Page History
| Table of Contents |
|---|
To-Do List
- eye-scans for all transceivers
- work on high-speed-digitizer timing robustness using teststand
- occasional need to restart hsdioc process
- kcu1500 can lose link and hsd loses/regains power, and can only be recovered by power cycling cmp node
- check wave8 timing robustness
- (almost done) program hsd firmware over pcie?
- manufacture new xpm boards (4 for txi)
- do we need another xpm/crate order for mfx? (separate from LCLS-II-HE?). go from mfx hutch back to 208 or the mezzanine?
- reproduce/fix timing nodes assigning wrong timestamp to configure transition by 1 or 2 buckets
- matt thinks this is on the receiver side: some fifos that carry daq data separate from timing data. matt thinks perhaps we have to connect the resets to those fifos.
- have seen this is hsd/wave8. see both being problematic after a power outage here: /cds/home/opr/tmoopr/2024/03/04_17:11:56_drp-srcf-cmp030:teb0.log (and Riccardo saw it in his tests, below)
- (perhaps done by fixing reset logic?) reproduce/fix link-lock failure on timing system KCUs
- make pyxpm processes robust to timing outages?
- (done) ensure that Matt's latest xpm firmware fixes the xpm link-glitch storms
- (perhaps done by fixing reset logic ?) reproduce/fix TxLinkReset workaround
- (perhaps done by fixing reset logic?) reproduce/fix xpmmini-to-lcls2timing workaround
- (done, fixed with equalizer 0x3 setting) check/fix loopback fiber problem in production xpms in room 208
- after Julian's fixes in late 2023 on April 7 we had a failure where cmp002 kcu wouldn't lock to its timing link. power cycling "fixed" the problem.
- also saw two incidents in April 2024 where "cat /proc/datadev_0" showed all 1's (0xffffffff) everywhere as well as nonsensensical string values. Likely triggered Triggered by timing outages? One of the instances was on cmp002 and I think the other one was on another node that I don't recall.
- saw an issue where the 88:B hsd in tmo on cmp046 showed good link, but hsdpva showed a bad link?
| Code Block |
|---|
locLinkRdy : 1 1 1 1 1 1 1 1
remLinkRdy : 1 1 1 1 1 1 1 1 |

- (also after Julian's fixes in late 2023) this file shows a failure mode of a tdet kcu1500 on drp-srcf-cmp010 where its pulse-ids were off by one pulse-id ("bucket jumping" problem that Riccardo reproduced on the teststand): teb log file showing the cmp010 problem: /cds/home/opr/rixopr/scripts/logfiles/2024/04/08_11:58:28_drp-srcf-cmp013:teb0.log. Powercycling "fixed" the problem. Split event partial-output from that log (two Andor's on cmp010 timestamps were incorrect, since all other detectors showed 0x8ff3 at the end). A similar failure on drp-srcf-cmp025 can be seen here: /cds/home/opr/rixopr/scripts/logfiles/2024/04/13_12:43:08_drp-srcf-cmp013:teb0.log. There was a timing outage two days previously, I believe.
...
- See this issue on drp-srcf-cmp002:
Code Block drp-srcf-cmp002:~$ cat /proc/datadev_0 -------------- Axi Version ---------------- Firmware Version : 0xffffffff ScratchPad : 0xffffffff Up Time Count : 4294967295 Device ID : 0xffffffff Git Hash : ffffffffffffffffffffffffffffffffffffffff DNA Value : 0xffffffffffffffffffffffffffffffff Build String : �������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������A
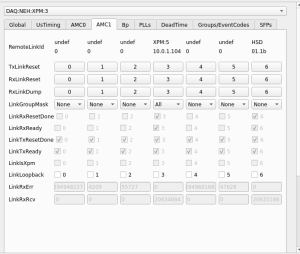
- XPM Link issues 2024/04/10-2024/04/11:
- Around 14:00-14:10 on 2024/04/10, RIX Grafana page shows there were fairly global XPM issues (measured by
XPM RxDspErrsrates) - XPM5 link (XPM3-5) goes down around 14:07 on 2024/04/10
- Other XPMs recover but 5 does not, and the link stays down.
xpmpvashows XPM5 looks mostly healthy except for theRxLinkUp- Required
TxLinkResetto restoreRxLinkUp(on 2024/04/11 ~09:15). 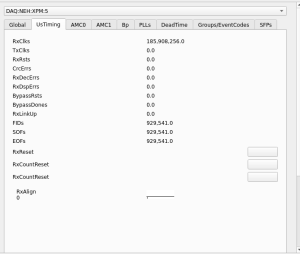
- Around 14:00-14:10 on 2024/04/10, RIX Grafana page shows there were fairly global XPM issues (measured by
Summary Of Testing
These are the results of the tests that have been conducted in the FEE alcove to determine if the XPM glitch can be reproduced.
Every test is run from a starting behavior where the DAQ can allocate, configure, run, and disable.
Whenever the DAQ does not follow the starting behavior remedies are applied to recover it.




xpm10 and 11 connections

XPM schematics
Testing Details
In 2023/10/24 :
XPM firmware 3.5.4
Opal_config.py has xpm mini – timing2 hack
| action | result | remedy | result |
|---|---|---|---|
| Remove XPM10 fiber timing in the back while DAQ running | *** XpmDetector: timing link ID is ffffffff = 4294967295^M | TxlinkReset of cmp015 in XPM11 | DAQ recovers |
| Repeat XPM10 fiber timing removal removal | DAQ cannot disable | --- | DAQ recovers by itself at restart |
| Repeat XPM10 fiber timing removal removal | --- | --- | no issue |
| Repeat XPM10 fiber timing removal removal | DAQ cannot disable | --- | DAQ recovers by itself at restart |
| Remove XPM10 fiber timing in the back while DAQ stopped | --- | --- | DAQ starts with no issue |
| Repeat XPM10 fiber timing removal removal while DAQ stopped | --- | --- | DAQ starts with no issue |
| Remove transceiver from XPM10 in the back (DAQ stopped) | --- | --- | DAQ starts with no issue |
| Remove transceiver from XPM10 in the back (DAQ started) | --- | --- | DAQ starts with no issue |
timing 1 shutsdown by itself | TXlinkReset on XPM10 for XPM11 | DAQ recovers | |
| Remove fiber on XPM10 to XPM11 | --- | --- | DAQ starts with no issue |
| Remove transceiver on XPM10 to XPM11 | --- | --- | DAQ starts with no issue |
| Remove fiber on XPM11 AMC0 port 0 | --- | --- | DAQ starts with no issue |
| Remove transceiver on XPM11 AMC 0 port0 | --- | --- | DAQ starts with no issue |
opal disappears from the list f detectors | restart DAQ | DAQ starts with no issue | |
| power cycle xpm10 via switch only AMC0 | XPM 11 looses timing node | Restart pyxpm 10 and 11 restart pyxpm 11 | DAQ restarts but opal shutsdown |
opal still shutdown | devGui xpmmini timing v2 | no avail | |
Stop pyxpm 10 and 11 | DAQ starts with no issue |
In 2023/10/26:
| action | issue found | error stat | remedy |
|---|---|---|---|
stop pyxpm 10 and 11 | no issue has been detected | 0/10 | --- |
stop pyxpm 10 and 11 | at first xpmpva DAQ:NEH:XPM:11 does not come up Then Opal shutsdown | 3/20 | stop pyxpm 10 and 11 |
Observation Of Front-Panel XPM Link Glitch With Version 3.5.4
Perhaps fixed by Matt in later firmware version?
...
XPM11 glitches between 4pm and after 6pm and also around 10:10 am the next day
2023/10/27: updating firmware
xpm11 to xpm_noRTM-0x030601000-20231011111938-weaver-645bee8.mcs
xpm10 to xpm-0x030601000-20231011111954-weaver-645bee8.mcs
...
XPM firmware 3.6.0 (?3.6.1?)
Opal config does not have xpm mini -timing2 hack
cnf file uses -D fakecam for additional timing nodes
in 2023/10/30
| action | issue found | stat | remedy |
|---|---|---|---|
stop pyxpm 10 and 11 | 9/20 | --- | |
stop pyxpm 10 and 11 | Opal fails in configuration | 5/20 | reboot timing nodes |
stop pyxpm 10 and 11 | groupca and xpmpva are shutdown at startup | 4/20 | ctrl-x in the terminal successfully restart them |
...
example of the timing shift in the timing nodes (before -D fakecam).
in 2023/11/14
| action | issue found | stat | remedy |
|---|---|---|---|
| stop pyxpm 10 and 11 fru-deactivate and activate xpm 11 restart pyxpm 10 and 11 start DAQ | bucket issue | 1/10 | rebooting timing node cmp001 |
| rebooting timing node cmp001 | no issue | 0/5 | |
remove fiber from xpm10 to xpm11 fiber 10 times | no issue | 0/10 | |
Removing fiber from xpm10 to timing 1 fiber 10 times for 5 seconds (Amc1 port0) | no issue | 0/10 | |
Removing fiber from xpm11 to opal fiber 10 times for 5 seconds (Amc1 port1) | no issue | 0/10 |
in 2023/11/17
New opal_config.py: remove sleep while requesting mini/v2 introduce check for RxId instead with timeout of 10 repeats.
| action | issue found | stat | remedy |
|---|---|---|---|
| test power cycle she-fee-daq01/2 10 times | bucket issues | 3/10 | power cycling the xpm10 (txlinkreset didn't fix) |
| RTM disconnected in increades timing 5min 10 min 40 min 2hours | bucket issue (2 hours) | 1/4 | power cycle of xpm10 (txlinkreset didn't fix) |
in 2023/11/21 switching XPM firmware
from drp-neh-ctl002
~weaver/FirmwareLoader/rhel6/FirmwareLoader -a 10.0.5.104 /cds/home/w/weaver/mcs/xpm//xpm_noRTM-0x03050400-20230409095511-weaver-dirty.mcs
~weaver/FirmwareLoader/rhel6/FirmwareLoader -a 10.0.5.102 /cds/home/w/weaver/mcs/xpm//xpm-0x03050400-20230419122542-weaver-c6987c4.mcs
...
Power-on the tixel computer (the equivalent of cmp005) with the fiber unplugged, then we plugged in the fiber and it didn’t lock until we did xpmmini→lcls2. It appears that yanking the timing fiber can cause disturbances in the system, but they are not repeatable 100% of the time. XPMs Power spikes can set the DAQ in a behavior similar to the XPM glitch, but only if pyxpms are running. To be repeated.
Upgrading XPM firmware seems to have mitigated all the issues (to 3.6.0 from 3.5.4). The bucket issue becomes more prominent, probably because other issues are not happening. This issue appears when power cycling the xpm11. Also, xpmmini issue could appear when connecting already powered up nodes.
in 2023/11/27
testing double offence.
rebooting a node with cameralink without the fiber connected and connect the fiber after
| action | issue found | stat | remedy |
|---|---|---|---|
| rebooting cmp005 with timing fiber disconnected from xpm, then connect fiber when cmp is back on line | none | 0/5 | xpmpva does not see the opal until the daq is booted up. No ISSUES. |
Brainstorming Session
Nov. 16, 23 with mona, dan, weaver, caf, claus, melchior, cpo
...
matt has an idea for bucket-jumps. could direct julian.
Results from Julian
- has kcu1500 xpm (not xpmmini) transmitting to txi epixHR
- with Dawood observed RxLinkUp never came up until they added debugging stuff
- saw something weird with the logic that reset the GTH on errors (state machine stayed in reset): this is fixed
- never saw any 929kHz frames counted (perhaps similar to xpmmini→lcls2timing issue we also observed?): not fixed
- matt asks: are they stuck at zero? polarity wrong? two-byte sequences aligned on wrong byte?
- also saw that the ConfigLclsTimingV2 button in devGui didn't work correctly (a missing register) and found a software bug which he has fixed for epixHR, but which may be broken elsewhere (fixed for epixHR)
- Julian will check camera link as well.
Going Forward
(from mtg on Nov. 27, 2023)
- Julian:
- focus on the stuck frames in the epixHR system
- four prototype XPM boards are in production with new connector (only 1 so far?). Larry will work with Julian (with advice from Matt) to test the boards. One goes to BPM group, another to low-level-RF test stand. Not clear who these are going to (we're not the only customer)
- will implement bucket-hopping fix (with advice from Matt)
- Riccardo
- will test when bucket-hopping fix is available
- non-self-locking xpm ports
- longer term: add hsd/wave8 systems to test stand
- cpo will try to reproduce the stuck-frames (which we "fix" with xpmmini→lcls2 workaround) with the tixel system that Christos Bakalis is using. Now scheduled for Dec. 12
Touch Base on Jan. 5, 2024
(Julian, matt, Riccardo, cpo)
...
Overview
Content Tools