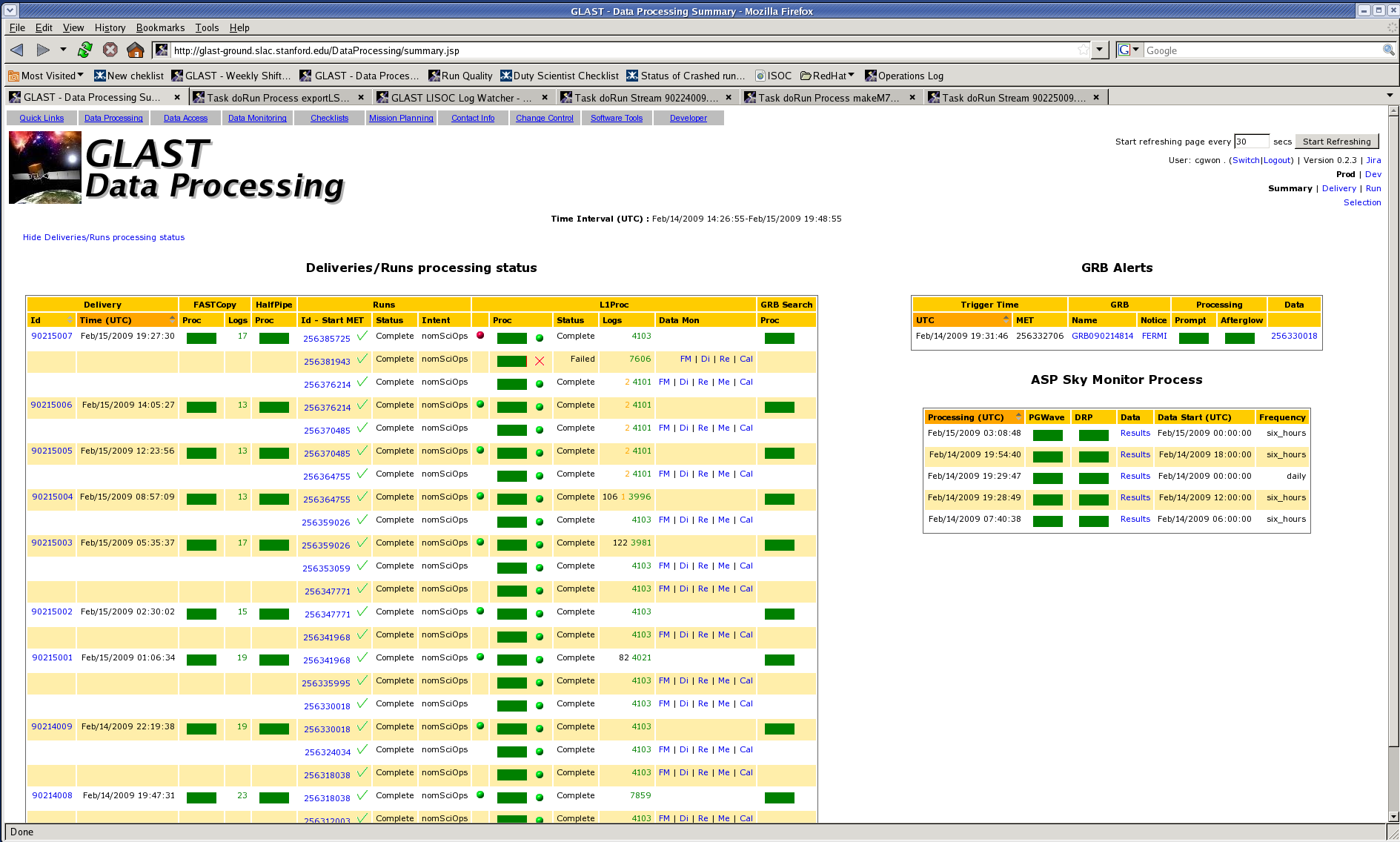
L1Proc and halfPipe. Every time a red cross appears on the Data Processing page, next to the L1Proc or halfPipe processing status bar, the Level 1 on-call expert will be paged. We are not on-call for ASP/GRB search (Jim Chiang (jchiang{at}slac) should be emailed (not paged) for these failures) and we are definitely NOT on-call for infrastructure problems (can't see monitoring plots, etc.). If you get paged for something that is not under your responsibility, don't try to fix it: forward the message to the appropriate people and report everything in the Ops Log.
There are 3 main type of failures, and should be handled differently.
How to recognize transient failures: they usually affect only one single job (disk or DB failures), or a small number of jobs all on the same machine (LFS failure). If a process complains about a missing file but the file exists, or gets a read error after opening a file, it's probably a disk server hiccup. If the log file ends suddenly, without the usual LSF postlog, the batch host probably crashed. There will probably be several jobs failing the same way at the same time.
What to do in case of transient failures: rollback the affected process(es) when possible (see below for the rollback procedure). Look for the dontCleanUp file and check the Log Watcher (see below). If recon segfaults for no apparent reason, email Heather and Anders before the rollback, including a link to the log file, which will tell them where the core file is. For pipeline deadlocks, email Dan and include a link to the process instance.
Transient failures are rare lately. For the last couple of months, most failed processes are automatically retried once. This usually fixes transient issues, so usually when there's a failure it indicates an actual problem.
Bad merges: If a process that's merging crumb-level files into chunks or chunks into runs can't find all of its input files, it won't fail. See the "dontCleanUp" section below. Processes downstream of such a merge may fail because they are trying to use different types of input files (e.g., digi and recon) and the events don't match up because some are missing from one file and not the other. Then you need to roll back the merge even though it "succeeded" the first time.
How to recognize infrastructure failures: they usually affect a large number of jobs, either on the same LSF host or on different LSF hosts.
What to do in case of infrastructure failures: these failures involve a large number of people to be taken care of (the infrastructure expert on-call and often also the SCCS), so for the time being still page Warren and/or Maria Elena (see L1 shift schedule) if you think that one of those failures might be happening during the night (if in doubt, page anyways).
How to recognize permanent failures: besides those 2 cases, everything that doesn't get fixed after a rollback is by definition a permanent failure.
What to do in case of permanent failures: contact the appropriate people above, if you are sure you know what happened. Otherwise, page Warren and/or Maria Elena (see L1 shift schedule). If there is another part of the run waiting, the run lock (see below) will have to be removed by hand; page unless you're really sure of what you're doing.
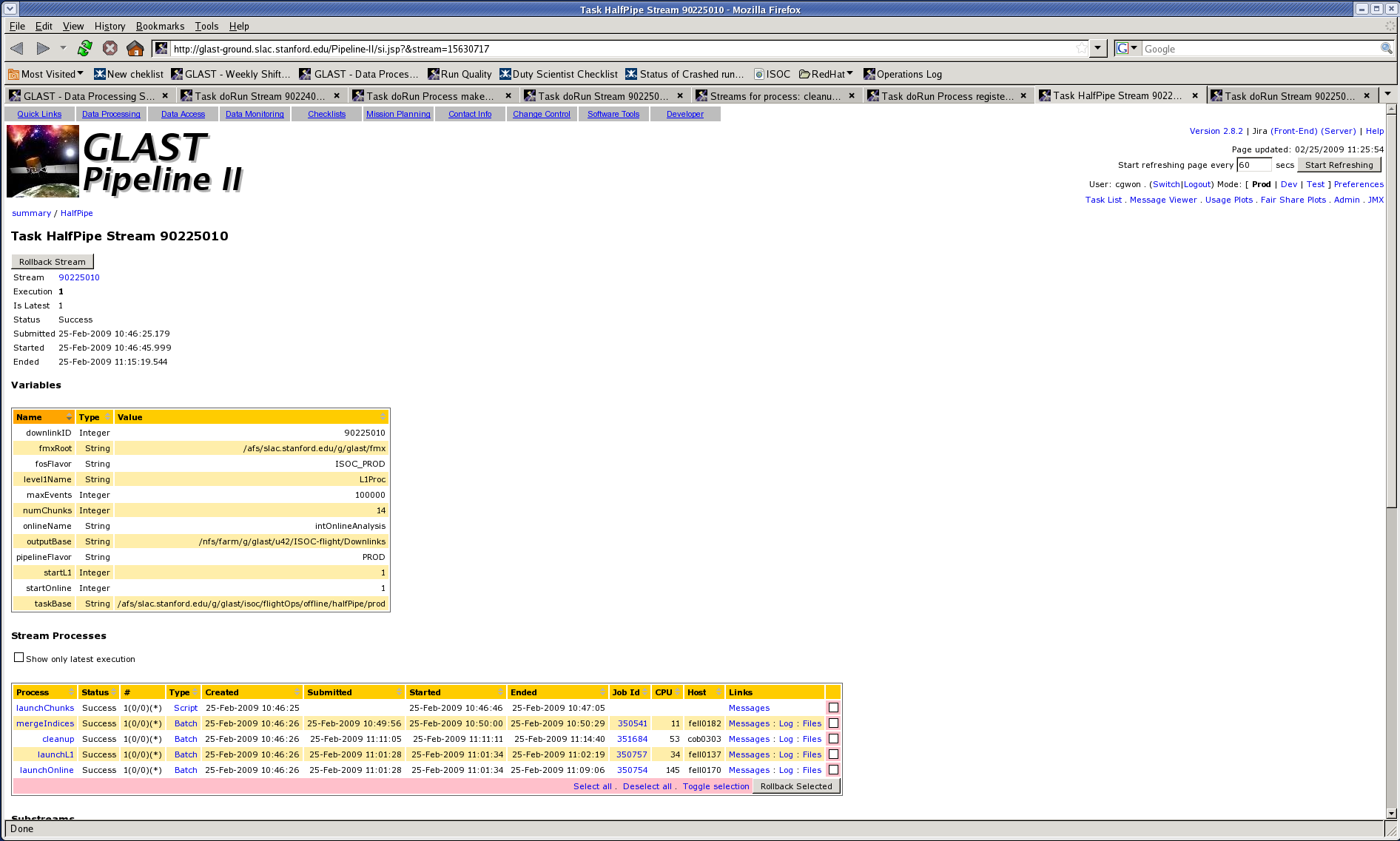
You can roll back from the pipeline front end. The entire stream can be rolled back by clicking "Rollback Stream" at the top, or individual streams in the main stream can be rolled back by selecting the pink boxes under "Stream Processes" and clicking "Rollback Selected".
But if multiple processes have failed (common), it's usually better to use the command line.
/afs/slac.stanford.edu/u/gl/glast/pipeline-II/prod/pipeline \-m PROD rollbackStream \--minimum 'L1Proc\[80819007\]' |
This will roll back all of the failed, terminated, or cancelled processes in delivery 80819007. If you don't say --minimum, it will roll back the whole delivery. That's usually not what you want.
After a rollback, the red x on the data processing page will be gone, but the L1 status will still say Failed. This tends to confuse the duty scientists. You might want to use the setL1Status task (see bellow) to make it say Running. This is really optional, it won't affect the processing in any way. But there will be fewer pagers beeping.
Removing "dontCleanUp" is not necessary to process the data. The file just stops temporary files from getting deleted when we're done with them.
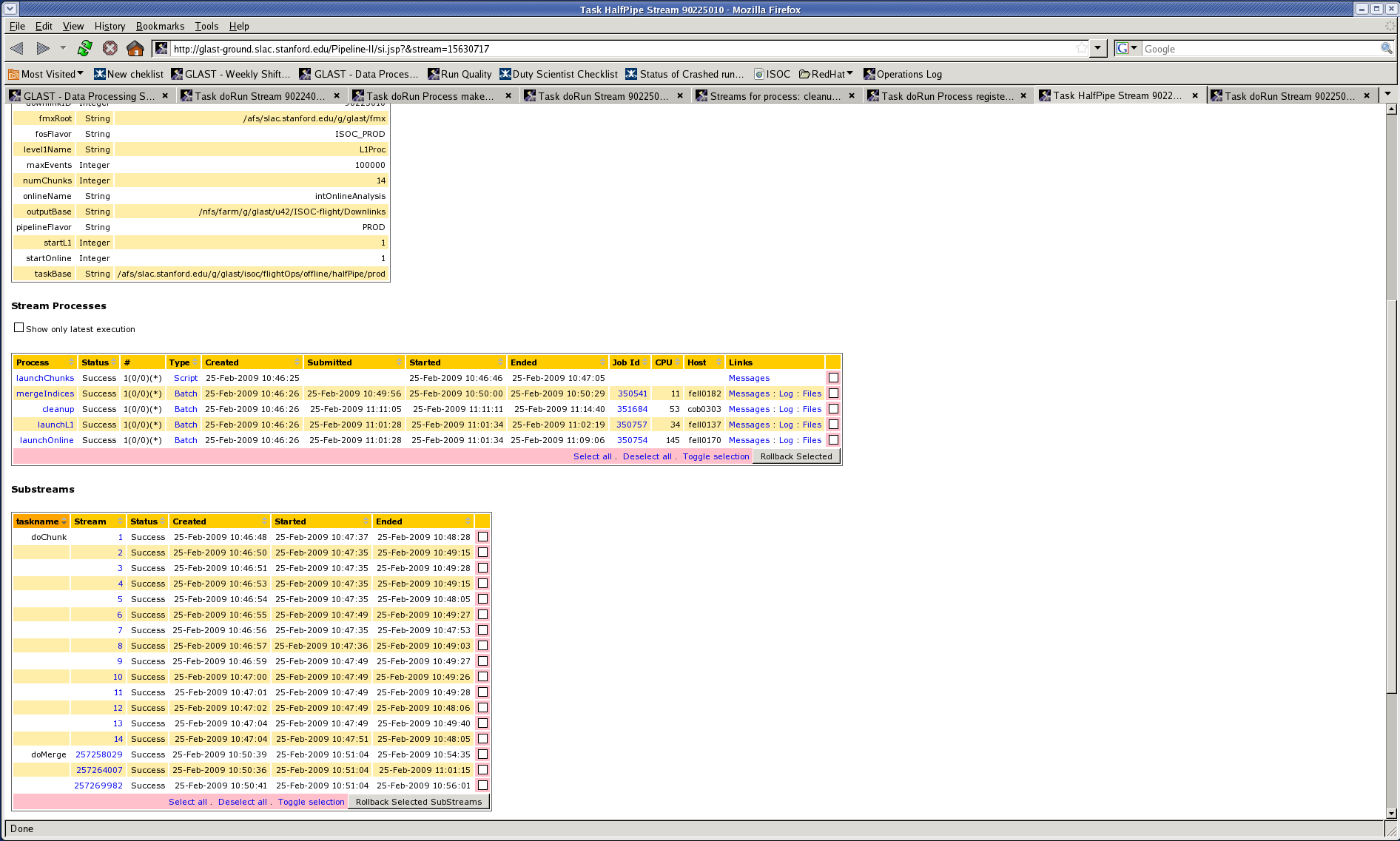
From the front end, find the "Substreams" area and click the pink boxes for substreams that you want to roll back. Then click "Rollback Selected SubStreams".
From the command line it's a bit more tricky: /afs/slac.stanford.edu/u/gl/glast/pipeline-II/prod/pipeline \-m PROD rollbackStream \--minimum 'L1Proc\[90117001\]/doRun\[253889937\]' |
Remember to escape the square brackets if you are in tcsh.
Wait for the "setCrashed" stream to have run.
Rollback won't work unless everything downstream of the failed process is in a final state. It's generally not harmful to try too soon, you just get an unhelpful error message. Most things at run level can be rolled back right away. If a recon job fails, you'll have to wait at least an hour. Maybe half a day.
Notice that the GRB search is executed per delivery and depends on all the FT1 and FT2 files in each run to be registered (therefore, it depends on almost "everything" that belongs to that delivery). For this reason, you might need to wait for the entire delivery to be completed before being able to roll back any failed recon jobs. And because of the run lock (see below), some of the (parts of) runs in the delivery might have to wait for other deliveries to finish, which might have their own failures... It's possible, but rare, to get deadlocks, where nothing can proceed until a lock is removed by hand. Best to ask for help then.
In general, experience will tell you when you can roll back what. So, in doubt, you can try anyways (if it's too soon, nothing will happen and you will get an error)!
Often you can roll things back sooner if you cancel some processes. If there is a delivery with some runs that are ready to roll back and others that aren't, you can do the rollback if you cancel kludgeAsp. "/afs/slac.stanford.edu/u/gl/glast/pipeline-II/dev/pipeline -m PROD cancelProcessInstance 13388768" The number (or numbers, you can use a space-separated list to do more than one at a time) is the oracle PK for the process instance, it's in the URL for the process instance page in the frontend. This takes a long time, 10-30 minutes.
Any time one of the merges processes can't find all of its input files, a message is generated in the Log Watcher and cleanup for the run is disabled by a file called dontCleanUp in the run directory on u52/L1. All cleanup jobs will fail if the dontCleanUp file is present. If everything is OK (see instructions below), that file can be removed and the jobs rolled back.
To check that everything is OK, follow these steps:
Any time one of these messages is generated, cleanup for the run is disabled by a file called dontCleanUp in the run directory on u52/L1. All cleanup jobs will fail if that file is present. If everything is OK, that file can be removed and the jobs rolled back (remember to clean up first the crumbs and then the entire run... you'll get an error that's hard to fix otherwise).
Only one delivery can process a run at a time. This is enforced by a lock file in the run directory on u52/L1. If findChunks fails or there are permanent failures in the run and another part of the run is waiting, it has to be removed by hand. It should never be removed unless the only failures in the run are findChunks or permanent ones, or there's a deadlock. Even then you have to wear a helmet and sign a waiver.
When the AFS servers where we keep temporary files hiccup, it's usually because they ran low on idle threads. It is possible to monitor this value and intervene to stave off disaster. It can be viewed with Ganglia or Nagios. Nagios only works inside SLAC's firewall, but is somewhat more reliable. Ganglia works from anywhere, and shows higher time resolution, but sometimes it stops updating and just shows a flat line with some old value.
Now you should be able to access SLAC-only pages. There's 2 places to get the threads:
When the servers are idle, idle threads should be 122. The SLAC IT people consider it a warning if it goes below 110 and an error at 100. I usually start thinking about taking action if it stays below 60 for more than a few minutes. This is likely to occur if there are more than ~300 chunk jobs running. Usually after recon finishes and the chunk-level jobs downstream of recon start up. I've written a script that will suspend jobs that are using a specified server, wait a bit, and then resume them with a little delay between:
The association between disk and server can be found in several ways. Here's one:
You should definitely join the following mailing lists:
And probably these:
Tired of being paged because L1Proc status still says Failed after a rollback?
/afs/slac/g/glast/ground/bin/pipeline --mode PROD createStream --define "runNumber=240831665,l1RunStatus=Running" setL1Status
OR:
/afs/slac/g/glast/ground/bin/pipeline --mode PROD createStream --define "runNumber=240837713" setL1Status
l1RunStatus defaults to Running, but you can set it to any of the allowed values (Complete, InProgress, Incomplete, Running, Failed).
* The monitoring shifter doesn't need to do anything about it. The L1 shifter should figure out why it happened. In this case, it was because I rolled back a merge job in a run that was already done. (Warren)Message text: Can't open lockfile /nfs/farm/g/glast/u52/L1/r0248039911/r0248039911.lock.
Here's the syntax to cancel a process that is not in final state, and all its dependencies:
/afs/slac.stanford.edu/u/gl/glast/pipeline-II/dev/pipeline --mode PROD cancelProcessInstance 8073657
Please don't use this unless you really (REALLY!!!) know what you are doing.
If you see jobs being terminated with exceptions in the message viewer saying things like "yili0148+5: Host or host group is not used by the queue. Job not submitted.", it means the hosts available to glastdataq have changed. The solution is to roll back the affected chunks (the doChunk streams) with a new value for HOSTLIST. When you roll back the streams from the frontend, on the confirmation page you are presented an opportunity to set or redefine variables. To figure out what the new value needs to be, do a "bqueues -l glastdataq". The output will include a line like "HOSTS: bbfarm/". In this case you'd enter HOSTLIST=bbfarm in the box on the confirmation page. bbfarm is actually a temporary thing for the cooling outage, when things get switched back to normal, the relevant line from bqueues will probably look more like "HOSTS: glastyilis+3 glastcobs+2 preemptfarm+1". Then the thing to enter in the box would be HOSTLIST="glastyilis glastcobs genfarm".
{kind=link}
{kind=link}
{kind=link}