...
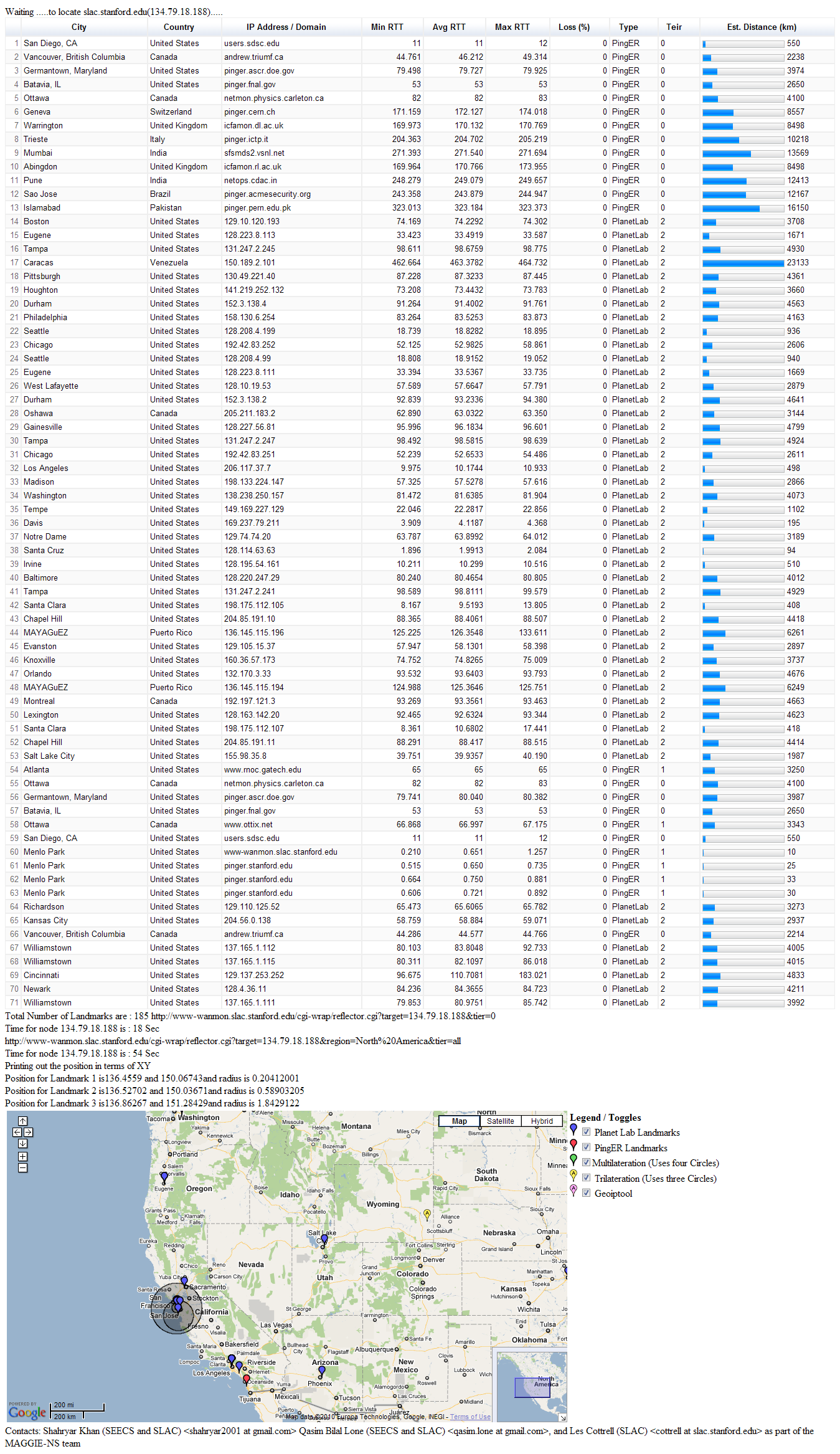
Faisal generated TULIP results for SLAC as target (134.79.18.188) and TULIP geo-located it to be in Wyoming. Screenshot here. This is obviously way off.
{kind=link}
CBG results
Dr. Les quickly explained what TULIP was doing and wanted to do a quick analysis of the same location (i.e. SLAC) using CBG with trilateration. So I found a target located at SLAC (134.79.18.134) in CBG list. We ran CBG with trilateration for this target. The results were way off. The error distance was of the order of ~3200 km.
However Dr. Les pointed out that we should be using three landmarks that have the minimum RTT values from the target. Thus we shuffled our values accordingly and re-ran the test with two different set of landmarks for the same target (SLAC). This helped to verify our results. Table below shows the results:
Landmark 1 | Landmark 2 | Landmark 3 | Error (km) | Distance to nearest landmark (km) | Area of Region (km) | Est. Lat/Long | Actual Lat/Long36.9899 -122.06 |
|---|---|---|---|---|---|---|---|
36.9899 -122.06 (Santa Cruz) | 38.4829 -121.64 (Davis) | 37.3558 -121.954 (Santa Clara) | 25.254 | 2.5132 | 1498.5 | 37.474 -121.93 | 37.418 -122.2 |
37.4285 -122.178 (Stanford) | 37.3762 -122.183 (Palo Alto) | 37.3558 -121.954 (Santa Clara) | 2.5156 | 2.5132 | 1048.8 | 37.429 -122.18 | 37.418 -122.2 |
CBG with trilateration seems to be is performing well.
...
These results prove that trilateration works. So the question is why is TULIP failing so miserably?
CBG multilateration vs CBG trilateration comparison
Spreadsheet shows a comparison of error (in km) between CBG with multilateration and CBG with trilateration. The technique I've followed:
...
| Code Block | ||||
|---|---|---|---|---|
| ||||
if constraintType
warning('Trying speed of light')
constraintType = 0;
% switch the constraint type and try again
[locest,actual,error,regarea,distNearestLandmark,target_id,constraintType,inRegion\] = geolocate(file,extension,hullbool, constraintType, bestlineTable);
return;
else
% find the badPairs that lead to no region, write them to stdout
badPairs = analyzeNoRegion( measurements )
%error(\['No SOL intersection region for ', char(file)\])
region = \[NaN NaN\];
locest = \[NaN NaN\];
error = NaN;
regarea = NaN;
results = \[target_id error; distNearestLandmark regarea; locest; actual; region\];
dlmwrite(\[char(file),char(extension)\],results,' ');
return;
end;
|
A sample of "bad pairs" is below:
Apart from this another reason for NaNs is unavailability of sufficient non-duplicate landmark estimates. This is also a reason why NaNs occur for 11 targets
2. Some results have enormous errors (|error|>1000)
...
So If we have say 10 landmarks and 4 of them had relatively lower RTT to the target, multilateration will give good results. Even if some values aren't really good, it won't cause multilateration to behave in an entirely different way. However in case of trilateration, better the landmark estimates we have, the better the results are. Since trilateration considers three values, even a single one of those three values can make a big difference.
CBG trilateration vs Improved trilateration
...
comparison
Spreadsheet here shows comparison between CBG's trilateration and Farrah's improved trilateration. A few important points:
...