The GLAST "pipeline" is a software mechanism for organizing and executing massively parallel computing projects. Internally, the pipeline consists of a server application, web applications, Unix commands, and Oracle tables. Externally, the pipeline offers a general framework within which to organize and execute the desired data processing.
See also the Workbook version of the pipeline II users guide
Organizational Concepts
Main organizational concepts of the pipeline include:
- Task (and subtask)- A top level definition of work to be performed by the pipeline. A task may consist of one or more processes, and zero or more nested subtasks. Tasks are defined by an XML file.
- Stream (and substream)- A stream represents a single request to run the processes within a task. Streams always have an associated stream number which must be unique within each task. The stream number is always set at create stream time, either explicitly by the user or implied.
- Process - A single step within a task or subtask. Each process must be either a script or a job.
- Script- A process which results in a script being run inside the pipeline server. These small scripts are typically used to perform simple calculations, set variables, create subtasks, or make entries in the data catalog. Scripts can call functions provided by the pipeline, as well as additional functions for adding entries to the data catalog.
- Job - A process which results in a batch job being run.
- Variables- Pipeline variables can be defined in a pipeline XML file, either at the task level, or at the level of individual processes. They can also be defined at create stream time. Processes inherit variables from:
- The task which contains them.
- Any parent task of the task which contains them.
- Any variables defined at "create stream" time.
- Variables defined at create stream time.
Task Services
Task services offered by the pipeline include:
- DataCatalog
- Rules-based scheduler
- User variables for intraTask communication
- Express Python scripting (e.g., dynamic stream creation, and DB activities)
- Interface to batch system
- Signal handling
- Support for off-site processing
Operator Services
Operator services offered by the pipeline include:
- Web interface
- Task/Stream management
- Task/Stream Status
- Task/Stream plotted statistics
- Unix command-line interface
- Processing history database
Using the Pipeline
Basic steps for using the pipeline:
- Prepare, in advance, all data processing code in a form that can run unattended (non-interactively) and autonomously. This typically consists of one or more commands, with optional parameters or other environmental setup.
- Design a Task Configuration file, consisting of an .xml file which defines: processing steps, execution rules, and datasets to be cataloged.
- Submit the Task Configuration file to the pipeline server via the Web interface. Note: Admininistrative privileges are required.
- Create one or more top-level streams. This action instantiates new stream objects in the pipeline database and commences the execution of that stream. Once a stream has been created, its progress can be tracked using the web interface (Task Status and other pages). New streams may be created using either a web page or Unix commands.
- Rinse, and repeat, as necessary. - Streams requiring manual intervention may be restarted (rolled back) using the web interface.
Web Interface
From the Glast Ground Software Portal, click on Pipeline II. The Task Summary page will be displayed:
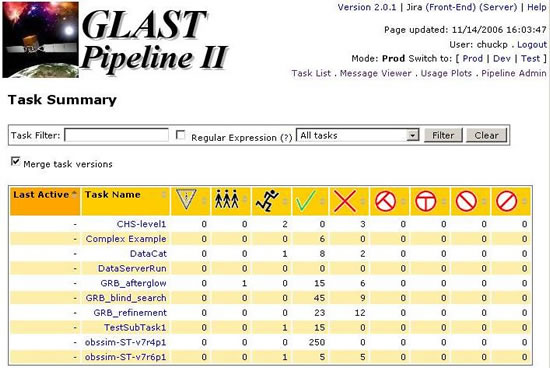
From the Task Summary, you can:
- Monitor a task by simply entering the task name as a filter.
- Enter a task filter for a group of tasks (e.g., GRB) and, from a pulldown menu, select the type of task to which it is applied (e.g., All Tasks, Tasks with Runs, Tasks without Runs, Tasks with Active Runs, and those Active in Last 30 Days).
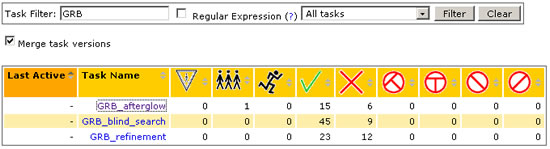
Note: When you click on the Clear button, the default list (All tasks) will be displayed.
- Drill down to successive layers of detail by clicking on the links within respective columns.
If a task has failed, you can drill down from the task name, checking the status column until you find the stream that failed; then check the log file for that stream (accessible from the links located in the right-most column).
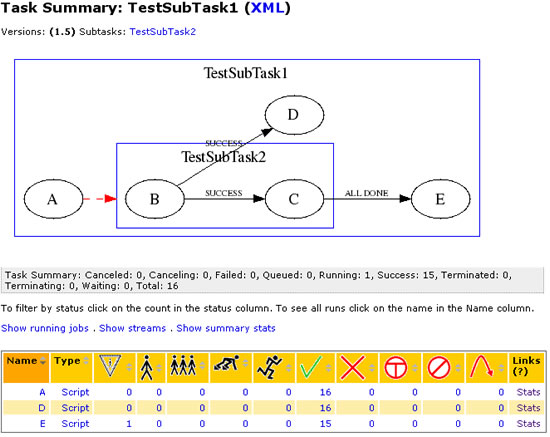
If a task is running, a Task Dependency Flow Chart (see below) will be displayed when you click on the task Name (e.g., TestSubTask1):
- Access the Message Viewer and Usage Plots and switch between pipeline II Modes (Production, Development and Test):

Note: If you have SLAC Unix or Windows userid/password, you can also Login to Pipeline Admin. | | Back to Top |
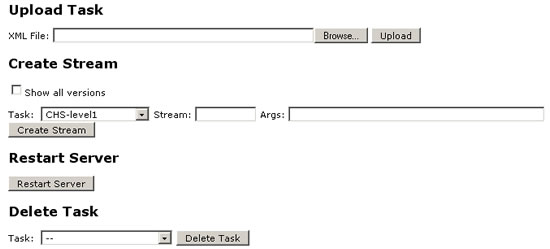
Pipeline Admin
From the Pipeline Admin GUI, you can upload a pipeline task, create a stream, restart the server, and delete a task:
Command line tools
As an alternative to using the web interface to control the pipeline it is also possible to use command line tools to achieve the same goals.
To get details on using the pipeline II command line tools enter
/afs/slac/g/glast/ground/bin/pipeline -h
Which currently gives:
Usage: pipeline [-options] <command>
parameters:
<command> Command to execute, one of:
info
load
restart
createStream
shutdown
ping
options:
--help Show this help page; or if <command> specified, show Command-Specific help
--mode <mode=PROD> Specify Data Source {PROD, DEV}
Example
Get Command-Specific help for command 'createStream':
/afs/slac/g/glast/ground/bin/pipeline -h createStream
will display:
Command-specific help for command createStream Usage: pipeline createStream [-options] <task> [file1 file2...] parameters: <task> Task name (and optional version) for which to create the new stream. [file1 file2...] Space seperated list of filenames to make available to the stream. options: --stream <Stream ID=-1> Integer stream identifier. Auto assigned if option not specified. --define <name=value> Define a variable. Syntax is "name=value"
Create a stream:
/afs/slac/g/glast/ground/bin/pipeline -m PROD createStream -S 2 -D "downlinkID=060630001,numChunks=10,productVer=0" -D "fastCopy=0" CHS-level1
This will create a stream with StreamID=2 for the task CHS-level1 and define the variables "downlinkID=060630001,numChunks=10,productVer=0" and "fastCopy=0" (you can use multiple variable definition options.) The stream will be created in the PROD server as specified by the -m (datasource mode) flag.
Pipeline Client API
The pipeline also has a Java API which is callable from other Java programs. This is used by the GLAST data server. This is packaged as part of the org-glast-pipeline-client package.
See the JavaDocs for the PipelineClient class for more details.
Developing pipeline tasks
XML Schema
- The full pipeline II schema is available at: http://glast-ground.slac.stanford.edu/Pipeline-II/schemas/2.0/pipeline.xsd
- You can view the XML for any task by clicking on the XML link on the task page, for example: http://glast-ground.slac.stanford.edu/Pipeline-II/xml.jsp?task=465210
- The maven generated pipeline II web site contains full documentation on the XML schema automatically generated from the source.
When editing an XML file for the pipeline, you are encouraged to use an editor which can validate XML files against XML schema, since this will save you a lot of time. EMACS users may be interested in this guide to using XML with EMACS.
Warning
Everything beyond this point is a big mess and probably wrong.
Batch Jobs
Batch jobs will always have the following environment variables set:
Variable |
Usage |
|---|---|
PIPELINE_PROCESSINSTANCE |
The internal database id of the process instance |
PIPELINE_STREAM |
The stream number |
PIPELINE_STREAMPATH |
The stream path. For a top level task this will be the same as the stream number, for sub-tasks this will be of the form i.j.k |
PIPELINE_TASK |
The task name |
PIPELINE_PROCESS |
The process name |
The "pipeline" Object
The pipeline object provides an entrypoint for communicating with the pipeline server in script processes. Below is a summary of the functionality currently available.
pipeline API
Please see the JavaDoc page for the pipeline java interface.
The "datacatalog" Object
The datacatalog object provides an entrypoint for communicating with the datacatalog service in script processes. Below is a summary of the functionality currently available.
datacatalog API
registerDataset(String dataType, String logicalPath, String filePath[, String attributes])
Registers a new Dataset entry with the Data Catalog.
dataType is a character string specifying the type of data contained in the file. Examples include MC, DIGI, RECON, MERIT. This is an enumerated field, and must be pre-registered in the database. A Pipeline-II developer can add additional values upon request.
Note: Maximum length is 20 characters.
logicalPath is a character string representing the location of the dataset in the virtual directory structure of the Data Catalog. This parameter contains three fields: the "folder", (optional) "group", and the dataset "name". The encoding is "/path/to/folder/group:name" -- if the optional group specification is ommited, the encoding is "/path/to/folder/name".
Example: /ServiceChallenge/Background/1Week/MC:000001 represents a dataset named "000001" stored in a group named "MC" within the folder "/ServiceChallenge/Background/1Week/".
Example: /ServiceChallenge/Background/1Week/000001 represents a dataset named "000001" stored directly within the folder "/ServiceChallenge/Background/1Week/".
Note: Maximum length is 50 characters for each subdirectory name and 50 characters for group name and 50 characters for dataset name.
filePath is a character string representing the physical location of the file. This parameter contains two fields: the "file path on disk" and the (optional) "site" of the disk cluster. The encoding is "/path/to/file@SITE". The default site is "SLAC".
Example: /nfs/farm/g/glast/u34/ServiceChallenge/Background/1Week/Simulation/1Week/AllGamma/000001.MC@SLAC
Note: Maximum file-path length is 256 characters, maximum site length is 20 characters.
attributes [optional] is a colon-delimited character string specifying additional attributes with which to tag the file. The encoding is "a=1:b=apple:c=23.6". All attribute values are stored in the database as ascii text. No expression evaluation is performed.
Example: mcTreeVer=v7r3p2:meanEnergy=850MeV
Note: Maximum length is 20 characters for attribute name and 256 characters for attribute value.
By default, attribute values are stored in the database as Strings. You can force storage of the value as a Number or Timestamp data-type by using the following naming convention (the "name" part of the "name=value" attribute definition string):
Number: "^n[A-Z].*"
ex: nRun, nEvents
Timestamp: "^t[A-Z].*"
ex: tStart, tStop
String: Everything else