Page History
| Table of Contents |
|---|
Issue
| Code Block | ||||
|---|---|---|---|---|
| ||||
2024-01-04 1:22pm Li, Yee Ting; Kroeger, Wilko Hi Mikhail, (cc: Yee, Wilko since they may have an interest in this) When you have a chance, could you look at the scaling behavior of this script. It tries to "prefetch" the data from disk (for 100 events per core) with det.raw, and then times the behavior of det.calib: ~cpo/problems/cxix1000021_scaling/cxix1000021_scaling.py To do this get exclusive access to a batch node with this command: srun --partition milano --account lcls:prjdat21 -n 1 --time=01:00:00 --exclusive --pty /bin/bash The in another window ssh to the node that you have been allocated (the reason this is necessary is obscure: it has to do with an incompatible version of pmix used by srun that our mpi is unhappy with). In that new window run these two commands: mpirun -n 1 python cxix1000021_scaling.py mpirun -n 80 python cxix1000021_scaling.py For me the first one shows about .11s per event while the second shows about .25s per event, which is the poor scaling behavior we would like to understand. You can see logfiles in ~cpo/problems/cxix1000021_scaling in interactive_1core.log and interactive_80core.log. I think the fundamental question that I hope you could answer is: do all numpy operations in det.calib slow down on 80 cores, or is there some other cause for the poor scaling? From discussions we've had with Yee we suspect the poor scaling may be due to behavior of the hardware, but we don't know for sure. Happy to discuss this with you on zoom at any time, of course. Thanks for looking at this! chris p.s. following a suggestion by someone (Yee? Wilko?) I watched the cpu clock speeds in /proc/cpuinfo while the 80 core job was running. To my eye they seemed to vary between ~2.4MHz and ~3.0Mhz which didn't feel like quite enough |
List of commands for this test
| Code Block | ||||
|---|---|---|---|---|
| ||||
> s3dflogin > psana srun --partition milano --account lcls:prjdat21 -n 1 --time=01:00:00 --exclusive --pty /bin/bash Ex: ana-4.0.58-py3 [dubrovin@sdfiana001:~/LCLS/con-py3]$ srun --partition milano --account lcls:prjdat21 -n 1 --time=01:00:00 --exclusive --pty /bin/bash srun: job 37602834 queued and waiting for resources srun: job 37602834 has been allocated resources In .bashrc on host sdfiana001 In .bash_login ana-4.0.58-py3 [dubrovin@sdfmilan031:~/LCLS/con-py3]$ grab example from Chris: ~cpo/problems/cxix1000021_scaling/cxix1000021_scaling.py and modify it as explained below. In other window > s3dflogin ssh -Y sdfmilan031 cd LCLS/con-py3 source /sdf/group/lcls/ds/ana/sw/conda1/manage/bin/psconda.sh source /sdf/group/lcls/ds/ana/sw/conda1/manage/bin/setup_testrel mpirun -n 1 python test-cxix1000021_scaling.py mpirun -n 80 python test-cxix1000021_scaling.py |
Code for time monitoring
| Code Block | ||||
|---|---|---|---|---|
| ||||
def calib_jungfrau(det, evt, cmpars=(7,3,200,10), **kwa):
"""
Returns calibrated jungfrau data
- gets constants
- gets raw data
- evaluates (code - pedestal - offset)
- applys common mode correction if turned on
- apply gain factor
Parameters
- det (psana.Detector) - Detector object
- evt (psana.Event) - Event object
- cmpars (tuple) - common mode parameters
- cmpars[0] - algorithm # 7-for jungfrau
- cmpars[1] - control bit-word 1-in rows, 2-in columns
- cmpars[2] - maximal applied correction
- **kwa - used here and passed to det.mask_v2 or det.mask_comb
- nda_raw - if not None, substitutes evt.raw()
- mbits - DEPRECATED parameter of the det.mask_comb(...)
- mask - user defined mask passed as optional parameter
"""
t00 = time()
src = det.source # - src (psana.Source) - Source object
nda_raw = kwa.get('nda_raw', None)
arr = det.raw(evt) if nda_raw is None else nda_raw # shape:(<npanels>, 512, 1024) dtype:uint16
if arr is None: return None
t01 = time()
peds = det.pedestals(evt) # - 4d pedestals shape:(3, 1, 512, 1024) dtype:float32
if peds is None: return None
t02 = time()
gain = det.gain(evt) # - 4d gains
offs = det.offset(evt) # - 4d offset
t03 = time()
detname = string_from_source(det.source)
cmp = det.common_mode(evt) if cmpars is None else cmpars
t04 = time()
if gain is None: gain = np.ones_like(peds) # - 4d gains
if offs is None: offs = np.zeros_like(peds) # - 4d gains
# cache
gfac = store.gfac.get(detname, None) # det.name
if gfac is None:
gfac = divide_protected(np.ones_like(peds), gain)
store.gfac[detname] = gfac
store.arr1 = np.ones_like(arr, dtype=np.int8)
t05 = time()
# Define bool arrays of ranges
# faster than bit operations
gr0 = arr < BW1 # 490 us
gr1 =(arr >= BW1) & (arr<BW2) # 714 us
gr2 = arr >= BW3 # 400 us
t06 = time()
# Subtract pedestals
arrf = np.array(arr & MSK, dtype=np.float32)
t07 = time()
arrf[gr0] -= peds[0,gr0]
arrf[gr1] -= peds[1,gr1] #- arrf[gr1]
arrf[gr2] -= peds[2,gr2] #- arrf[gr2]
t08 = time()
factor = np.select((gr0, gr1, gr2), (gfac[0,:], gfac[1,:], gfac[2,:]), default=1) # 2msec
t09 = time()
offset = np.select((gr0, gr1, gr2), (offs[0,:], offs[1,:], offs[2,:]), default=0)
t10 = time()
arrf -= offset # Apply offset correction
t11 = time()
if store.mask is None:
store.mask = det.mask_total(evt, **kwa)
mask = store.mask
t12 = time()
if cmp is not None:
mode, cormax = int(cmp[1]), cmp[2]
npixmin = cmp[3] if len(cmp)>3 else 10
if mode>0:
#arr1 = store.arr1
#grhg = np.select((gr0, gr1), (arr1, arr1), default=0)
logger.debug(info_ndarr(gr0, 'gain group0'))
logger.debug(info_ndarr(mask, 'mask'))
t0_sec_cm = time()
gmask = np.bitwise_and(gr0, mask) if mask is not None else gr0
#sh = (nsegs, 512, 1024)
hrows = 256 #512/2
for s in range(arrf.shape[0]):
if mode & 4: # in banks: (512/2,1024/16) = (256,64) pixels # 100 ms
common_mode_2d_hsplit_nbanks(arrf[s,:hrows,:], mask=gmask[s,:hrows,:], nbanks=16, cormax=cormax, npix_min=npixmin)
common_mode_2d_hsplit_nbanks(arrf[s,hrows:,:], mask=gmask[s,hrows:,:], nbanks=16, cormax=cormax, npix_min=npixmin)
if mode & 1: # in rows per bank: 1024/16 = 64 pixels # 275 ms
common_mode_rows_hsplit_nbanks(arrf[s,], mask=gmask[s,], nbanks=16, cormax=cormax, npix_min=npixmin)
if mode & 2: # in cols per bank: 512/2 = 256 pixels # 290 ms
common_mode_cols(arrf[s,:hrows,:], mask=gmask[s,:hrows,:], cormax=cormax, npix_min=npixmin)
common_mode_cols(arrf[s,hrows:,:], mask=gmask[s,hrows:,:], cormax=cormax, npix_min=npixmin)
logger.debug('TIME: common-mode correction time = %.6f sec' % (time()-t0_sec_cm))
t13 = time()
resp = arrf * factor if mask is None else arrf * factor * mask # gain correction
t14 = time()
times = np.array((t00, t01, t02, t03, t04, t05, t06, t07, t08, t09, t10, t11, t12, t13, t14), dtype=np.float64)
return resp, times |
Timing histograms
Single core processing
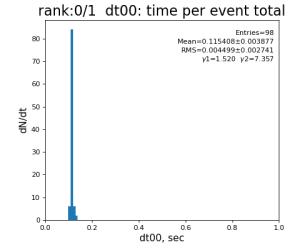
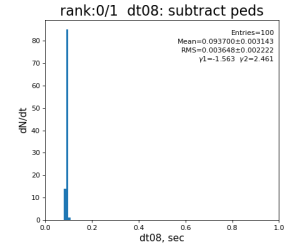
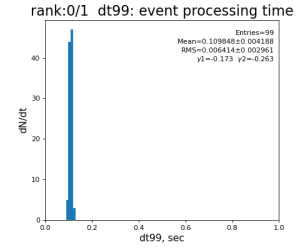
80-core processing for ranks 0, 30, and 60
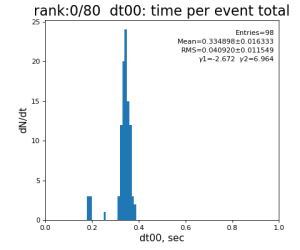
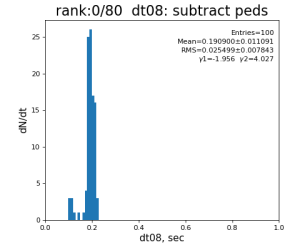
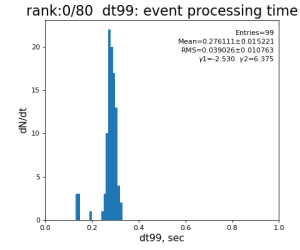
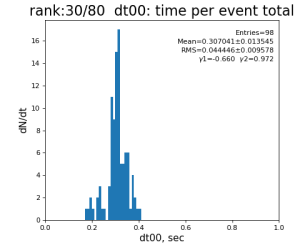
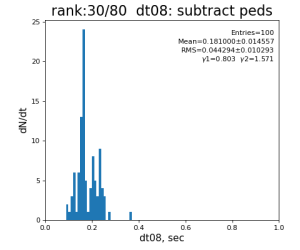
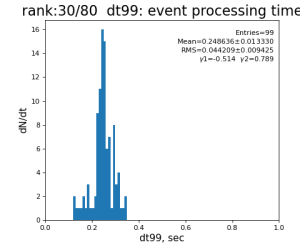
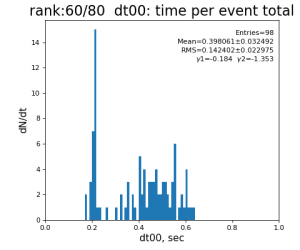
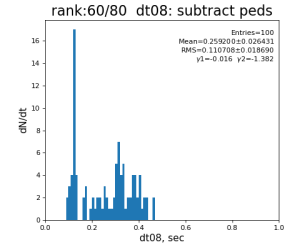
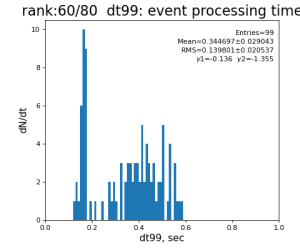
Results
Table shows mean time increment and their statistical uncertainty from associated histograms.
| t point | time increment | point description | time for rank 0/1 | rank 0/80 | rank 30/80 | rank 60/80 |
|---|---|---|---|---|---|---|
| 1 | t1 - t0 | det.raw | 0.8±0.2 ms | 4.0 ±0.6 ms | 3.2±0.4 ms | 3.5 ±0.8 ms |
| 2 | t2 - t1 | det.pedestals | 15±3 μs | 36 ±10 μs | 31±6 μs | 39 ±17 μs |
| 3 | t3 - t2 | det.gain,offset | 15±2 μs | 27 ±4 μs | 26±4 μs | 27 ±6 μs |
| 4 | ... | cmpars | 25±1 μs | 50 ±7 μs | 58±26 μs | 71 ±33 μs |
| 5 | gfac | 2±0 μs | 6 ±1 μs | 7±1 μs | 7 ±2 μs | |
| 6 | gr0,1,2 | 1.3±0.2 ms | 10.5 ±1.1 ms | 7.0±0.9 ms | 9.7 ±1.6 ms | |
| 7 | make arrf | 1.76±0.05 ms | 9.2 ±0.9 ms | 6.3±0.7 ms | 9.0 ±1.5 ms | |
| 8 | subtract peds | 93.7±3.1 ms | 191 ±11 ms | 181±15 ms | 259 ±26 ms | |
| 9 | eval gain factor for gain ranges | 4.9±0.6 ms | 20.3 ±1.5 ms | 14.6±1.2 ms | 17.3 ±2.0 ms | |
| 10 | eval offset for gain ranges | 6.2±0.4 ms | 18.5 ±1.3 ms | 18.4±1.4 ms | 19.2 ±2.1 ms | |
| 11 | subtract offset | 1.0±0.2 ms | 6.0 ±0.7 ms | 5.3±0.6 ms | 6.2 ±1.2 ms | |
| 12 | get mask | 3±2 μs | 6 ±2 μs | 6±2 μs | 7 ±2 μs | |
| 13 | common mode turned off | 7±1 μs | 15 ±2 μs | 17±2 μs | 20 ±3 μs | |
| 14 | t14 - t13 | apply gain factor and mask | 4.0±0.7 ms | 14.9 ±2.0 ms | 13.9±1.6 ms | 19.2 ±3.5 ms |
| 99 | t14 - t0 | per evt time, inside det.calib | 109.8±4.2 ms | 276 ±15 ms | 247±13 ms | 345 ±29 ms |
| 0 | t0 - t0 previous evt | time between consecutive det.calib | 115.4±3.9 ms | 335 ±16 ms | 307±14 ms | 398 ±32 ms |
Summary
- single core processing is faster than per/core time in 80–core case, factor 2.5-3 FOR ALL OPERATIONS
- in 80-core case: time per core is consistent between cores
- all constants are cashed and access to constants is fast at sub-milisecond level
- common mode correction is turned off, as well as mask?
- most time consuming operation is indexed pedestal subtraction
| Code Block | ||
|---|---|---|
| ||
t07 = time()
arrf[gr0] -= peds[0,gr0]
arrf[gr1] -= peds[1,gr1]
arrf[gr2] -= peds[2,gr2]
t08 = time() |
- bad single-to-multicore scaling issue has nothing to do with particular algorithm, it is common problem for any algorithm
2024-01-16 Test for simulated events
Time consuming code
| Code Block | ||||
|---|---|---|---|---|
| ||||
def time_consuming_algorithm():
sh2d = (1024,1024)
sh3d = (3,) + sh2d
a = random_standard(shape=sh2d, mu=10, sigma=2, dtype=np.float64)
b = random_standard(shape=sh3d, mu=20, sigma=3, dtype=np.float64)
gr1 = a>=11
gr2 = (a>9) & (a<11)
gr3 = a<=9
a[gr1] -= b[0, gr1]
a[gr2] -= b[1, gr2]
a[gr3] -= b[2, gr3] |
2024-01-16 Test Summary
- runing on sdfmilan031 - shows minor ~ 5% the mean time difference between 1-core and 80-core processing is larger
2024-01-17 Test for simulated events with minor modifications
Test variation
- array shape is changed from (3, 1024, 1024) → (3, 8*512, 1024)
- array generation is excluded from time measurement, only indexed subtraction contributes to time measurement
- do not pre-create random arrays, it is generated in each core... requires too much memory for all cores.
- run on sdfmilan047: ana-4.0.58-py3 [dubrovin@sdfmilan047:~/LCLS/con-py3]$ mpirun -n 80 python test-mpi-numpy-hist.py
Time consuming code
| Code Block | ||||
|---|---|---|---|---|
| ||||
def time_consuming_algorithm(a, b):
gr1 = a>=11
gr2 = (a>9) & (a<11)
gr3 = a<=9
t0_sec = time()
a[gr1] -= b[0, gr1]
a[gr2] -= b[1, gr2]
a[gr3] -= b[2, gr3]
return time() - t0_sec |
Results
Single core processing
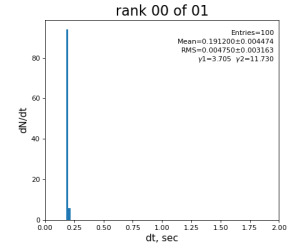
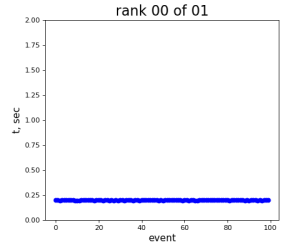
80-core processing for ranks 0, 30, and 60
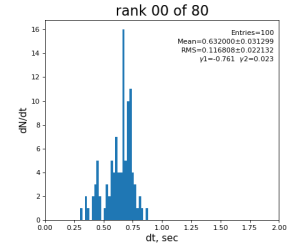
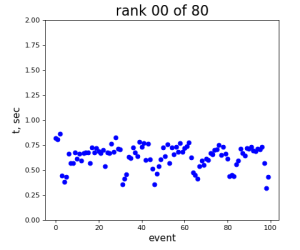
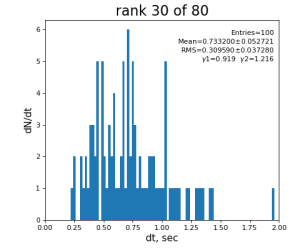
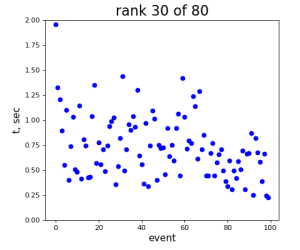
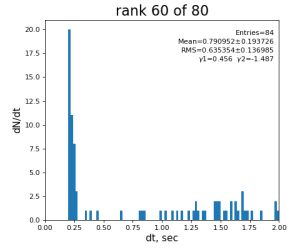
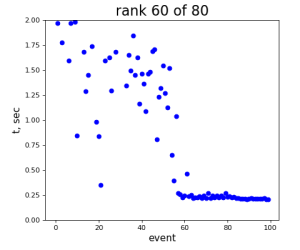
2024-01-17 Test Summary
- if random array generation is excluded from time measurement, the mean time difference between 1-core and 80-core processing is larger
- the main contribution to time difference comes from reserved host...
- sdfmilan047 - looks like extremely "time-noisy" in multi-core processing...
- sdfmilan031 - in previous test looks pretty "calm"
References
Overview
Content Tools