To-Do List
PENDING important improvement: Julian has timing link reset fixes (for all detectors that receive timing). We need to update all that firmware everywhere. Note: VHDL interface has changed (in lcls_timing_core) so it's more work (register map is the same). Could solve many problems below? List of firmware: tdet, wave8, camlink, epixhr, epixm, epixuhr, hsd, hrencoder, xpm+varieties, tpr (others?). The data systems group should deploy the tdet firmware everywhere in production as a first-pass test. If that is successful then we do everything else. (non-production firmware build from Julian can be found here: /cds/home/j/jumdz/mcs/DrpTDet-0x04000400-20240413131956-jumdz-dirty
- (important) eye-scans for all transceivers
- hsd eyescan status on May 15, 2024: data links working, but the timing link scan needs work?
- xpm eyescan is documented on debugging daq (in pyxpm folder)
- Julian can hopefully add the kcu eyescan to debugging daq
- Let's put all the eyescan software in psdaq/psdaq/eyescan
- wave8 may not work because we don't have the rogue package in lcls2
- (important) eye-scan for hsd jesd links?
- in progress
- work on high-speed-digitizer timing robustness using teststand
- occasional need to restart hsdioc process
- kcu1500 can lose link and hsd loses/regains power, and can only be recovered by power cycling cmp node
- check wave8 timing robustness
- (done) program hsd firmware over pcie?
- (important) manufacture new xpm boards (4 for txi)
- Minh is testing new cards on May 1, 2024: gave two cards to Julian on May 15, 2024. Julian is going to check.
- do we need another xpm/crate order for mfx? (separate from LCLS-II-HE?). go from mfx hutch back to 208 or the mezzanine?
- could use xpm7 in room 208. but would like a crate longterm
- on May 1, 2024 a crate has not been ordered yet (and none for HE either)
- (important) reproduce/fix timing nodes assigning wrong timestamp to configure transition by 1 or 2 buckets
- matt thinks this is on the receiver side: some fifos that carry daq data separate from timing data. matt thinks perhaps we have to connect the resets to those fifos.
- have seen this is hsd/wave8. see both being problematic after a power outage here: /cds/home/opr/tmoopr/2024/03/04_17:11:56_drp-srcf-cmp030:teb0.log (and Riccardo saw it in his tests, below)
- saw this on May 27 or 28 on drp-srcf-cmp025 running Julian's new 0x4000400 firmware.
- (important) (perhaps done by fixing reset logic?) reproduce/fix link-lock failure on timing system KCUs
- after Julian's fixes in late 2023 on April 7 we had a failure where cmp002 kcu wouldn't lock to its timing link. power cycling "fixed" the problem. However, cm002 kcu has had other issues (see below)
- (important) saw xpm5 link not recover on its own
- Saw this on April 10, 2024 (see below for details)
- (important) after a timing outage on May 22, 2024 xpm3 timing frames got largely "stuck" after a day-long ACR timing outage. Seen using the xpmpva "RxLinkDump" button with the unused lane in loopback mode. Details are here: https://confluence.slac.stanford.edu/display/PSDMInternal/Debugging+DAQ#DebuggingDAQ-DecodingXPMPackets
- this was "fixed" on xpm3 with TxLinkReset from xpm0 to xpm3. there is a RxReset on the UsTiming tab of xpm3 that might have also worked. "CLEAR" on groupca events-tab resets counters, but also some xpm logic, but this didn't fix the issue.
- make pyxpm processes robust to timing outages?
- (done) ensure that Matt's latest xpm firmware fixes the xpm link-glitch storms
- (perhaps done by fixing reset logic ?) reproduce/fix TxLinkReset workaround
- on May 1, 2024 it feels like we may have fixed this?
- (perhaps done by fixing reset logic?) reproduce/fix xpmmini-to-lcls2timing workaround
- on May 1, 2024 it feels like we may have fixed this?
- (done, fixed with equalizer 0x3 setting) check/fix loopback fiber problem in production xpms in room 208
- also saw two incidents in April 2024 where "cat /proc/datadev_0" showed all 1's (0xffffffff) everywhere as well as nonsensensical string values. Triggered by timing outages? One of the instances was on cmp002 and I think the other one was on another node that I don't recall.
- May 1, 2024: cpo recollection that we saw this twice on cmp002
- in all cases "fixed" by power cycling
- Matt says: means one can't read anything on the pcie bus. Not clear who the culprit is. clock is used from the pci bus for register reads.
- (important) TPR readout group intermittently wrong
- matt thinks this is a design flaw with a delay fifo in the timing receiver that's not present in all designs (present in TPR and ATCA on controls systems, but NOT xpm)
- (also after Julian's fixes in late 2023) this file shows a failure mode of a tdet kcu1500 on drp-srcf-cmp010 where its pulse-ids were off by one pulse-id ("bucket jumping" problem that Riccardo reproduced on the teststand): teb log file showing the cmp010 problem: /cds/home/opr/rixopr/scripts/logfiles/2024/04/08_11:58:28_drp-srcf-cmp013:teb0.log. Powercycling "fixed" the problem. Split event partial-output from that log (two Andor's on cmp010 timestamps were incorrect, since all other detectors showed 0x8ff3 at the end). A similar failure on drp-srcf-cmp025 can be seen here: /cds/home/opr/rixopr/scripts/logfiles/2024/04/13_12:43:08_drp-srcf-cmp013:teb0.log. There was a timing outage two days previously, I believe.
rix-teb[2111]: <W> Fixup Configure, 008a4a15bf8ff2, size 0, source 0 (andor_norm_0) rix-teb[2111]: <W> Fixup Configure, 008a4a15bf8ff2, size 0, source 1 (andor_dir_0) rix-teb[2111]: <W> Fixup Configure, 008a4a15bf8ff3, size 0, source 2 (manta_0) rix-teb[2111]: <W> Fixup Configure, 008a4a15bf8ff3, size 0, source 3 (mono_encoder_0)
- See this issue on drp-srcf-cmp002, also saw this on drp-srcf-cmp004 on May 7, 2024. May 22, 2024: Seems to be better after replacing kcu1500 on cmp002? Was happening about once per day. Haven't seen it in about a week now.
(ps-4.6.3) drp-srcf-cmp004:software$ cat /proc/datadev_0 -------------- Axi Version ---------------- Firmware Version : 0xffffffff ScratchPad : 0xffffffff Up Time Count : 4294967295 Device ID : 0xffffffff Git Hash : ffffffffffffffffffffffffffffffffffffffff DNA Value : 0xffffffffffffffffffffffffffffffff Build String : ����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������[�d� -------------- General HW ----------------- Int Req Count : 4294967295 Hw Dma Wr Index : 4294967295 Sw Dma Wr Index : 3136 Hw Dma Rd Index : 4294967295 Sw Dma Rd Index : 323 Missed Wr Requests : 4294967295 Missed IRQ Count : 27819533 Continue Count : 0 Address Count : 4096 Hw Write Buff Count : 4095 Hw Read Buff Count : 0 Cache Config : 0xffffffff Desc 128 En : 1 Enable Ver : 0xffffffff Driver Load Count : 255 IRQ Hold : 4294967295 BG Enable : 0x0 -------------- General -------------------- Dma Version : 0x6 Git Version : 5.17.3 -------------- Read Buffers --------------- Buffer Count : 1048572 Buffer Size : 8192 Buffer Mode : 2 Buffers In User : 0 Buffers In Hw : 4095 Buffers In Pre-Hw Q : 1044477 Buffers In Rx Queue : 0 Missing Buffers : 0 Min Buffer Use : 2 Max Buffer Use : 227890 Avg Buffer Use : 1116 Tot Buffer Use : 1170295872 -------------- Write Buffers --------------- Buffer Count : 16 Buffer Size : 8192 Buffer Mode : 2 Buffers In User : 0 Buffers In Hw : 0 Buffers In Pre-Hw Q : 16 Buffers In Sw Queue : 0 Missing Buffers : 0 Min Buffer Use : 5141 Max Buffer Use : 5142 Avg Buffer Use : 5141 Tot Buffer Use : 82259 (ps-4.6.3) drp-srcf-cmp004:software$ drp-srcf-cmp002:~$ cat /proc/datadev_0 -------------- Axi Version ---------------- Firmware Version : 0xffffffff ScratchPad : 0xffffffff Up Time Count : 4294967295 Device ID : 0xffffffff Git Hash : ffffffffffffffffffffffffffffffffffffffff DNA Value : 0xffffffffffffffffffffffffffffffff Build String : �������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������A
- XPM Link issues 2024/04/10-2024/04/11:
- Around 14:00-14:10 on 2024/04/10, RIX Grafana page shows there were fairly global XPM issues (measured by
XPM RxDspErrsrates) - XPM5 link (XPM3-5) goes down around 14:07 on 2024/04/10
- Other XPMs recover but 5 does not, and the link stays down.
xpmpvashows XPM5 looks mostly healthy except for theRxLinkUp- Required
TxLinkResetto restoreRxLinkUp(on 2024/04/11 ~09:15). 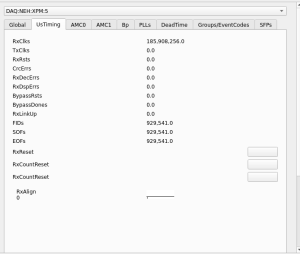
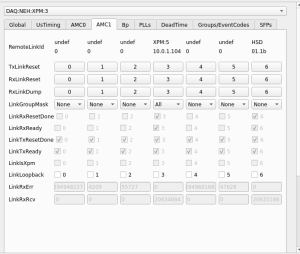
- Around 14:00-14:10 on 2024/04/10, RIX Grafana page shows there were fairly global XPM issues (measured by
- Summary Of Testing
These are the results of the tests that have been conducted in the FEE alcove to determine if the XPM glitch can be reproduced.
Every test is run from a starting behavior where the DAQ can allocate, configure, run, and disable.
Whenever the DAQ does not follow the starting behavior remedies are applied to recover it.




xpm10 and 11 connections

XPM schematics
Testing Details
In 2023/10/24 :
XPM firmware 3.5.4
Opal_config.py has xpm mini – timing2 hack
| action | result | remedy | result |
|---|---|---|---|
| Remove XPM10 fiber timing in the back while DAQ running | *** XpmDetector: timing link ID is ffffffff = 4294967295^M | TxlinkReset of cmp015 in XPM11 | DAQ recovers |
| Repeat XPM10 fiber timing removal removal | DAQ cannot disable | --- | DAQ recovers by itself at restart |
| Repeat XPM10 fiber timing removal removal | --- | --- | no issue |
| Repeat XPM10 fiber timing removal removal | DAQ cannot disable | --- | DAQ recovers by itself at restart |
| Remove XPM10 fiber timing in the back while DAQ stopped | --- | --- | DAQ starts with no issue |
| Repeat XPM10 fiber timing removal removal while DAQ stopped | --- | --- | DAQ starts with no issue |
| Remove transceiver from XPM10 in the back (DAQ stopped) | --- | --- | DAQ starts with no issue |
| Remove transceiver from XPM10 in the back (DAQ started) | --- | --- | DAQ starts with no issue |
timing 1 shutsdown by itself | TXlinkReset on XPM10 for XPM11 | DAQ recovers | |
| Remove fiber on XPM10 to XPM11 | --- | --- | DAQ starts with no issue |
| Remove transceiver on XPM10 to XPM11 | --- | --- | DAQ starts with no issue |
| Remove fiber on XPM11 AMC0 port 0 | --- | --- | DAQ starts with no issue |
| Remove transceiver on XPM11 AMC 0 port0 | --- | --- | DAQ starts with no issue |
opal disappears from the list f detectors | restart DAQ | DAQ starts with no issue | |
| power cycle xpm10 via switch only AMC0 | XPM 11 looses timing node | Restart pyxpm 10 and 11 restart pyxpm 11 | DAQ restarts but opal shutsdown |
opal still shutdown | devGui xpmmini timing v2 | no avail | |
Stop pyxpm 10 and 11 | DAQ starts with no issue |
In 2023/10/26:
| action | issue found | error stat | remedy |
|---|---|---|---|
stop pyxpm 10 and 11 | no issue has been detected | 0/10 | --- |
stop pyxpm 10 and 11 | at first xpmpva DAQ:NEH:XPM:11 does not come up Then Opal shutsdown | 3/20 | stop pyxpm 10 and 11 |
Observation Of Front-Panel XPM Link Glitch With Version 3.5.4
Perhaps fixed by Matt in later firmware version?

XPM11 glitches between 4pm and after 6pm and also around 10:10 am the next day
2023/10/27: updating firmware
xpm11 to xpm_noRTM-0x030601000-20231011111938-weaver-645bee8.mcs
xpm10 to xpm-0x030601000-20231011111954-weaver-645bee8.mcs
XPM firmware 3.6.0 (?3.6.1?)
Opal config does not have xpm mini -timing2 hack
cnf file uses -D fakecam for additional timing nodes
in 2023/10/30
| action | issue found | stat | remedy |
|---|---|---|---|
stop pyxpm 10 and 11 | 9/20 | --- | |
stop pyxpm 10 and 11 | Opal fails in configuration | 5/20 | reboot timing nodes |
stop pyxpm 10 and 11 | groupca and xpmpva are shutdown at startup | 4/20 | ctrl-x in the terminal successfully restart them |

example of the timing shift in the timing nodes (before -D fakecam).
in 2023/11/14
| action | issue found | stat | remedy |
|---|---|---|---|
| stop pyxpm 10 and 11 fru-deactivate and activate xpm 11 restart pyxpm 10 and 11 start DAQ | bucket issue | 1/10 | rebooting timing node cmp001 |
| rebooting timing node cmp001 | no issue | 0/5 | |
remove fiber from xpm10 to xpm11 fiber 10 times | no issue | 0/10 | |
Removing fiber from xpm10 to timing 1 fiber 10 times for 5 seconds (Amc1 port0) | no issue | 0/10 | |
Removing fiber from xpm11 to opal fiber 10 times for 5 seconds (Amc1 port1) | no issue | 0/10 |
in 2023/11/17
New opal_config.py: remove sleep while requesting mini/v2 introduce check for RxId instead with timeout of 10 repeats.
| action | issue found | stat | remedy |
|---|---|---|---|
| test power cycle she-fee-daq01/2 10 times | bucket issues | 3/10 | power cycling the xpm10 (txlinkreset didn't fix) |
| RTM disconnected in increades timing 5min 10 min 40 min 2hours | bucket issue (2 hours) | 1/4 | power cycle of xpm10 (txlinkreset didn't fix) |
in 2023/11/21 switching XPM firmware
from drp-neh-ctl002
~weaver/FirmwareLoader/rhel6/FirmwareLoader -a 10.0.5.104 /cds/home/w/weaver/mcs/xpm//xpm_noRTM-0x03050400-20230409095511-weaver-dirty.mcs
~weaver/FirmwareLoader/rhel6/FirmwareLoader -a 10.0.5.102 /cds/home/w/weaver/mcs/xpm//xpm-0x03050400-20230419122542-weaver-c6987c4.mcs
then fru-restart from psdev xpm 10 and xpm 11 in sequence, not together.
first light presents a problem with XPMPVA and GROUPCA
xpmpva XPM11 does not work
fru-restart bring it back alive
OPAL does not respond to roll call,
TXLINKRESET XPM11 in XPM10 brings OPAL back to live
| action | issue found | stat | remedy |
|---|---|---|---|
| remove fiber in RTM and restart DAQ | TXLINKRESET timing1 (on rollcall) TXLINKRESET timing1,2,3 (on alloc) | 2/10 | TxLinkReset solved rollcall TxLinkReset and RxLinkReset on xpm10,11 timing1,2,3,4 and opal |
| just restart the DAQ | Opal RxId issue RxLinkReset on timing4 (on rollcall) rxid issue on connect opal | 3/10 | TxLinkReset |
observing the logs there are several instances of :
21_10:02:16_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3245855222 3245855222 resetting. Iteration: 1
21_10:02:16_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3249109743 3249109743 resetting. Iteration: 2
21_10:11:36_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3561772053 3561772053 resetting. Iteration: 1
21_10:11:36_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3565026528 3565026528 resetting. Iteration: 2
21_10:11:36_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3568281227 3568281227 resetting. Iteration: 3
21_10:11:36_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3571538383 3571538383 resetting. Iteration: 4
21_10:36:38_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 0 0 resetting. Iteration: 1
21_10:36:38_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 3255210 3255210 resetting. Iteration: 2
21_11:34:43_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 94190235 94190235 resetting. Iteration: 1
21_11:34:43_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 97444648 97444648 resetting. Iteration: 2
21_11:34:43_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 100699006 100699006 resetting. Iteration: 3
21_11:34:43_drp-neh-cmp005:fee_fzpopal_0.log:*** Timing link stuck: 103957466 103957466 resetting. Iteration: 4
switching XPM firmware back to 3.6.1
~weaver/FirmwareLoader/rhel6/FirmwareLoader -a 10.0.5.102 /cds/home/w/weaver/mcs/xpm/xpm-0x030601000-20231011111954-weaver-645bee8.mcs
~weaver/FirmwareLoader/rhel6/FirmwareLoader -a 10.0.5.104 /cds/home/w/weaver/mcs/xpm/xpm_noRTM-0x030601000-20231011111938-weaver-645bee8.mcs
| action | issue found | stat | remedy |
|---|---|---|---|
| startup DAQ | none | 0/10 |
no instances of "*** Timing link stuck" in the logs
Power-on the tixel computer (the equivalent of cmp005) with the fiber unplugged, then we plugged in the fiber and it didn’t lock until we did xpmmini→lcls2. It appears that yanking the timing fiber can cause disturbances in the system, but they are not repeatable 100% of the time. XPMs Power spikes can set the DAQ in a behavior similar to the XPM glitch, but only if pyxpms are running. To be repeated.
Upgrading XPM firmware seems to have mitigated all the issues (to 3.6.0 from 3.5.4). The bucket issue becomes more prominent, probably because other issues are not happening. This issue appears when power cycling the xpm11. Also, xpmmini issue could appear when connecting already powered up nodes.
in 2023/11/27
testing double offence.
rebooting a node with cameralink without the fiber connected and connect the fiber after
| action | issue found | stat | remedy |
|---|---|---|---|
| rebooting cmp005 with timing fiber disconnected from xpm, then connect fiber when cmp is back on line | none | 0/5 | xpmpva does not see the opal until the daq is booted up. No ISSUES. |
Brainstorming Session
Nov. 16, 23 with mona, dan, weaver, caf, claus, melchior, cpo
proposal:
- move ric/mona/christos to xpm10 (for the future)
- give riccardo the whole system for the day and he messes with xpm10
- add startupMode=1 kwarg to opal
new xpm firmware (leaving xpm10 alone, no xpmmini->lcls2 hack):
riccardo can't reproduce the errors, except for bucket skipping
(txlinkreset fixed it for matt, but not riccardo and ric)
old xpm firmware (also messing with xpm10 with xpmmini->lcls2): riccardo could reproduce
xpm link glitch and txlinkreset (once) and (likely) xpmmini issue
theories:
- maybe ConfigLclsTimingV2 isn't reliable (should perhaps poll
on something like rxid!=0xffffffff)
- either new xpm firmware makes things better
- or we need to mess with xpm10 to reproduce problems
- or we're unlucky and can't reproduce (or we're not doing the right
things to reproduce)
- might need a minimum length of time to tickle the issues (matt says
try 30 minutes to 1 hour)
matt has an idea for bucket-jumps. could direct julian.
Results from Julian
- has kcu1500 xpm (not xpmmini) transmitting to txi epixHR
- with Dawood observed RxLinkUp never came up until they added debugging stuff
- saw something weird with the logic that reset the GTH on errors (state machine stayed in reset): this is fixed
- never saw any 929kHz frames counted (perhaps similar to xpmmini→lcls2timing issue we also observed?): not fixed
- matt asks: are they stuck at zero? polarity wrong? two-byte sequences aligned on wrong byte?
- also saw that the ConfigLclsTimingV2 button in devGui didn't work correctly (a missing register) and found a software bug which he has fixed for epixHR, but which may be broken elsewhere (fixed for epixHR)
- Julian will check camera link as well.
Going Forward
(from mtg on Nov. 27, 2023)
- Julian:
- focus on the stuck frames in the epixHR system
- four prototype XPM boards are in production with new connector (only 1 so far?). Larry will work with Julian (with advice from Matt) to test the boards. One goes to BPM group, another to low-level-RF test stand. Not clear who these are going to (we're not the only customer)
- will implement bucket-hopping fix (with advice from Matt)
- Riccardo
- will test when bucket-hopping fix is available
- non-self-locking xpm ports
- longer term: add hsd/wave8 systems to test stand
- cpo will try to reproduce the stuck-frames (which we "fix" with xpmmini→lcls2 workaround) with the tixel system that Christos Bakalis is using. Now scheduled for Dec. 12
Meetings
Jan. 5, 2024
(Julian, matt, Riccardo, cpo)
- from Julian:
- fixed off-by-one word problem for epixhr only
- found an issue with all firmware (including camlink). has fix for camlink as well but not pushed to git (should go into lcls2-pgp-pcie-apps). aim for a new official version by Wednesday jan. 10 2024.
- has played with latest XPM ATCA carrier board with multiple old AMC boards (6 boards). the XPM has the new connector. changed equalizer parameters to get almost all the AMC cards (5) working (one does not boot at all). used same ATCA board.
- equalizer parameters may fix room 208 XPM link issues: have one parameter that works for all boards, but using fiber loopback. equalizer settings might need to change depending on fiber length?
- equalizer parameters are visible in rogue (xpm python should set these, currently use the defaults?)
- some older AMC cards (C02 is the old version, currently on C04?) may need a re-work which we may not have? might also explain the room 208 issues?
- don't know the status of the other 3 prototype XPM boards
- from Matt:
- have a new xpm version with the "Julian fix". test in fee alcove?
- for the bucket-hopping fix need to connect a reset to a FIFO
- fixes we would like before start of running in early Feb. 2024:
- fixes we would like:
- equalizer, "Julian fix", bucket-hopping
- systems we like to fix:
- xpm, camlink (now generic in lcls2-pgp-pcie-apps), timing, hsd, wave8, tpr system
- other systems that need it: epixhr, epixm, epixuhr, high-rate encoder, ued epix kcu1500, tixel
- we think maybe were can do this by early Feb. 2024
- fixes we would like:
To do:
- Julian:
- provides equalizer parameters
- works on remaining 3 XPM prototypes to make sure they're good
- provides lcls2-pgp-pcie-apps firmware for camlink
- Riccardo:
- check the room 208 xpm fiber-loopback with the new equalizer parameters when they are available
- check the bucket hopping fix when it is available
- (lower priority) ideally add hsd/wave8 to the teststand
- to try to get the data links to be robust to power outages and fiber-unplugs
- possibility to put it in an existing drp node (if we remove infiniband card) or cpo thinks we may have a spare chassis (setup from Omar might block us)
- Matt:
- provides new firmware with above fixes, and programming of equalizer values
- Chris:
- work with Christos to get the fixes in the tixel
May 29, 2024
Update from Julian:
- hsd-kcu eyescan software needs to be pushed
- Julian will merge the eyediag and/or eyescan branches as needed
- hsd jesd scan is in progress
- XPM order need to clarify if there are one or two orders, and how many pm's does the photon side get? We need 2 for mfx, 2 for txi plus spares. Matt is asking Thuy for this info.
- Update: Matt writes that we own the following hardware: "2 xpm boards are ready (Thuy has them), 2 xpm boards are still being completed by Lupe. We have 8 AMC cards (need 2 per carrier). We have 2 passive timing fanouts and 2 network switches (one is in use elsewhere). She lists 2 atca crates with no location - I think those are not yet acquired". Matt says Maybe only have 4 carriers. Julian only has 2 AMC cards, but perhaps those are for the "other order" that isn't LCLS.
- ATCA crate vendor still in-progress (need 2 for mfx (hutch/mezzanine) and 1 for txi)
- Matt says there might be a board that can do low-jitter xpm functionality. This would be cool.
June 12, 2024
- Whole xpm->hsd→drp path is done except the JESD links. Needs latest xpm/hsd/drp firmware. New hsd firmware is 0x5000100. Feb. 6 hsd-drp firmware here https://github.com/slaclab/l2si-drp/releases (4.0.4) has this. hsd needs new software since the address map changed (backwardly incompatible) but still in the eyediag branch only. be careful when we merge this branch (do this in July downtime?)
- JESD link eye-scan is in-progress (getting close)
- JESD links are over the mezzanine connector (not firefly)
- cmp005 datadev_1 eye-scan looks terrible (rix hsd_2, hsd_3, which are known bad). lab3 hsd looks "poor" BER 10**-19, but expect 10**-21 in loopback mode.
- Matt says two parameters in the MGT to try to improve lab3 loopback (exposed in pgp axilite interface): "diff control" "post cursor" (tx params). matt exposed in epics.
- not aware of any QSFP parameters (and we don't have I2C bus hooked up)
Overview
Content Tools