This is the start of the FY2006 DoE Terapaths DWMI Progress Report due September 10, 2006
...
Report
Terapaths: A QoS Collaborative Data Sharing Infrastructure for Petascale Computing Research: DWMI: Datagrid Wide Area Monitoring Infrastructure
Les Cottrell, Yee-Ting Li & Connie Logg, Stanford Linear Accelerator Laboratory (SLAC)
Summary:
The main goal of the DWMI project is to build, deploy and effectively learn how to use an initially relatively small but rich, robust, sustainable, manageable network monitoring infrastructure focused on the needs of critical HEP experiments such as Atlas, BaBar, CMS, CDF and D0.
...
.
...
We have room for a figure, it needs to be compelling.
Today's data intensive sciences, such as High Energy Physics (HEP), need to share large amounts of data at high speeds. This in turn requires high-performance, reliable end-to-end network paths between the major collaborating sites. In addition network administrators need alerts when there are of anomalous events , and grid middleware and end-users need long and short-term forecasting for application applications and network performance for planning, setting in order to plan, set expectations and to trouble-shootingshoot problems. To enable this requires a network monitoring infrastructure between the major sites that can help to notify and identify potential problems.
Active monitoring: We have developed an active network monitoring toolkit (IEPM-BW) . It that provides network measurements, data archingarchiving, analysis, reporting and visualization. This is now being used to make has been deployed and making regular measurements from the following major LHC related sites: CERN, BNL, Caltech, FNAL, SLAC, and Taiwan. We also have about 60 45 locations worldwide that are being monitored from these important sites. We use a selection of probes based on the quality and interest in the path being measured utilizing metrics such as network routes, round trip time, one-way delays, available bandwidth and achievable throughput. We are extending the presentation of IEPM-BW by working with the USATLAS and ULTRALIGHT groups to customize reports on their most relevant interests.
To aid the detection of incorrect host settings, we have also implemented features to query the configurations of the network monitoring hosts.
As part of this we have developed and put into production, management tools for automation and robustness, including: installation and update kits; measurement and reporting of unreachable participating hosts; documentation, including a Program Logic Manual; and a database of site, host, location, contact, OS, cpu, test parameters.working closely with the LHC-ATLAS physicists, the LHC Optical Private Network (LHCOPN) working group, BNL Terapaths, CERN and UltraLight to install the toolkit and ensure the data and presentations meet their needs.
With regards to cross-domain end-to-end MPLS circuits, we are currently developing mechanisms to automatically schedule active measurements using IEPM-BW, Terapaths and OSCARS to compare the performance of complete end-to-end QoS paths against normal production services.
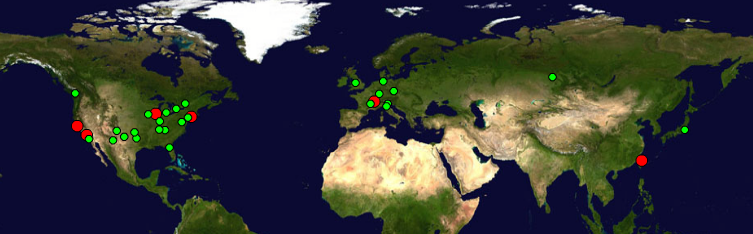
Deployment of IEPM LHC monitoring, red dots show monitor sites, green show monitored sites
Passive Monitoring: We have studied and reported on limitations using current active end-to-end network measurement techniques in future high-speed networks. As a result of this we are exploring the effectiveness of using passive (e.g. Netflow) tools to augment or even replace some of the against active measurements.
In conjunction with BNL we are building a netflow monitoring toolkit using open source software to bring together quality tools to gather, store, process, analyze and visualize the performance information. The intent is to make this generally available and deploy at LHC sites such as BNL, CERN, SLAC and Michiganaugment or possibly replace existing active monitoring mechanisms and to deploy it at LHC sites for both network performance monitoring and network security analysis.
In fact, much of our development is steared being steered by the requirements of the BNL site, specifically for the Terapaths project, where we have a an early development version of the entire suite running collecting real netflow data from production network systems.
Event Detection and Diagnosis: It is With the expansion of network infrastructure and the increased networked applications in use, it is becoming increasingly impossible for network managers to manually review thousands the large number of reports each morning to detect, and more importantly diagnose problems. Thus, we are developing tools to automate this activity . This includes forecasting and comparing the observed with the forecast by forecasting network performance to detect anomalous events , reporting the events, and automatically gathering information relevant to the event to assist in diagnosis. One version of the event detection is in production useand reporting them.
We are currently field testing the Plateau, Holt-Winters and KS algorithms on production networks via IEPM-BW. As part of this, in the last year, we have also detected, reported (together with in-depth case studies) and helped to manually diagnose major problems at sites such as BNL, Taiwan, SDSC, NRL, BINP, and CERN.
| Note |
|---|
Do we want to mention that the code is still in development and that we are basically field testing the alerts to known problems and using as a basis towards event diagnosis? |
High speed data transport: Our involvement in high speed TCP transport, including several publications and winning the Supercomputing Bandwidth challenges three times in succession and the Internet land-speed record twice has led Microsoft to request our help in evaluating their next generation TCP stack (CTCP). Given the extent of Windows deployment it is critical to ensure that CTCP performs well without a negative impact upon the iIternet community.
As part of this we have identified and aided the testing of numerous added features to aid the performance of the delay-based congestion control algorithm used in CTCP. Having finalized our initial report into the deployment impact of using CTCP in production environments on both long and short distance high speed Internet paths, we are know looking to publish a joint conference paper with Microsoft of our work We are also in the process of building a framework from which these network alerts can be used to automatically diagnose and identify the cause of network problems. Utilizing heuristics analysis and an innovative scoring system to pin-point the cause of an event, we are actively working closely with network providers to field test, review and corroborate our design to identify, locate and verify network problems and their symptoms.
Internet Measurement Confederation: An important aspect of being able to both understand and diagnose network performance problems is the unification of reporting formats and the understanding of tool performance on the Internet.
SLAC has We have recently started close collaboration with both Internet2 and ESnet to help develop and expand the functionalities of the international PerfSONAR collaboration.
Having had project. PerfSONAR has gained much momentum over the last few months due to its open-source, open-community, open-standards based ethos of network monitoring, . SLAC were are delighted to help contribute our network analysis skills expertise and experience to deploy and apply the PerfSONAR technology to production systems like that of PerfSONAR based technologies for projects such as the LHC project.
We aim to apply much of our existing analysis frameworks and tools to benefit the PerfSONAR project - including that of data visualization, event detection , event diagnosis.
===The rest of this is from Last Year's ===
For detecting drops in network performance (event detection) we have developed, published and integrated an automated step change detection algorithm. It has been successfully applied to several metrics with different measurement repetition frequencies, including RTT, available bandwidth and achievable throughput. It is now in regular use to generate email alerts for network administrators. With this, we are now reliably (few false positive or misses) detecting events within a few hours of their onset. This is in contrast to before, where in significant events went undetected for weeks.
Given the success and experience of these alerts, we are working on developing tools to gather more information to report to the network administrator. For the future we are evaluating other event detectors including the use of neural networks and Principal Component Analysis (PCA) to enable simultaneously evaluating multiple metrics and paths.
We have developed and are now integrating a long-term forecasting technique that takes into account seasonal (e.g. diurnal and weekly) variations. As part of the integration we will also make the forecasting tool more general purpose so it can be applied against data from other monitoring infrastructures.
In preparation for evaluating QoS at BNL we worked with ESnet to evaluate the impact and use of the ESnet OSCARS project. Our next steps will be to set up the measurements for the QoS project at BNL.
Impact to specific DoE Science applications
Improved network understanding and clearer expectations together with more quickly discovering and reporting network problems is critical to all network based applications. The DWMI project's deployment of the IEPM-BW infrastructure focuses on the real needs of the DoE supported LHC, BaBar, CDF and D0 HEP experiments and provides an evolving and practical basis for improved network monitoring and management.
Figure 1: Forecasting of available bandwidth and detection of a drop in performance event. The sudden drop in performance (below the expected range - black line) is automatically detected.
and network problem diagnosis.
High speed data transport: Our world-leadership role in evaluating TCP transport algorithms in production networks for large scale science projects such as the LHC, has led Microsoft to request our help in evaluating their next generation TCP stack (CTCP). Given the extent of Windows deployment it is critical to ensure that CTCP performs well without a negative impact upon the Internet community.
As part of this we have identified and aided the testing of numerous added features to aid the performance of the delay-based congestion control algorithm used in CTCP. We have finalized our initial report into the deployment impact of using CTCP in production environments on both long and short distance high speed Internet paths, and are now writing a joint conference paper with Microsoft.
For further information contact:
Dr. Les. Cottrell,
Stanford Linear Accelerator Centre
Scientific Computing and Computing Services
Phone: 650-926-2523
cottrell@slac.stanford.eduFor further information on this subject contact:
Dr. Thomas Ndousse,
Mathematical, Information, and Computational Sciences Division
Office of Advanced Scientific Computing Research
Phone: 301-903-9960
tndousse@er.doe.gov