Page History
...
Larry thinks that these are in the raw units read out from the device (mW) and says that to convert to dBm use the following formula: 10*log(10)(val/1mW). For example, 0.6 corresponds to -2.2dBm.
| Code Block |
|---|
(ps-4.1.2) tmo-daq:scripts> pvget DAQ:NEH:XPM:0:SFPSTATUS
DAQ:NEH:XPM:0:SFPSTATUS 2021-01-13 14:36:15.450
LossOfSignal ModuleAbsent TxPower RxPower
0 0 6.5535 6.5535
1 0 0.5701 0.0001
0 0 0.5883 0.7572
0 0 0.5746 0.5679
0 0 0.8134 0.738
0 0 0.6844 0.88
0 0 0.5942 0.4925
0 0 0.5218 0.7779
1 0 0.608 0.0001
0 0 0.5419 0.3033
1 0 0.6652 0.0001
0 0 0.5177 0.8751
1 1 0 0
0 0 0.7723 0.201 |
XPM Timing Links Not Locking
If XPM links don't lock, here are some past causes:
- check that transceivers (especially QSFP, which can be difficult) are fully plugged in.
- for opal detectors:
- use devGui to toggle between LCLS1/LCLS2 timing (Matt has added this to the opal config script, but to the part that executes at startup time)
- hit TxPhyReset in the devGui (this should now be done in the opal drp executable)
- for timing system detectors: run "kcuSim -s -d /dev/datadev_1", this should also be done when one runs a drp process on the drp node (to initialize the timing registers). the drp executable in this case doesn't need any transitions.
- hit Tx/Rx reset on xpmpva gui (AMC tabs).
- Valerio and Matt had noticed that the BOS sometimes lets its connections deteriorate. To fix:
- ssh root@osw-daq-calients320
- omm-ctrl --reset
Network Connection Difficulty
Saw this error on Nov. 2 2021 in lab3 over and over:
| Code Block |
|---|
WARNING:pyrogue.Device.UdpRssiPack.rudpReg:host=10.0.2.102, port=8193 -> Establishing link ... |
Matt writes:
That error could mean that some other pyxpm process is connected to it. Using ping should show if the device is really off the network, which seems to be the case. You can also use "amcc_dump_bsi --all shm-tst-lab2-atca02" to see the status of the ATCA boards from the shelf manager's view. (source /afs/slac/g/reseng/IPMC/env.sh[csh]) It looks like the boards in slots 2 and 4 had lost ethernet connectivity (with the ATCA switch) but should be good now. None of the boards respond to ping, so I'm guessing its the ATCA switch that's failed. The power on that board can also be cycled with "fru_deactivate, fru_activate". I did that, and now they all respond to ping.
Switching Between Internal/External Timing
Do this if accelerator timing is gone. Can see the timestamp is "wonky" to quote Dr. Matthew Weaver.
Only have to do this for the master xpm that is receiving the accelerator timing. Run "pyxpm --ip 10.0.1.102 -I -P DAQ:NEH:XPM:0" (i.e. remove the database flags). The "-I" flag does some initialization, in particular the CuInput flag is set to 1 (for internal timing) instead of 0 (external timing):
This file puts xpm-0 in internal timing mode: https://github.com/slac-lcls/lcls2/blob/master/psdaq/psdaq/cnf/internal-neh-base.cnf. Note that in internal timing mode the L0Delay (per-readout-group) seems to default to 90. Fix it with pvput DAQ:NEH:XPM:0:PART:0:L0Delay 80".
One should switch back to external mode by setting CuInput to 0 in xpmpva CuTiming tab. Still want to switch to external-timing cnf file after this is done. Check that the FiducialErr box is not checked (try ClearErr to see if it fixes). If this doesn't clear it can be a sign that ACR has put it "wrong divisor" on their end.
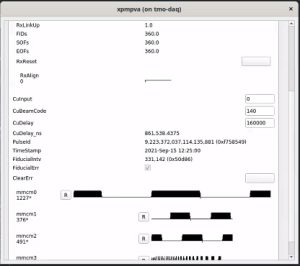
For now (09/20/21) this procedure should also be used to start the system in external timing mode. To summarize, from Matt:
- Tried procmgr start internal-neh-base.cnf but found errors
- fru_deactivate/activate
- procmgr start internal-neh-base.cnf worked
- changed CuInput 0 -> 1 in xpmpva
- procmgr stopall internal-neh-base.cnf
- procmgr start neh-base.cnf
Coupled Deadtime Behavior
Matt has implemented "coupled" readout-group dead time behavior on the XPMs (can be enabled/disabled with register settings). This behavior is done this way to ensure that Ric's TEB is always guaranteed to get a highest-rate readout group in every event, which dramatically simplifies his TEB system design. The trigger decision ("Tr") works like this for 3 readout groups, highlighting the cases when (a) the highest-rate readout group is full and (b) one of the lower rate readout groups is full, both when that group wants to readout and doesn't want to readout.
| Code Block |
|---|
1 RRRRRRRRFRRR
2 R R FfR R
3 R R R
Tr TTTTtTTTDTTT
Time goes to the right
1-3: readout groups
Tr: the trigger decision
R = Readout group can readout
F = Readout group is full and wants to readout
f = Readout group is full but doesn't want to readout
T = Trigger all readout groups that want to readout
t = Trigger subset of readout groups that are not full
D = No trigger generated (Dead) |
This behavior is accomplished in the current XPM implementation by setting the following (child group) PVS : $master:PART:2:L0Groups = (1<<$parent), $master:PART:3:L0Groups = (1<<$parent), $master is XPM:NEH:XPM:2 and $parent is group 1 for instance. This can be done in control.py or Timing segment level.
Update: Support for the above was added to control.py and pushed to the git repo on 3/10/22
...
For now (09/20/21) this procedure should also be used to start the system in external timing mode. To summarize, from Matt:
...
Transition Deadtime
The XPM may be instructed to require a transition to obey deadtime by including bit 7 (OR 1<<7) when writing to the "MsgHeader" PV. Ordinarily, just the TransitionId is written to this PV.
...
The application should be run on a DRP node like drp-neh-cmp002. Address 239.255.25.0 is SXR EBEAM and port 10148 is the standard port for NC BLD sources. The addresses for other BLD sources is found in the table below.
| Source | Address/Group | Port |
|---|---|---|
| SXR EBEAM | 239.255.25.0 | 10148 |
| SXR PCAV | 239.255.25.1 | 10148 |
| SXR GMD | 239.255.25.2 | 10148 |
| SXR XGMD | 239.255.25.3 | 10148 |
| HXR EBEAM | 239.255.24.0 | 10148 |
| HXR PCAV | 239.255.24.1 | 10148 |
| HXR GDET | 239.255.24.2 | 10148 |
Note that the EBEAM BLD is a concatenation of several data sources. As such, there may be problems with one of the sources that contributes. That is evident in the "damageMask" field of the EBEAM BLD. This can be seen in AMI or for extreme experts in the raw dump of the multicast reception (argument -d of xcasttest).
A common problem in the EBEAM BLD source is that the L3Energy calculation often fails after the accelerator changes beam energy and does not update their internal alarm limits to the calculation.
...
Overview
Content Tools