ATLAS twiki page for T539: https://twiki.cern.ch/twiki/bin/viewauth/Atlas/RadDamageTBSpring2016
Event log
Jul/06
- Caladium back to beam line, but chillier not yet on and g-2 platform post is blocking beam line to the dump.
- Cleaned up the remnants of g-2 from DUT rack. Mounted DUT rotation stage. Reconfigured the web cams and updated the confluence portal list.
- Queuing one BK Precision 9130 supply for survey to exit ESA for let Mike Dunning working on its RS232 interface for EPICS.
...
Operations team: Maurice Garcia-Sciveres, Katie DunnDunne, Su Dong
Maurice's CMOS sensor shipped to SLAC from Sensor Creator's Inc directly. A 'camera' like standalone readout unit connecting the sensor via a thin flex. Beamline support scheme worked out with Matt McCulloch with CMOS sensor taped behind the 94-04-03 double chip FE-I4 module. Vertical readout chain to allow easy rotation. Ethernet port address 192.168.2.1. |  |
|---|
...
- Moved lab setup of cold box with LUB2 to ESA.
- The dry CO2 chamber is reversed from May to be on the corridor side while electrical connections from rack side. Beam entering from the back of the FE-I4A card.
- LV VDD=1.5V. I=0.33A after config.
- One temperature probe (Ts) taped to the Cu cooling tape tail from the DUT, the other temperature probe (Tg) in cold gas.
- Leakage current high initially but temperature was just -10C. 2nd access raised HV to 800V leakage current 830uA at Ts= -23C.
- After ensuring only ch=0 for RCE activated in readout, calibration ran, but threshold distribution is broad. Returned and got a quite decent RMS now. Saved to LUB2/config_rad_np_0_335: 1500e threshold, 8000e=10 for TOT.
- Made EUDAQ config SLAC_1dut_rad_FEI4A.conf
- Alignment was still tricky. Fine-Y adjustments not holding up the position. Any adjustment would trigger a long sag. Mike/Keith both thought the motor holding current may be too low. Will be looked at tomorrow before 9am by TestFac.
- Because DUT X/Y transposed, we cannot see correlations any more between MIMOSA and DUT as correlation only plots X vs 'X'.
- Horizontally we would like to move Fine-X towards +X (rack wall) by ~1cm to align with EUDET but that reached limit and cold box cable exit is touching Caladium plane frame.
- Requested access ~4:45pm. Put a ~2cm block spacer in the cold box to move DUT towards -x to recenter better in X wrt Caladium and space out the cable exit from Caladium. Also jacked up the DUT box by hand to be close to center in Y. Topped off dry ice.
- MCC notified us that LCLS MFX requested change of beam energy up to 14 GeV (but secondary always 11 GeV) which will affect our rate for a while. After reconfigure the beam spot shape changed completely with more definite edge and more uniform. Previous beam spot had a sharp hot spot of on the top right corner and more diffused spread below that.
- 6:45pm first serious data run 294. HV=800V, leakage current 200uA. Ts=-34C, Tg=-29C. ~350 hits/MIMOSA, 150 hits/evt in APIX. DUT beam window: Local X=40-75 which is 35 pixel ~8.5mm; Local Y=30-330 which is 300 pixels ~15mm. MIMOSA beam window X=200-1000 also ~15mm; Y=20-460, also 8mm.
- Noticed some 'scars' on the DUT which are straps of area with clearly lower hit density than neighboring areas.
- Ended a good run 294 to request lower rate. MCC had no clear recipe to reduce rate other than collimating to smaller beam size which doesn't really help us as it is the hit density that matters. They are trying to reach Toni Smith for advise. Ryan tried to tune this from upstream adjustments and succeeded to bring the rate down to 30 hits/shot at DUT with relatively small change in beam spot shape. We needed to make a few mm adjustments to keep both MIMOSA and DUT beam window fully contained.
- 8:34pm 2nd run 299 with DUT hit rate ~30/frame. Temperature climbing back up Ts=-32C, Tg=-27C. Leakage current 250uA. MIMOSA beam window X=150-700 (10mm) and Y=full span 0-570 and perhaps a bit more (11mm). DUT window 'X'=30-74 (11mm), 'Y'=40-260 (11mm) a bit trapezoidal.
- 9:06pm started a new run 300 when last run reached 10K event limit. Exactly same condition. Ended 21:42.
...
- Retroactive recap by SD: Y fine stage adjustment not functioning any more. Readout errors couldn't be cleared. Everything powered off to save dry ice overnight. Temperature reached ~ -60C at some point (but temperature time history lost). Unfortunately, not enough notes were left in this Event log for the various problems at the end of the shift so that the next shift ended up spending many hours rediscover the same problems.
Jul/16
Operations team: Veronica Wallengen, Su Dong
- Retroactive recap by BN: We started a run once the beam came back, but only saw a very low hit rate in the DUT (telescope was fine as usual). From the web cams (and later confirmed by visual inspection at the end of the shift), we saw that the DUT stage had sagged. The DUT box is now much heavier with twice the dry ice and the low holding current (which Mike and Doug raised from 0 to 1 mA
 ) is no longer sufficient. We need to ask Doug and Mike to show us how to change this to compensate for changes to the mass of the DUT stage. We tried raising the telescope to find the beamspot in the DUT because we could no longer use the fine y stage (the telescope was returned to its original y position before we left), but the fine x stage was working and we spent some time scanning for the beam (with no success). At some point, we stopped seeing events built so we restarted EUDAQ. This did not help (no events built) and from the RCE we saw some strange errors that we thought suggested a lack of (good) communication with the HSIO so we restarted the RCE, then the HSIO + RCE, then power-cycled the HSIO and restarted the RCE. None of these helped; after starting the run, we always saw the same strange errors. Rebecca looked up the qualified operating temperature for FEI4A to be -40C so we suspected that probably we have run into temperature problems. After consulting with Su Dong, we decided to power everything off and surrender for the night. Before turning off the HV, we turned down the value so that when started up again, it didn't jump to 1.2kV. Just before we left, looking at the various graphs, the current was very stable at ~150 uA, the V was 1.2 kV and the temperature was still falling (though stabilizing a bit) near -60C.
) is no longer sufficient. We need to ask Doug and Mike to show us how to change this to compensate for changes to the mass of the DUT stage. We tried raising the telescope to find the beamspot in the DUT because we could no longer use the fine y stage (the telescope was returned to its original y position before we left), but the fine x stage was working and we spent some time scanning for the beam (with no success). At some point, we stopped seeing events built so we restarted EUDAQ. This did not help (no events built) and from the RCE we saw some strange errors that we thought suggested a lack of (good) communication with the HSIO so we restarted the RCE, then the HSIO + RCE, then power-cycled the HSIO and restarted the RCE. None of these helped; after starting the run, we always saw the same strange errors. Rebecca looked up the qualified operating temperature for FEI4A to be -40C so we suspected that probably we have run into temperature problems. After consulting with Su Dong, we decided to power everything off and surrender for the night. Before turning off the HV, we turned down the value so that when started up again, it didn't jump to 1.2kV. Just before we left, looking at the various graphs, the current was very stable at ~150 uA, the V was 1.2 kV and the temperature was still falling (though stabilizing a bit) near -60C.
Jul/16
Operations team: Veronica Wallangen, Su Dong
- Cold box temperature still at -45C after long overnight warm up.
- Started with swapping in LUB1, placed at the 73 degree tilt in the double dry N2 chamber mode. However, the facing to beam is opposite of LUB1 to get easier looping of cables. In the tilted position, LUB2 had cable connectors upstream and beam entering via backside of the test card. LUB1 is mounted with cable connectors at downstream and beam entering the test card from the front.
- Also noticed Caladium is placed rather high which appeared to be due to the stuck DUT stage at slightly low fine Y so that Caladium is used to lift the DUT up into the beamline. We dropped two piece of metal slabs of ~1cm thick to lift the DUT up within the box. This bear made it to a partial overlap of top of DUT and bottom of MIMOSA. Much of the day was spent on locating the DUT overlap with Caladium and beam. Initial manual alignment by eye should have been done more rigorously.
- Readout errors. Replaced data ethernet cable from Lupe's to the black ESA commercial cable. No difference. Touched the LV cable inside box to reduce sharp bend with better loop. This recovered readout (or the LV power up sequence made the difference? Martin's theory was that one should hold off plugging in the actual LV to frontend after the PSU setting settled).
- All calibrations for LUB1 and LUB2 were stored in the moduleconfigs/LUB2 config directory. There was no known 1500e tune for LUB1. After getting some suggestions from Ben on the phone we picked config_rad_np_0__254.cfg which was a LUB1 tune of 2000e tune for 8000e@10 TOT. Briefly trying the cfg for threshold calibration which showed quite narrow threshold distributions for the ESA LUB1 setup. Running other cfg based on LUB2 gave much broader threshold dispersions. created the EUDAQ configuration SLAC_1dut_rad_LUb1.conf with this setting as running config for today.
- During the test runs with LUB1 to search for DUT position, at some point we noticed the occasional in time DUT signals appeared at time sample=1 instead of the usual center of 8. We even changed the config turgidly for it to move the data to time sample=8, but later on the peak shifted to ~15 so we returned the setup to the original form and DUT data time sample is back to 8.
- 19:06 started run 333 with LUB1 @ 1.1KV HV (leakage current 170uA) and DUT pixel rate ~70, but MIMOSA is only capturing the top half of the beam spot to allow the beam just catching the bottom part of the DUT. DUT beam window 'X'=5-30; 'Y' almost full span. MIMOSA beam window X=100-700; Y=0-160 (clipped at Y=0).
- 19:44 another run 335 with the same conditions.
- Attempted another 1500e tune for LUB1 following Martin's suggestion to skip the Noise Scan at step 13 but the process stumbled at step 16 for Noise Scan again, exactly the same way. So have to continue with the 2000e config.
- Raise HV to 1.2KV and every still looked benign with leakage current ~180uA.
- Just as we started to config, some major glitch took place ~9:40pm and entire Caladium stage control/ADC/temperature etc in an error state that never self-recovered. All temperature, HV readings became unavailable and Caladium stage also became uncontrollable. Rebooted IOC but didn't make any difference.
- We did not realize the seriousness of the Caladium control loss and went ahead lifted out the DUT and turned it to 90 degrees to beam after quite a bit if trouble.
- Reconnecting DUT also had trouble with readout error again. Upon playing with the LV power on sequence, it was noticed that the BK precision LV PSU went into a spontaneous chaos mode with displays flickering and numbers fluctuating and even partial screen blackout. This may well be the source the various readout flakiness.
- After waiting for 1-2 hours, the HV current went down enough to allow HV setting to go up to ~700V but current ~500 uA still fluctuating a lot and couldn't settle. Don't know what temperature this was. Dry ice is rather low and doesn't look like temperature can help this much from here on.
- Too many things telling us it's time to quit: Flaky LV PSU and readout errors, unsettling HV, broken Caladium drive and display, and we are out of dry ice. Dismounted the cold box from Caladium and placed the LUB1 in the ESA freezer together with LUB2.
- Concluded the day with just two good tilted runs with LUB1 @ 1.1KV.
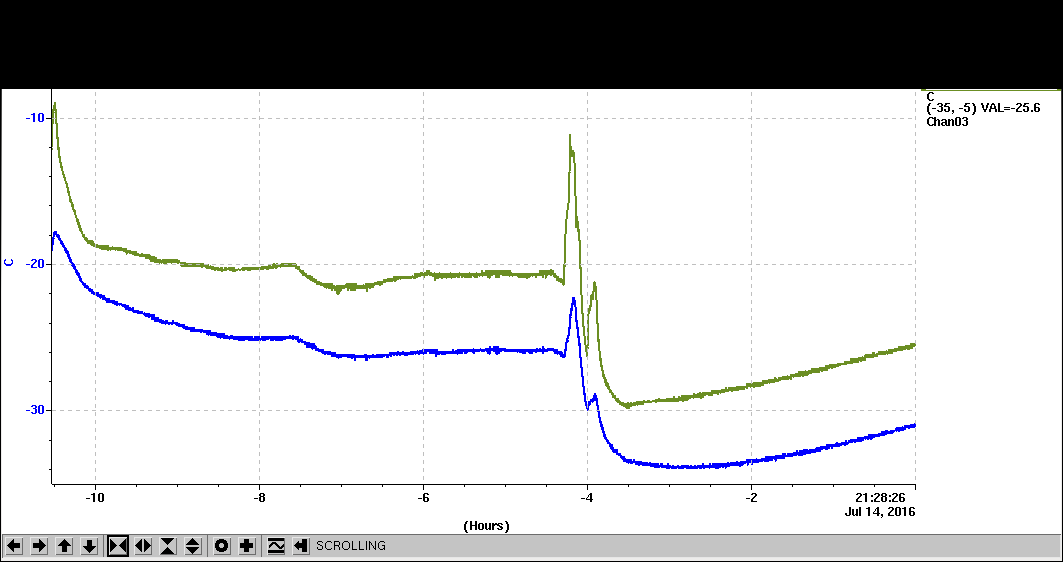
- The temperature time history below for July/16 showing initial blue=probe tied to DUT Cu tape, green-cold box gas. The step at t=-5 hours is the big glitch that took out the Caladium drive/display.
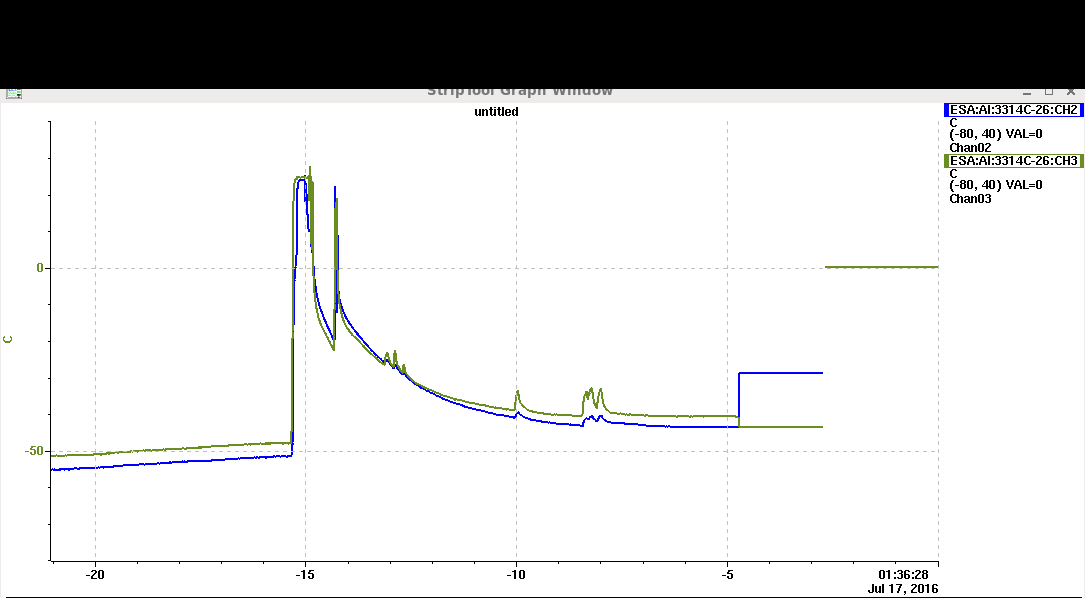
The newly installed Caladium ADC for the HV Vset and Imon: The green leakage current mon is roughly calibrated to the HV module's LEMO mon socket claimed of 1V=1mA. The blue Vset calibration was a bit strange which showed -0.75V for -1KV. Glitch at -5h made Caladium stage control into permanent error state, all values after that were invalid. 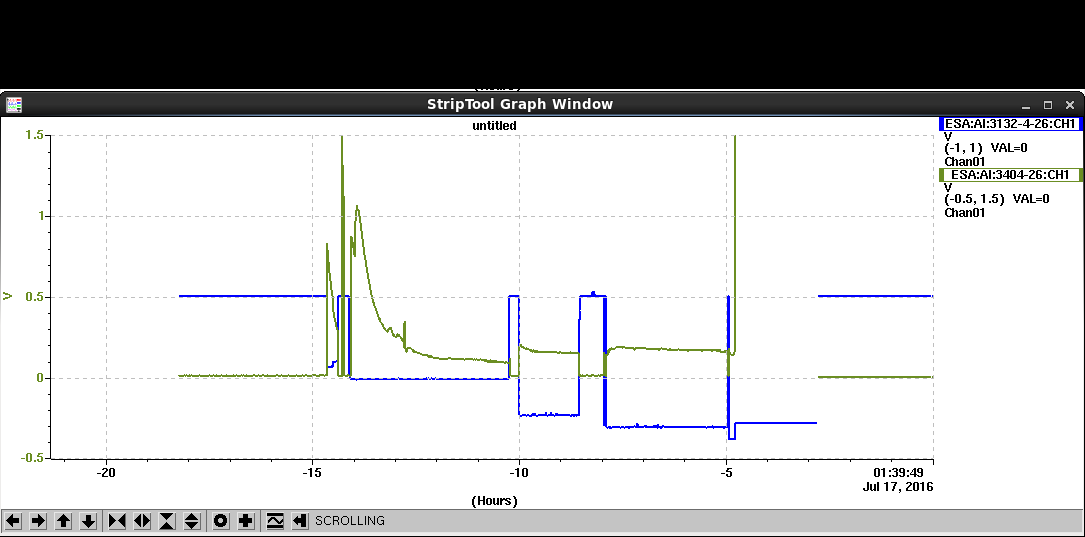
Jul/18
Operations team: Katie Dunne, Rebecca Carney, Su Dong
- The Caladium stage readout storm from Saturday was resolved by Doug McCormick. The solution was to just power cycle the stage control box. Sometime rebooting the IOC can help also but that was already tried by guessing on Saturday which didn't work. Other than physically unplug the stage power, one can also do this power cycle by remote control from AC Power->SCS3: B061 Tunnel->Bank 3 chan 23 "beckhoff 26".
- Doug turned the Caladium Y-fine stage drive current from 1A to the max of 3A and verified it can now drive ~50kg.
- We reinstalled the small rotation stage with the double chip FEI4B module 93-04-03 and verified the fine stage drives are now all functioning.
- Worked with Mike Dunning on the two HV monitoring ADC lines. The Vmon line is moved from KL3132 to KL 3404 together with the Imon so that KL3404 now has Chan01=HV-Imon; Chan02==HV-Vmon. Also adjusted the scaling factor for Vmon so that it has a slope=1.12 which gave identical reading between the Voltmeter and EPICS physical value for Vmon=-618mV (HV=-618V). At very low Vset the two differ somewhat probably due to some small offset but this is unimportant for higher HV range.
- Powered on the double-chip module with LV=1.5V; HV=-80V. Tried calibration but initially chan-0 not working but chan-1 worked. Swapped data cables between the two channels and then both channels worked (bad connection the first time?).
- Tried to bring up full EUDAQ readout MIMOSA DAQ panel got "ErrorConfig Socket" stuck red. Repeated normal startup sequence could not clear it. Resorted to go in the NI windows command line with a shutdown -r to reboot. Upon restart, the error cleared and everything back to running state. There should be a hardware reset for MIMOSA somewhere that shouldn't need to reboot the crate ?
- When Rebecca arrived we installed the sensor on the rotation stage spacer were installed to allow beam to travel between metal grating on the rotation stage and the sensor. There are issues with available holes in the setup so the sensor can be installed. We ended up aligning it in the short pixel direction.
- We ran calibGui with the LBNL_tungsten config
- Our first beam of the afternoon ~13:00 - 14:00 we had low particle rates (around 5) and asked MCC to increase it. They opened one of the collimators allowing more particles through and we ended up with around (30). It was easy to align the sensor to be in the center of the beam using the remote control of the stage
- 17:59: before beam, the VDDA: 1.5v 0.29A and VDDD: 1.19V, 0.035A (configured)
- 18:06: have beam with ~500 particles per shot according to mimosa. The alignment looked pretty center, but we quickly lost triggers from the DUT system. Probably the high particle rate caused the system to crash. We had multiple errors with RCE: pgp not responding, so RCE had to be restarted a couple of times
- We asked MCC to reduce the particle rate and we got to around 40 in the dut per shot, but this was still too high to be able to differentiate tracks. The high number of hits was also due to the particle shower from the tungsten. We further reduced it to ~4 particles per shot, according to the telescope, but got very little hits. Due to rotation (around 7.5 degrees) the surface area of the DUT is small. Finally we increased to around 40 particles per hit ahain at 18:51. Another pgp error for rce kept us from taking run data.
- method of dealing with rce failure:
reboot HSIO -r 0
rceOfflineProducer -r 0 -d 172.27.100.8 - 19:00 - Run 346 begins: the module is biased ~17V, the tuning file is config_standard_208.cfg which corresponds to 200 electrons at 12k electrons at ToT=10. We are getting very long clusters between 18-25 pixels, but they are broken so 4+ missing hits per pixel. Mimosas showing a particle rate of ~10 per shot. NB only fwd arm module 2 is reliable to measure rate online. All other telescopes in fwd arm have unmasked noisy pixels.
- 19:35 - Run 346 ended at with 10312 events
- We entered ESA soon after and reoriented the DUT in the long pixel direction. We evaluated the angle of rotation by these measurements:
24.9 from one side of the dut to a reference
23.1 from the other side and
12.3 width of DUT
this gave us an angle of ~6 degrees - 21:00 - STarted run 347. made a new conf file for EUDAQ but something is amiss with the config file from earlier in the day.
- 21:24 - Started run 350. Telescopes in the forward arm are reporting 4 particles per shot. Some observations: the noise in the module is now very high and most hits are out of time. Another issue is that before reloading the config for the run in the long direction I did two diagnostic scans to check the 3000e, 24k@4ToT tune was still valid. Although the spread of both tunes was identical and the noise waas still ~200e and the GDAC mean was 3000e the ToT mean had shifted to ToT=3. Since this config was tuned in SLAC's building 84 it seems like the rce in the building vs. the one in the ESA tunnel might be calibrated differently, by exactly 1. I took screenshots of both distributions with the same config file (TODO attach) so clearly the only difference is which HSIO/RCE is being used.
I'm not sure if this is related to the out-of-time hits we are getting or not. - 21:45 - We're getting a bunch of warnings from the RCE/HSIO: "Module data not starting with 0x2xxxxxxx. Usinfg old header info.
Inserting duplicate header for data-only frame on module RCE=0 Outlink=0". I'm assuming that this is because the data cable is right next to the beam and is not shielded. Not sure if this is a problem! Beam/monitors/data taking have all been good so don't want to restart until we have our first 10k triggers! - 21:59 - Stopped run after 10k events. Moving onto next run.
- 22:04 - Run 352 started. Still seeing odd pattern of single-pixel out-of-time hits at beginnign of run. Hopefully these drop out easily in the analysis. Clusters are otherwise unbroken.
- 22:20 - cool event just now. Single, unbro0ken cluster stretching from column 40 to 78 - almost 1cm long!!

- 22:40 - run stopped. 10678 events recorded.
- We've decided to stop for the night.
- Cold box temperature still at -45C after long overnight warm up.
- Started with swapping in LUB1, placed at the 73 degree tilt. Also noticed Caladium is placed rather high which appeared to be due to the stuck DUT stage at slightly low fine Y so that Caladium is used to lift the DUT up into the beamline. We dropped two piece of metal slabs of ~1cm thick to lift the DUT up within the box. This bear made it to a partial overlap of top of DUT and bottom of MIMOSA.
- Readout errors. Replaced data ethernet cable from Lupe's to the black ESA commercial cable. No difference. Touched the LV cable inside box to reduce sharp bend with better loop. This recovered readout (or the LV power up sequence made the difference? Martin's theory was that one should hold off plugging in the actual LV to frontend after the PSU setting settled).
- 19:06 started run 333 with LUB1 @ 1.1KV HV (leakage current 170uA) and DUT pixel rate ~70, but MIMOSA is only capturing the top half of the beam spot to allow the beam just catching the bottom part of the DUT. DUT beam window 'X'=5-30; 'Y' almost full span. MIMOSA beam window X=100-700; Y=0-160 (clipped at Y=0).
- 19:44 another run 335 with the same conditions.
- Attempted another 1500e tune for LUB1 following Martin's suggestion to skip the Noise Scan at step 13 but the process stumbled at step 16 for Noise Scan again, exactly the same way. So have to continue with the 2000e config.
- Raise HV to 1.2KV and every still looked benign with leakage current ~180uA.
- Just as we started to config, some major glitch took place ~9:40pm and entire Caladium stage control/ADC/temperature etc in an error state that never self-recovered. All temperature, HV readings became unavailable and Caladium stage also became uncontrollable.
- We did not realize the seriousness of the Caladium control loss and went ahead lifted out the DUT and turned it to 90 degrees to beam after quite a bit if trouble.
- Reconnecting DUT also had trouble with readout error again. Upon playing with the LV power on sequence, it was noticed that the BK precision LV PSU went into a spontaneous chaos mode with displays flickering and numbers fluctuating and even partial screen blackout. This may well be the source the various readout flakiness.
- After waiting for 1-2 hours, the HV current went down enough to allow HV setting to go up to ~700V but current ~500 uA still fluctuating a lot and couldn't settle. Don't know what temperature this was. Dry ice is rather low and doesn't look like temperature can help this much from here on.
- Too many things telling us it's time to quit: Flaky LV PSU and readout errors, unsettling HV, broken Caladium drive and display, and we are out of dry ice. Dismounted the cold box from Caladium and placed the LUB1 in the ESA freezer together with LUB2. Concluded the day with just two good tilted runs with LUB1 @ 1.1KV.
- The temperature time history below for July/16 showing initial blue=probe tied to DUT CU tape, green-cold box gas. The step at t=-5 hours is the big glitch that took out the Caladium drive/display.
- The newly installed Caladium ADC for the HV Vset and Imon: The green leakage current mon is roughly calibrated to the HV module's LEMO mon socket claimed of 1V=1mA. The blue Vset calibration was a bit strange which showed -0.75V for -1KV. Glitch at -5h made Caladium stage control into permanent error state, all values after that were invalid.