Page History
| Table of Contents | ||
|---|---|---|
|
Access to data
| Warning |
|---|
Data processing has been moved to the S3DF this includes access to the FFB and processing from the FFB see: Running at S3DF The FFB batch system has been shutdown. |
The FFB system is designed to provide dedicated analysis capabilities during the experiment.
- The FFB currently offers the fastest file system (WekaIO on NVME disks via IB HDR100) of all LCLS storage systems however it size is only about 500 900 TB.
- The raw data will be kept on the FFB a week after an experiment ends however for data intensive experiments files might be purged even before an experiment ends.
Files deleted from the FFB will be available only on one of the offline systems (psana, SDF, S3DF or NERSC). - The raw data are copied to the offline storage system and to tape immediately, i.e. in quasi real time during the experiment, not after they have been deleted from FFB.
- The T
he users generated data created in the scratch/ folder are moved to the offline storage when the experiment is deleted from the FFB. When running on the FFB the xtc/ and scratch/ folder should be used for reading and writing ( below /cds/data/drpsrcf/...). The Lustre ana-filesystems should (must) not be used (only exception is calib/, see below).The LCLS Jupyterhub allows to start notebooks on the psffb nodes which will have access to the data and the FFB scratch folder of an experiment.
You can access the FFB system from pslogin, psdev or psnx with:
...
Besides the xtc/ folder for the raw data the scratch/ folder allows user to write their processing output. This folder will be moved to the offline filesystem after an experiment is done. The calib/ is a link to the offline calib folder. A ":live" is often added to the DataSource string in order to process xtc files while they are written (currently only works for LCLS1-style DAQ/analysis).
FFB SLURM partitions
You can submit your fast feedback analysis jobs to one of the queues shown in the following table. The goal is to assign dedicated resources to up to four experiments for each shift. Please contact your POC to get one of the high priority queues, 1, 2, 3 or 4, assigned to your experiment.
...
Queue
...
Comments
...
Throughput
[Gbit/s]
...
Nodes
...
Cores/
Node
...
RAM [GB/node]
...
Default
Time Limit
...
ffbl3q
...
Off-shift queue for experiment 3
...
ffbh1q
...
On-shift queue for experiment 1
...
ffbh2q
...
On-shift queue for experiment 2
...
ffbh3q
...
On-shift queue for experiment 3
...
ffbh4q
...
On-shift queue for experiment 4
...
...
Note that jobs submitted to ffbl<n>q will preempt jobs submitted to anaq and jobs submitted to ffbh<n>q will preempt jobs submitted to ffbl<n>q and anaq. Jobs that are preempted to make resources available to higher priority queues are paused and then are automatically resumed when resources become available.
The FFB system uses SLURM for submitting jobs - information on using SLURM can be found on the Submitting SLURM Batch Jobs page.The FFB slurm partitions have been removed
| Anchor | ||||
|---|---|---|---|---|
|
...
- xtc files are immediately copied to the offline filesystem
- the lifetime on the ffb is dictated by how much data is generated
- typically files stay on the ffb a week after an experiment ends
- however if space is need the oldest files will be purged from the FFB even before an experiment has finished
- after an experiment is done the ffb should not be used anymore except if discussed with the POC
scratch folder
From run 21 on no scratch folders are created on the FFB. The documentation below is only valid for old experiments.
Once an experiment has been complete the ffb scratch folder is moved to the experiments scratch folder on the offline filesystems. The following rules are applied:
...
- the umask is applied when creating files and directories which violates the ACL specs. As the default umask is 022 the group write permission will be removed. We recommend to set ones umask to:
| Code Block |
|---|
% umask 0002 |
Access to Lustre ana-filesystems
The batch nodes also have access to the ana Luster filesystems. For example the calib folder /cds/data/drpsrcf/<instrument>/<experiment>/calib is a link to the folder on the ana filesystem.
| Warning |
|---|
The bandwidth to the ana-filesystems is very limited and must be used for only light load e.g.: reading calibration constants. |
FFB setup
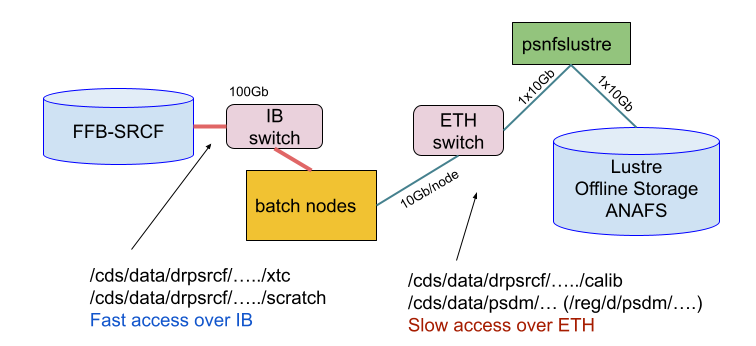
The The following figure shows the connectivity of the nodes:
- Each FFB file server (16 of them) has a 100Gb/s IB connection and 100GB/s ethernet
- Each batch node has a 100Gb/s IB connection
- Batch nodes have a 10Gb100Gb/s Ethernet connection
- All Ethernet Luster access goes eventually through psnfslustre02 and is limited 10Gb/s
- The figure also shows which network is used for the different file path

Overview
Content Tools