooked up a monitor to NI crate discovered it got stuck in an unbooted state, presumably due to uncontrolled power downs. Followed its own long self-recovery procedure and eventually booted up normally and final became ping-able.
- Matthias Wittgen offered a recipe to open a ssh tunnel from a counting room node to the CMOS cam via esadutdaq1
- Window 1 on ar-esaux2
ar-esaux2 > ssh -L8080:192.168.2.1:80 tbslac@esadutdaq1 - Window 2 on ar-esaux2 open a web browser (firefox didn’t work for me, but konqueror did)
ar-esaux2 > conqueror
Navigate to http://localhost:8080
- Window 1 on ar-esaux2
- Mike and Juan further debugged the XY stage scaling parameters to correct them to the right values. Movement steep on some on them also slowed down (especially the rotation). Mike showed how the advanced option panel can help control the movement rata and soft limits. However the problem of current position display lagging until next move is still there. Needs to use the advanced option panel to to manual refresh to check current position.
- Upon retry of EUDAQ integration, RCE producer always aborts at start of run. Running calibGui reveals connection error and a suspicious of DUT private network IP address for the Sun server. Debugging with Martin Kocian uncovered that the environment variable ORBHOST for the host node esadutdaq1 used by RCE DAQ also needs update to follow the DUT private network change above. The default definition in ~/daq/rce/scripts/setup-gen3.sh is updated to point to 192.168.2.3. This brought whole EUDAQ to run with the SLAC_1dut_FE14B configuration (1 module both FEs).
- Ready for beam !
- Upon requesting to start beam MCC found out that the primary LCLS experiment at CXI was initially unwilling to share out the 5 Hz beam, partly because their overall beam delivery for the last day was rather rough. 1Hz setup appeared to be not available. However, CXI eventually agreed to release the lowest possible rate at ~3.5Hz so we had the first run. Whenever we are not running we should inform MCC to take away the beam to give back the 5%.
- Run 269 is the first run with the LBNL CMOS taped at the back of the regular double-chip module 94-04-03, started out at perpendicular to beam. CMOS is untriggered. MCC didn't have dump signal to guide setup quality, but we could tell it was a rather wide spread spot and about 10 particles per MIMOSA per shot. For the last 1/4 of the run, the module is rotated by~45 degrees but not sure if still aligned within beam.
- The CMOS camera timing window can only open up to 1ms so that it was only 1-2% duty cycle. Got an 5V->3V BNC+resistor voltage divider from Mark Freytag to try to run triggered mode. Also got a 1M Ohm resistor to series a bias voltage LV drive. Installed both on the CMOS camera.
- Upon requesting to restart beam, MCC complained that some vacuum valve for ESA section didn't look right and wondered how we could operate like that. Indeed the beam spot looked very wide and nearly uniform over the whole MIMOSA area.However we were getting ~10 particles per beam crossing on each MIMOSA. This is actually OK for us so asked MCC not to bother tuning it.
- NI producer repeatedly got stuck and no events were built while beam triggers were piping through at 5Hz. Eventually went back to start from the very beginning of NI setup to get everything going again.
- Run 277 with DUT at ~45 degrees and CMOS camera in triggered mode. Beam appeared to be hitting left X edge of the FE-I4 module. Moved the module to -X in 5mm steps several times during the run to confirm hits gradually moving to the center of DUT. Still not seeing hits on CMOS camera. Not clear if the TLU TRIG output was really getting into the camera trigger line.
- Saved monitoring histograms to ~tfuser/eudaq/bin and archived at ~tfuser/Desktop/2016July_onlinemon/.
- Decided to retrench on the CMOS camera for now. Dismounted and packed up for survey exit ESA. Several things to prepare for retry next week:
- Activating another beam trigger line to allow independent trigger time delays while keeping pairing FE_I4 and Caladium data in time, or still using the same primary trigger line to make a duplicated copy at DUT rack and find a way to do 25ns step delays one of the derived triggers. The primary trigger must be before the actual beam crossing.
- Verify triggering pulse electrical spec at LBNL bench tests
- Pulser and scope is ESA to examine trigger signals
- Keithley to measure microA level current on bias supply ?
Jul/13
Operations team: Ben Nachman, Su Dong
- Lab cold tests obtained good tuning for both LUB1 and LUB2, even 1500e for LUB2, at HV=600V.
- Presented plan for 2nd period to MCC at 4:15pm meeting: ESTB_MCC_7_13_2016_SD.pdf
- MCC meeting had brief discussion of possible effect of ESA stealing 5Hz beam. Some effects of missing pulse causing irregular effects for pulse after that a Low E beam experiment, but high E beam experiments never cared. However, still needs to verify this for MFX/LM51 tomorrow, before 9am so that both dat and night shift beam to ESA would be possible hopefully.
- Lab testing pushed up HV. For LUB1, 1KV immediately trips the 1mA max current, while 900V still hanging there but current still slowly creeping up. For LUB2, 1KV started out at 700uA (-29C) but current slowly creeping up and after several hours it eventually tripped and temperature went up to -26C.
Jul/14
Operations team: Ben Nachman, Su Dong
- Moved lab setup of cold box with LUB2 to ESA.
- The dry CO2 chamber is reversed from May to be on the corridor side while electrical connections from rack side. Beam entering from the back of the FE-I4A card.
- LV VDD=1.5V. I=0.33A after config.
- One temperature probe (Ts) taped to the Cu cooling tape tail from the DUT, the other temperature probe (Tg) in cold gas.
- Leakage current high initially but temperature was just -10C. 2nd access raised HV to 800V leakage current 830uA at Ts= -23C.
- After ensuring only ch=0 for RCE activated in readout, calibration ran, but threshold distribution is broad. Returned and got a quite decent RMS now. Saved to LUB2/config_rad_np_0_335: 1500e threshold, 8000e=10 for TOT.
- Made EUDAQ config SLAC_1dut_rad_FEI4A.conf
- Alignment was still tricky. Fine-Y adjustments not holding up the position. Any adjustment would trigger a long sag. Mike/Keith both thought the motor holding current may be too low. Will be looked at tomorrow before 9am by TestFac.
- Because DUT X/Y transposed, we cannot see correlations any more between MIMOSA and DUT as correlation only plots X vs 'X'.
- Horizontally we would like to move Fine-X towards +X (rack wall) by ~1cm to align with EUDET but that reached limit and cold box cable exit is touching Caladium plane frame.
- Requested access ~4:45pm. Put a ~2cm block spacer in the cold box to move DUT towards -x to recenter better in X wrt Caladium and space out the cable exit from Caladium. Also jacked up the DUT box by hand to be close to center in Y. Topped off dry ice.
- MCC notified us that LCLS MFX requested change of beam energy up to 14 GeV (but secondary always 11 GeV) which will affect our rate for a while. After reconfigure the beam spot shape changed completely with more definite edge and more uniform. Previous beam spot had a sharp hot spot of on the top right corner and more diffused spread below that.
- 6:45pm first serious data run 294. HV=800V, leakage current 200uA. Ts=-34C, Tg=-29C. ~350 hits/MIMOSA, 150 hits/evt in APIX. DUT beam window: Local X=40-75 which is 35 pixel ~8.5mm; Local Y=30-330 which is 300 pixels ~15mm. MIMOSA beam window X=200-1000 also ~15mm; Y=20-460, also 8mm.
- Noticed some 'scars' on the DUT which are straps of area with clearly lower hit density than neighboring areas.
- Ended a good run 294 to request lower rate. MCC had no clear recipe to reduce rate other than collimating to smaller beam size which doesn't really help us as it is the hit density that matters. They are trying to reach Toni Smith for advise. Ryan tried to tune this from upstream adjustments and succeeded to bring the rate down to 30 hits/shot at DUT with relatively small change in beam spot shape. We needed to make a few mm adjustments to keep both MIMOSA and DUT beam window fully contained.
- 8:34pm 2nd run 299 with DUT hit rate ~30/frame. Temperature climbing back up Ts=-32C, Tg=-27C. Leakage current 250uA. MIMOSA beam window X=150-700 (10mm) and Y=full span 0-570 and perhaps a bit more (11mm). DUT window 'X'=30-74 (11mm), 'Y'=40-260 (11mm) a bit trapezoidal.
- 9:06pm started a new run 300 when last run reached 10K event limit. Exactly same condition. Ended 21:42.
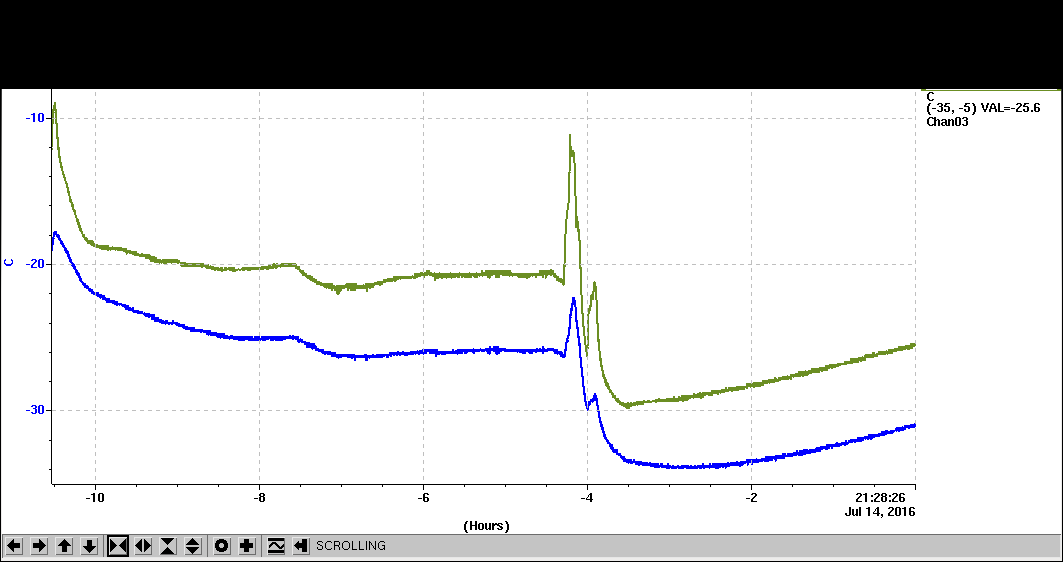
- Requested access to change DUT tilt. Had to pull out the block to tighten the rotation screw and retape the DUT Ts temperature probe. Cold box stage sagged again which needed manual repositioning. Topped off dry ice.
- Upon restarting to find the location of the DUT from remote motors, the whole DUT stage sagged to Ymin again. Only saw a lot of out of time noise hits at local X min and max edges (this was probably due to temperature not yet low enough).
- Turned off beam to do a low TOT tune of 1500e threshold and 400e per TOT bit. Calib tuning kept crashing. 600e still crashing, while 800e existing tuning still worked.
- Gaming with Y-fine stage to hold up the cold box at ~5mm below nominal (any further up push will cause full scale sag down). Cold box lid is opening a significant gap.
- Now a bit colder, returned to previous configuration and brought beam back. Noise lower. Moved DUT fine-X by -6mm, starting to see streaks. Data populating lower 'X' half of the DUT but did not dare to jack up the cold box.
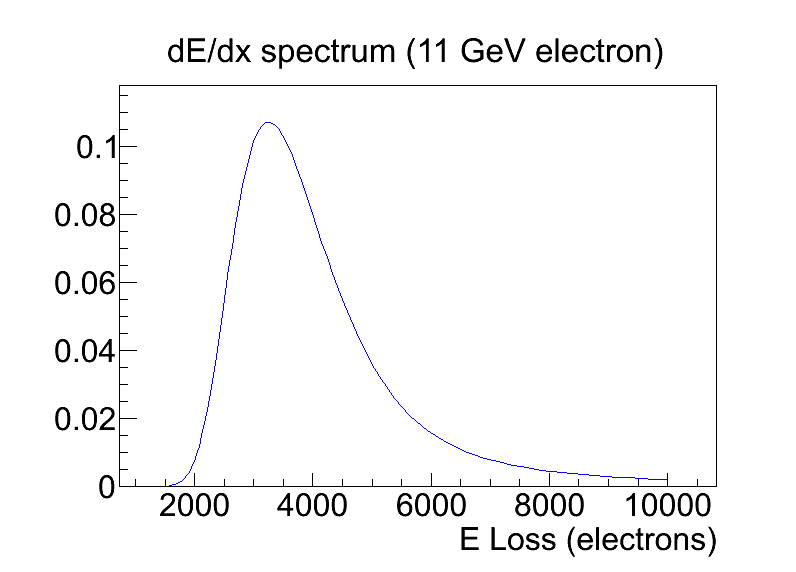
- 11:39pm started run 303 for the first streak data. They looked a bit shorter than expected typically. DUT data rate similar to MIMOSA at ~80 pixel/frame, but there are many streak clusters. Pixel TOT peak at ~5 (5*800e=4000e). This is a bit larger than expected from Bichsel calculation that predicted peak at ~3300e for 50micron silicon even without radiation damage ( foldspec_elec_11GeV_50mu.png ).
- 00:20am ended run. Let MCC took away beam. Remote power down of HV+LV.
Jul/15
Operations team: Ben Nachman, Rebecca Carney, Su Dong
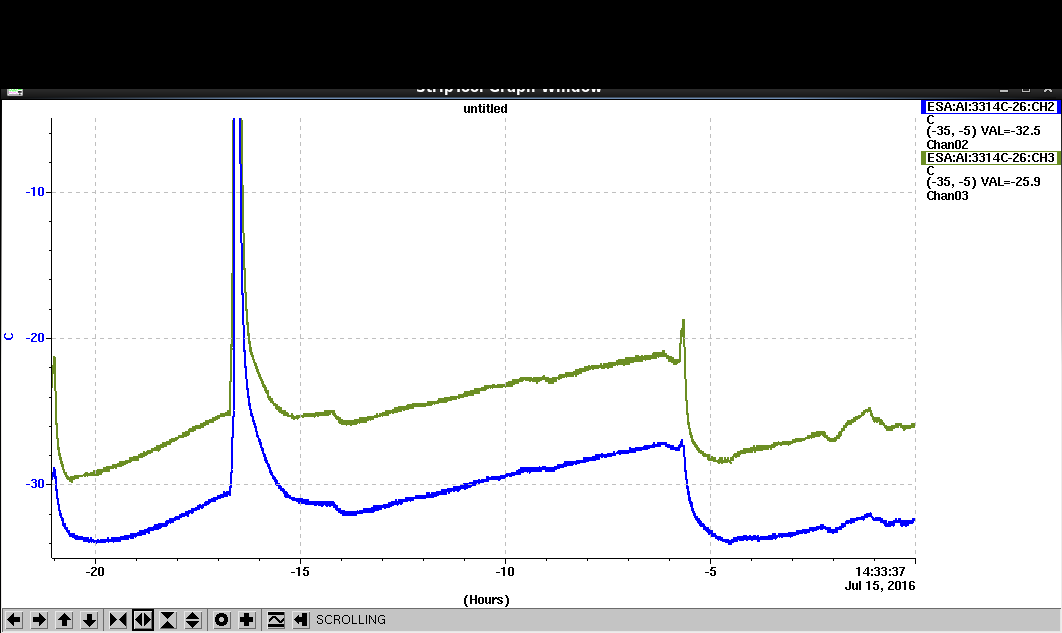
- Temperatures at 8:30 am: Ts = -27 and Tg = -22 (the clear drop just before the linear rise is where we turned off the DUT power).
- Primary beam energy up a bit from last night (12.7 GeV) - needed to work with MCC to adjust beam params (was blasting at ~500 particles to begin with). Amazingly, the DUT is still aligned (didn't move it up or down when filling the ice).
- 10:00 - Made entry to turn on LV. Checked HV whilst in cavern (first check since leaving last night), and had drifted to 870V. Was last set to 800V so we set it back to that value.
- Starting with Run 307 at 10:52 that has the same setup as Run 303 from last night (streak data). Originally started with Run 305 but EUDAQ seg-faulted so we had to restart it.
- Run 308 starting at 11:31 is the same as 303. Note that during this run, the rate drifted up again so there was a small intervention with the upstream collimators.
- The Caladium DUT Y-stage sagging issue was confirmed to be due to motor current responsible for holding position was not set so that weight can cause position drift. Some current setting enabled in the morning verified that one could hole Y-fine adjustment now but there is concern of motor overheating etc. so that Doug and Mike did further checking and tuning during noon access to settle it.
- ~12:30 - Went in to increase the HV and caught Doug and Mike. We now have automatic monitoring of the HV current (KL 3404 ADC Chan01) and voltage (KL3132 ADC Chan 01, but raw->voltage conversion factor in EPICS look wrong: 1.01V display 0.75V ). We can't yet control the HV because the cable we have between the HV and steering LV has a male end when it actually needs to be female.
- ~14:00 - Currently the conversion factor seems to off by 0.746 consistently in the ( we measured the ADC output and the value at the src for 600V, 800V, 900V, 1kV). On the next entry we will try switching the current and the voltage monitoring ADC channels to confirm it is just the conversion factor. The HV current monitoring seems representative of that measured near the source.
- ~15:30 - 1kV run,, with the beam set roughly between 'columns 30-60' ended after taking ~10,000 events. Then in run 311-314 adjusted the box position, moving it down by 6mm to take 1kV data over 'columns 10-40'. Run 315: taking data at 1kV for 10k events.
- ~16:30 - Tried switching the ADC channels to determine the other conversion factor: ADC channel 3132-4 is actually displaying 0.75 of the real value. ADC channel 3404 is close to the correct value: displaying 0.9*real value.
- We reentered the chamber at ~16:00 and refilled the dry ice as it was getting low. Tried increasing the HV bias to 1.1kV as suspected that the lack of a cluster size = 15 peak was due to the sensor being underdepleted, but the current quickly ran away. After adding the new dry ice: current seems stable so started new run.
- Doug and Craig gave us some commands to set the voltage (once we have the correct connector between the voltage supplies ofc). We must telnet into the machine and run edm from the ESTB gui. A few instructions (so far), not that none are case sensitive:
- Login to tfuser@ar-esaux2:~
- To login to voltage remote control: telnet ts-esa-01 2005
- To check if login successful, query machine ID: *idn?
- To query current voltage setting: volt?
- To set voltage: volt $VALUE
- To exit telnet: 'ctrl-'] , as in the control button and the right square brace button
- Then you'll be in some login window, to fully exit type: q
- More later.
- Start run 310 with 1.0KV HV (leakage current 440uA) and DUT pixel hit rate ~60. Beam window on the right hand half ('X'=30-60).
- Requested access at 6:30 to install the second ice chamber. Now the temp is nearly -45 or so! Changed the HV to 1200 V.
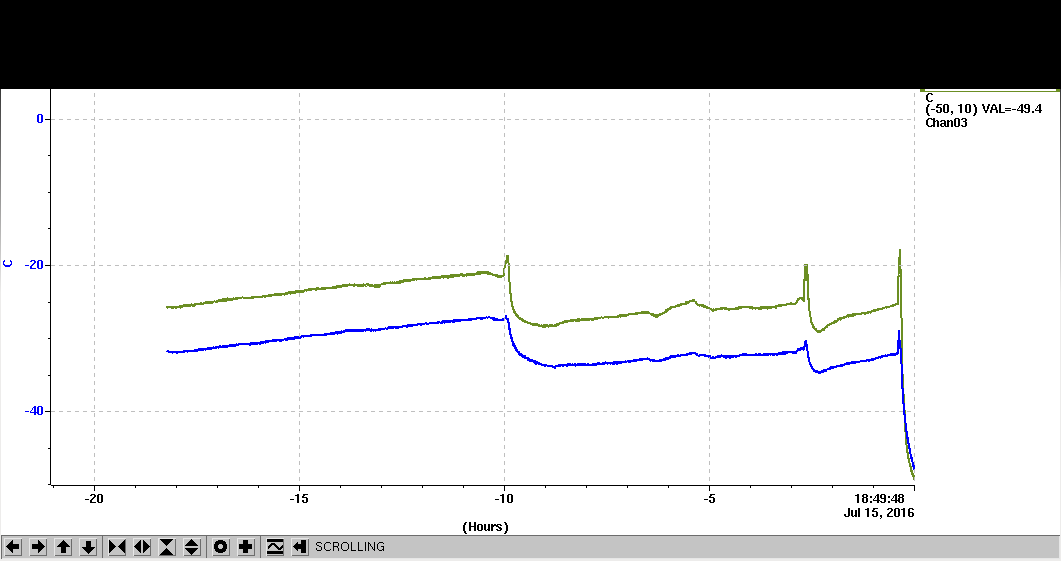
- Retroactive recap by SD: Y fine stage adjustment not functioning any more. Readout errors couldn't be cleared. Everything powered off to save dry ice overnight. Temperature reached ~ -60C at some point (but temperature time history lost). Unfortunately, not enough notes were left in this Event log for the various problems at the end of the shift so that the next shift ended up spending many hours rediscover the same problems.
- Retroactive recap by BN: We started a run once the beam came back, but only saw a very low hit rate in the DUT (telescope was fine as usual). From the web cams (and later confirmed by visual inspection at the end of the shift), we saw that the DUT stage had sagged. The DUT box is now much heavier with twice the dry ice and the low holding current (which Mike and Doug raised from 0 to 1 mA
 ) is no longer sufficient. We need to ask Doug and Mike to show us how to change this to compensate for changes to the mass of the DUT stage. We tried raising the telescope to find the beamspot in the DUT because we could no longer use the fine y stage (the telescope was returned to its original y position before we left), but the fine x stage was working and we spent some time scanning for the beam (with no success). At some point, we stopped seeing events built so we restarted EUDAQ. This did not help (no events built) and from the RCE we saw some strange errors that we thought suggested a lack of (good) communication with the HSIO so we restarted the RCE, then the HSIO + RCE, then power-cycled the HSIO and restarted the RCE. None of these helped; after starting the run, we always saw the same strange errors. Rebecca looked up the qualified operating temperature for FEI4A to be -40C so we suspected that probably we have run into temperature problems. After consulting with Su Dong, we decided to power everything off and surrender for the night. Before turning off the HV, we turned down the value so that when started up again, it didn't jump to 1.2kV. Just before we left, looking at the various graphs, the current was very stable at ~150 uA, the V was 1.2 kV and the temperature was still falling (though stabilizing a bit) near -60C.
) is no longer sufficient. We need to ask Doug and Mike to show us how to change this to compensate for changes to the mass of the DUT stage. We tried raising the telescope to find the beamspot in the DUT because we could no longer use the fine y stage (the telescope was returned to its original y position before we left), but the fine x stage was working and we spent some time scanning for the beam (with no success). At some point, we stopped seeing events built so we restarted EUDAQ. This did not help (no events built) and from the RCE we saw some strange errors that we thought suggested a lack of (good) communication with the HSIO so we restarted the RCE, then the HSIO + RCE, then power-cycled the HSIO and restarted the RCE. None of these helped; after starting the run, we always saw the same strange errors. Rebecca looked up the qualified operating temperature for FEI4A to be -40C so we suspected that probably we have run into temperature problems. After consulting with Su Dong, we decided to power everything off and surrender for the night. Before turning off the HV, we turned down the value so that when started up again, it didn't jump to 1.2kV. Just before we left, looking at the various graphs, the current was very stable at ~150 uA, the V was 1.2 kV and the temperature was still falling (though stabilizing a bit) near -60C.
Jul/16
Operations team: Veronica Wallangen, Su Dong
- Cold box temperature still at -45C after long overnight warm up.
- Started with swapping in LUB1, placed at the 73 degree tilt in the double dry N2 chamber mode. However, the facing to beam is opposite of LUB1 to get easier looping of cables. In the tilted position, LUB2 had cable connectors upstream and beam entering via backside of the test card. LUB1 is mounted with cable connectors at downstream and beam entering the test card from the front.
- Also noticed Caladium is placed rather high which appeared to be due to the stuck DUT stage at slightly low fine Y so that Caladium is used to lift the DUT up into the beamline. We dropped two piece of metal slabs of ~1cm thick to lift the DUT up within the box. This bear made it to a partial overlap of top of DUT and bottom of MIMOSA. Much of the day was spent on locating the DUT overlap with Caladium and beam. Initial manual alignment by eye should have been done more rigorously.
- Readout errors. Replaced data ethernet cable from Lupe's to the black ESA commercial cable. No difference. Touched the LV cable inside box to reduce sharp bend with better loop. This recovered readout (or the LV power up sequence made the difference? Martin's theory was that one should hold off plugging in the actual LV to frontend after the PSU setting settled).
- All calibrations for LUB1 and LUB2 were stored in the moduleconfigs/LUB2 config directory. There was no known 1500e tune for LUB1. After getting some suggestions from Ben on the phone we picked config_rad_np_0__254.cfg which was a LUB1 tune of 2000e tune for 8000e@10 TOT. Briefly trying the cfg for threshold calibration which showed quite narrow threshold distributions for the ESA LUB1 setup. Running other cfg based on LUB2 gave much broader threshold dispersions. created the EUDAQ configuration SLAC_1dut_rad_LUb1.conf with this setting as running config for today.
- During the test runs with LUB1 to search for DUT position, at some point we noticed the occasional in time DUT signals appeared at time sample=1 instead of the usual center of 8. We even changed the config turgidly for it to move the data to time sample=8, but later on the peak shifted to ~15 so we returned the setup to the original form and DUT data time sample is back to 8.
- 19:06 started run 333 with LUB1 @ 1.1KV HV (leakage current 170uA) and DUT pixel rate ~70, but MIMOSA is only capturing the top half of the beam spot to allow the beam just catching the bottom part of the DUT. DUT beam window 'X'=5-30; 'Y' almost full span. MIMOSA beam window X=100-700; Y=0-160 (clipped at Y=0).
- 19:44 another run 335 with the same conditions.
- Attempted another 1500e tune for LUB1 following Martin's suggestion to skip the Noise Scan at step 13 but the process stumbled at step 16 for Noise Scan again, exactly the same way. So have to continue with the 2000e config.
- Raise HV to 1.2KV and every still looked benign with leakage current ~180uA.
- Just as we started to config, some major glitch took place ~9:40pm and entire Caladium stage control/ADC/temperature etc in an error state that never self-recovered. All temperature, HV readings became unavailable and Caladium stage also became uncontrollable. Rebooted IOC but didn't make any difference.
- We did not realize the seriousness of the Caladium control loss and went ahead lifted out the DUT and turned it to 90 degrees to beam after quite a bit if trouble.
- Reconnecting DUT also had trouble with readout error again. Upon playing with the LV power on sequence, it was noticed that the BK precision LV PSU went into a spontaneous chaos mode with displays flickering and numbers fluctuating and even partial screen blackout. This may well be the source the various readout flakiness.
- After waiting for 1-2 hours, the HV current went down enough to allow HV setting to go up to ~700V but current ~500 uA still fluctuating a lot and couldn't settle. Don't know what temperature this was. Dry ice is rather low and doesn't look like temperature can help this much from here on.
- Too many things telling us it's time to quit: Flaky LV PSU and readout errors, unsettling HV, broken Caladium drive and display, and we are out of dry ice. Dismounted the cold box from Caladium and placed the LUB1 in the ESA freezer together with LUB2.
- Concluded the day with just two good tilted runs with LUB1 @ 1.1KV.
- The temperature time history below for July/16 showing initial blue=probe tied to DUT Cu tape, green-cold box gas. The step at t=-5 hours is the big glitch that took out the Caladium drive/display.
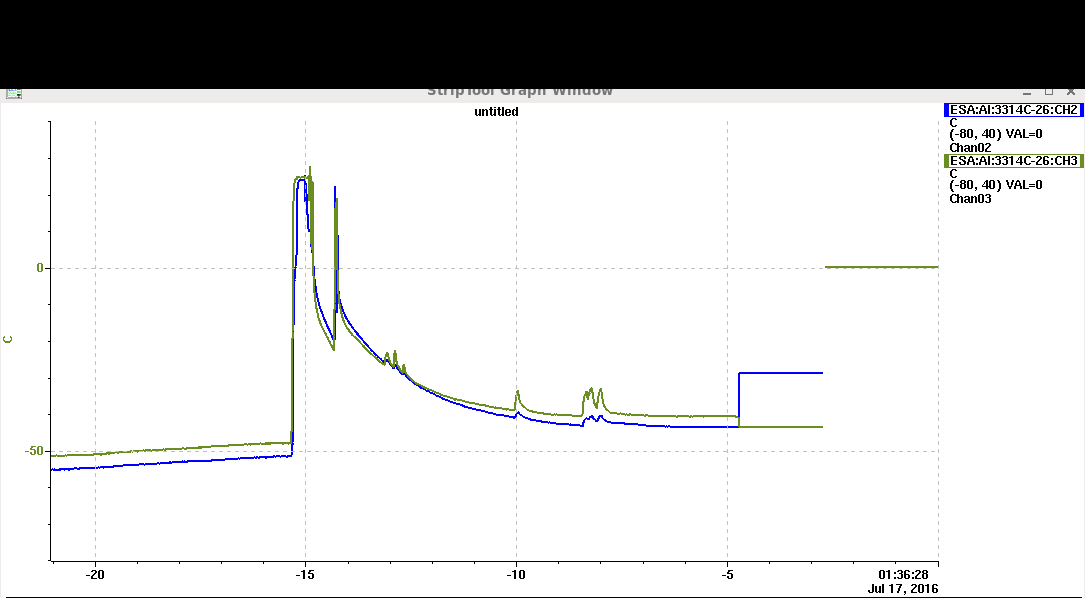
The newly installed Caladium ADC for the HV Vset and Imon: The green leakage current mon is roughly calibrated to the HV module's LEMO mon socket claimed of 1V=1mA. The blue Vset calibration was a bit strange which showed -0.75V for -1KV. Glitch at -5h made Caladium stage control into permanent error state, all values after that were invalid. 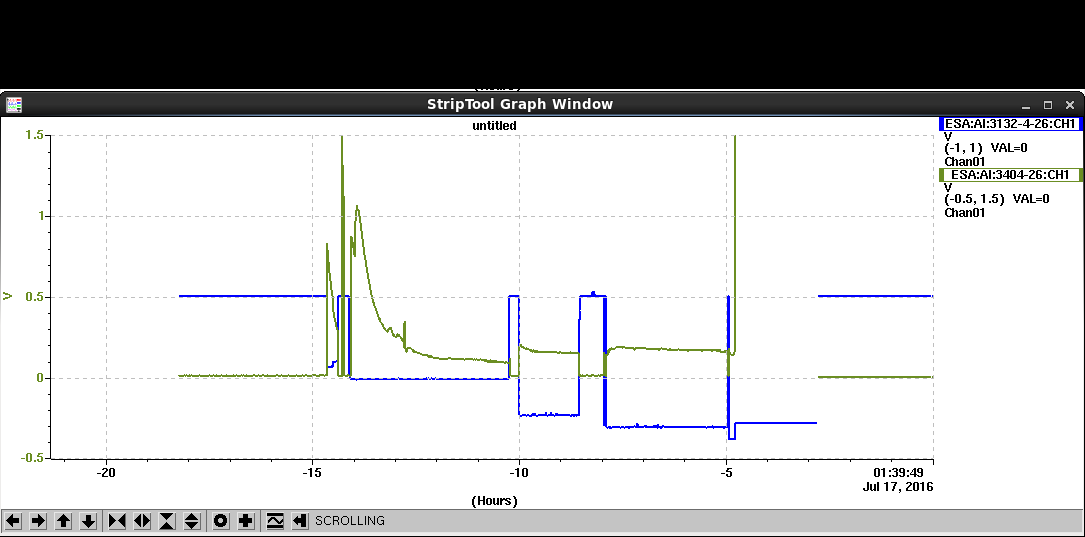
Jul/18
Operations team: Katie Dunne, Rebecca Carney, Su Dong
- The Caladium stage readout storm from Saturday was resolved by Doug McCormick. The solution was to just power cycle the stage control box. Sometime rebooting the IOC can help also but that was already tried by guessing on Saturday which didn't work. Other than physically unplug the stage power, one can also do this power cycle by remote control from AC Power->SCS3: B061 Tunnel->Bank 3 chan 23 "beckhoff 26".
- Doug turned the Caladium Y-fine stage drive current from 1A to the max of 3A and verified it can now drive ~50kg.
- We reinstalled the small rotation stage with the double chip FEI4B module 93-04-03 and verified the fine stage drives are now all functioning.
- Worked with Mike Dunning on the two HV monitoring ADC lines. The Vmon line is moved from KL3132 to KL 3404 together with the Imon so that KL3404 now has Chan01=HV-Imon; Chan02==HV-Vmon. Also adjusted the scaling factor for Vmon so that it has a slope=1.12 which gave identical reading between the Voltmeter and EPICS physical value for Vmon=-618mV (HV=-618V). At very low Vset the two differ somewhat probably due to some small offset but this is unimportant for higher HV range.
- Powered on the double-chip module with LV=1.5V; HV=-80V. Tried calibration but initially chan-0 not working but chan-1 worked. Swapped data cables between the two channels and then both channels worked (bad connection the first time?).
- Tried to bring up full EUDAQ readout MIMOSA DAQ panel got "ErrorConfig Socket" stuck red. Repeated normal startup sequence could not clear it. Resorted to go in the NI windows command line with a shutdown -r to reboot. Upon restart, the error cleared and everything back to running state. There should be a hardware reset for MIMOSA somewhere that shouldn't need to reboot the crate ?
- When Rebecca arrived we installed the sensor on the rotation stage spacer were installed to allow beam to travel between metal grating on the rotation stage and the sensor. There are issues with available holes in the setup so the sensor can be installed. We ended up aligning it in the short pixel direction.
- We ran calibGui with the LBNL_tungsten config
- Our first beam of the afternoon ~13:00 - 14:00 we had low particle rates (around 5) and asked MCC to increase it. They opened one of the collimators allowing more particles through and we ended up with around (30). It was easy to align the sensor to be in the center of the beam using the remote control of the stage
- 17:59: before beam, the VDDA: 1.5v 0.29A and VDDD: 1.19V, 0.035A (configured)
- 18:06: have beam with ~500 particles per shot according to mimosa. The alignment looked pretty center, but we quickly lost triggers from the DUT system. Probably the high particle rate caused the system to crash. We had multiple errors with RCE: pgp not responding, so RCE had to be restarted a couple of times
- We asked MCC to reduce the particle rate and we got to around 40 in the dut per shot, but this was still too high to be able to differentiate tracks. The high number of hits was also due to the particle shower from the tungsten. We further reduced it to ~4 particles per shot, according to the telescope, but got very little hits. Due to rotation (around 7.5 degrees) the surface area of the DUT is small. Finally we increased to around 40 particles per hit ahain at 18:51. Another pgp error for rce kept us from taking run data.
- method of dealing with rce failure:
reboot HSIO -r 0
rceOfflineProducer -r 0 -d 172.27.100.8 - 19:00 - Run 346 begins: the module is biased ~17V, the tuning file is config_standard_208.cfg which corresponds to 200 electrons at 12k electrons at ToT=10. We are getting very long clusters between 18-25 pixels, but they are broken so 4+ missing hits per pixel. Mimosas showing a particle rate of ~10 per shot. NB only fwd arm module 2 is reliable to measure rate online. All other telescopes in fwd arm have unmasked noisy pixels.
- 19:35 - Run 346 ended at with 10312 events
- We entered ESA soon after and reoriented the DUT in the long pixel direction. We evaluated the angle of rotation by these measurements:
24.9 from one side of the dut to a reference
23.1 from the other side and
12.3 width of DUT
this gave us an angle of ~6 degrees - 21:00 - STarted run 347. made a new conf file for EUDAQ but something is amiss with the config file from earlier in the day.
- 21:24 - Started run 350. Telescopes in the forward arm are reporting 4 particles per shot. Some observations: the noise in the module is now very high and most hits are out of time. Another issue is that before reloading the config for the run in the long direction I did two diagnostic scans to check the 3000e, 24k@4ToT tune was still valid. Although the spread of both tunes was identical and the noise waas still ~200e and the GDAC mean was 3000e the ToT mean had shifted to ToT=3. Since this config was tuned in SLAC's building 84 it seems like the rce in the building vs. the one in the ESA tunnel might be calibrated differently, by exactly 1. I took screenshots of both distributions with the same config file (TODO attach) so clearly the only difference is which HSIO/RCE is being used.
I'm not sure if this is related to the out-of-time hits we are getting or not. - 21:45 - We're getting a bunch of warnings from the RCE/HSIO: "Module data not starting with 0x2xxxxxxx. Usinfg old header info.
Inserting duplicate header for data-only frame on module RCE=0 Outlink=0". I'm assuming that this is because the data cable is right next to the beam and is not shielded. Not sure if this is a problem! Beam/monitors/data taking have all been good so don't want to restart until we have our first 10k triggers! - 21:59 - Stopped run after 10k events. Moving onto next run.
- 22:04 - Run 352 started. Still seeing odd pattern of single-pixel out-of-time hits at beginnign of run. Hopefully these drop out easily in the analysis. Clusters are otherwise unbroken.
- 22:20 - cool event just now. Single, unbro0ken cluster stretching from column 40 to 78 - almost 1cm long!!

- 22:40 - run stopped. 10678 events recorded.
- We've decided to stop for the night.